JSON Iteration
DATA_ACCESS section defines the basic parameters for data access and iteration of the NM substances. The EDLs set iteration the mode through attribute ITERATION. NMDataParser supports several modes of iteration summarized in the following table:
| Iteration mode | Description |
|---|---|
| ROW_SINGLE | Data is accessed treating each excel table row as a separate Substance record |
| ROW_MULTI_FIXED | A fixed number of rows are treated as a separate Substance record |
| ROW_MULTI_DYNAMIC | A dynamic number of rows are used to load a Substance record (the number of rows may vary for each record) |
| ABSOLUTE_LOCATION | The data component is read from an absolute location within the excel file (sheet, row and column must be defined) |
| JSON_VALUE | Data component is taken directly from the JSON configuration file |
| VARIABLE | Data component is taken directly from the list of variables loaded |
| SUBSTANCE_RECORD_MAP | Substance record list is defined via a mechanism using variables. This mode is used for mapping complicated effect blocks to a predefined lists of substances |
For the most of the iteration modes there is a primary sheet used to define the logic of reading (iterating) the substances from the excel sheet. DATA_ACCESS section describes the basic approach for reading data and these are the default reading parameters (i.e. they may be omitted using short JSON syntax). When particular attribute in EDL is omitted, the default value is taken from DATA_ACCESS section as well as the explicitly set attribute in a EDL overwrites the default value given in DATA_ACCESS section. Most often, the default values of the fields ITERATION and SHEET_INDEX (when not supplied explicitly) are taken globally from the DATA_ACCESS.
Iteration modes ABSOLUTE_LOCATION, JSON_VALUE and VARIABLE are not used globally in the DATA_ACCESS section, but are locally used in many EDLs for particular eNanoMapper data model components (in these cases overwriting the globally set iteration mode e.g. ROW_SINGLE or something else). For example, in ROW_SINGLE mode, an EDL will require only column index, while in ABSOLUTE_LOCATION mode, all of the indices will be used: COLUMN_INDEX, ROW_INDEX and SHEET_INDEX. SHEET_INDEX could be omitted when a cell from the primary excel sheet is accessed while the ABSOLUTE_LOCATION allows getting an excel data from anywhere including another excel sheet different that the primary one. The primary excel sheet (set in DATA_ACCESS section) is the one that defines the logic of iteration i.e. how the substances are recognized in order within spreadsheet data organization.
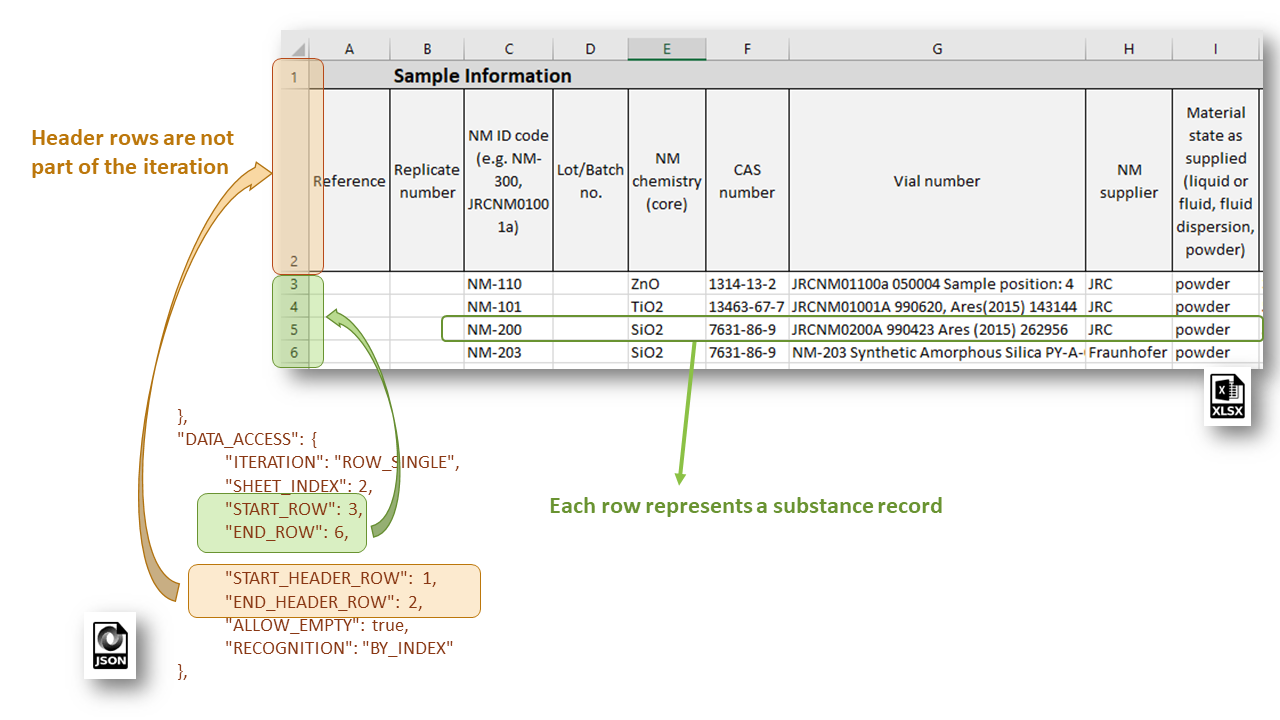
ROW_SINGLE mode is predominantly used mode for the NSC templates (see figure below). The excel sheet data is accessed treating each table row as a separate Substance record. The logic of data organization on column basis of the substance data components, is quite appealing and preferred in many cases (in sections 3 and 4 we discuss also the drawbacks of this approach). The header rows are not part of the iteration but data can be accessed with an EDL in iteration mode ABSOLUTE_LOCATION.
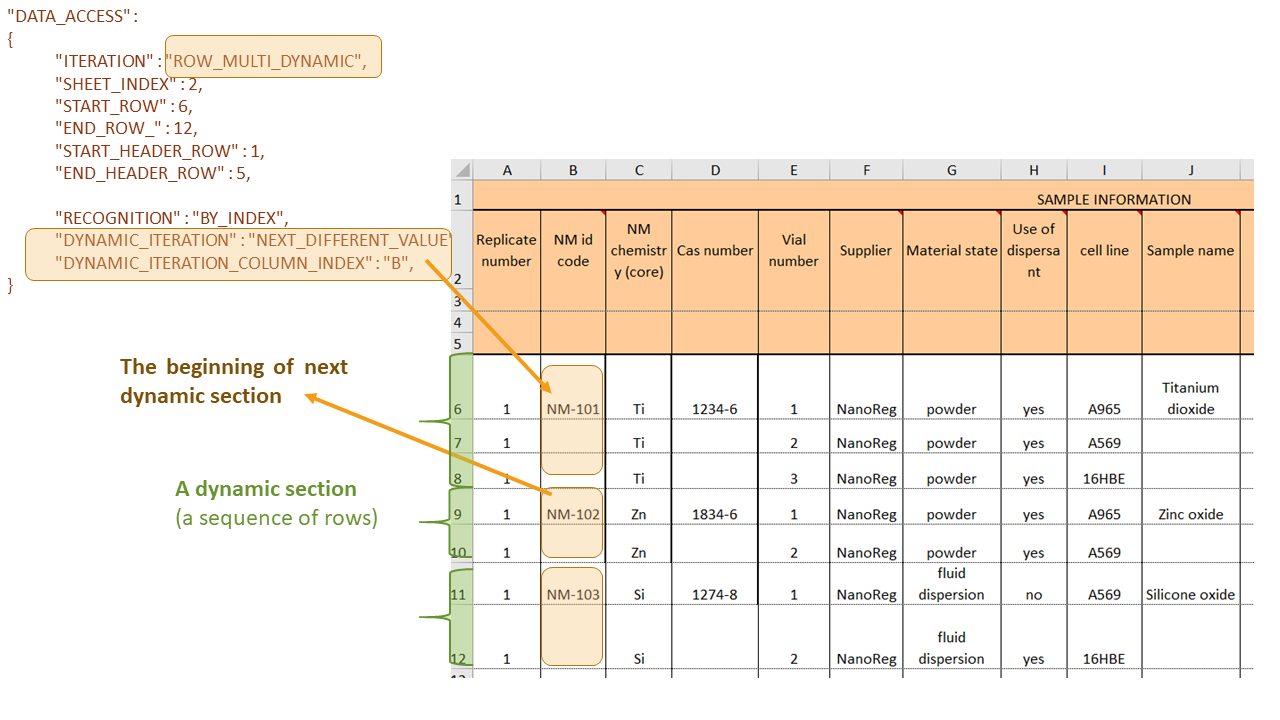
In iteration mode ROW_MULTI_DYNAMIC, a dynamic number of rows are used to load a Substance record and the number of rows may vary for each record. JSON field DYNAMIC_ITERATION defines how dynamic iteration is performed in mode i.e. how the end of the dynamic group of rows is recognized. Two possible criterions for row group recognition are implemented: NEXT_NOT_EMPTY or NEXT_DIFFERENT_VALUE where attribute DYNAMIC_ITERATION_COLUMN_INDEX defines the column used for dynamic iteration recognition. In iteration mode ROW_MULTI_FIXED, a fixed number of rows are used to load a Substance record.
The dynamic modes are intended for loading Effect Blocks defined within the loaded set of rows (dynamic or fixed number). For example complex HTS Excel files can be configured in this manner (see section Effect Blocks II (advanced)). The SUBSTANCE_RECORD and EFFECTS sections are using only the first row of the loaded dynamic (or fixed) list of rows (i.e. these sections are treated as if in mode ROW_SINGLE).
If Effect Blocks are not needed Substance Records nevertheless spans more than one Excel row then ROW_SINGLE mode is still used with a special option on the database import to merge the data for all substances with the same UUID. This case is quite common for JRC templates. When there are several rows for a set of measurements (replicas) of the same endpoint under different experimental conditions. These template how ever includes lots of redundancy e.g. repeating the Protocol Application parameters and Subtsances IDs and names. Exactly the repeating Substance names (configured as UUIDs) are used in mode ROW_SINGLE to merge several rows into a single Substance Record.