JSON EffectBlocks Advanced
Effect blocks define several levels of aggregation (data structuring):
- blocks
- sub-blocks
- value groups
- parameters (i.e. experimental conditions) associated to the each value
Effect Blocks are divided into a rectangular grid of sub-blocks. Within each sub-block a set of value groups can be defined. In a particular sub-block, each element of the VALUE_GROUPS array describes the experimental values for a separate endpoint measurement packed with a set of experimental conditions. Each value from the value group is imported into the data base together with a separate combination of experimental conditions (see figure below).
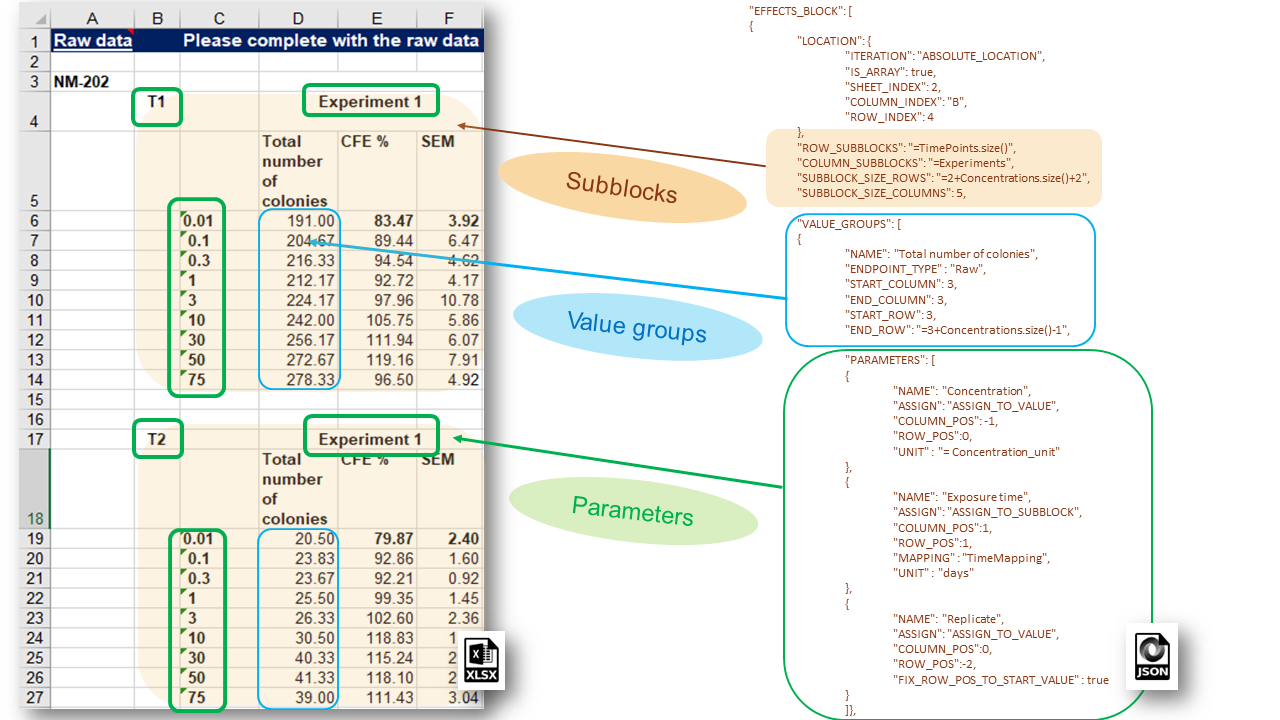
The effects block is placed in a particular element of the PROTOCOL_APPLICATIONS[] JSON array. Therefore the protocol application parameters for each experimental value are the same for entire effect block (i.e. for each value in each value group in each sub-block). However the experimental conditions for each value are varying according to the definition of the VALUE_GROUP parameters (should not be confused with the parameters of the Protocol Application).
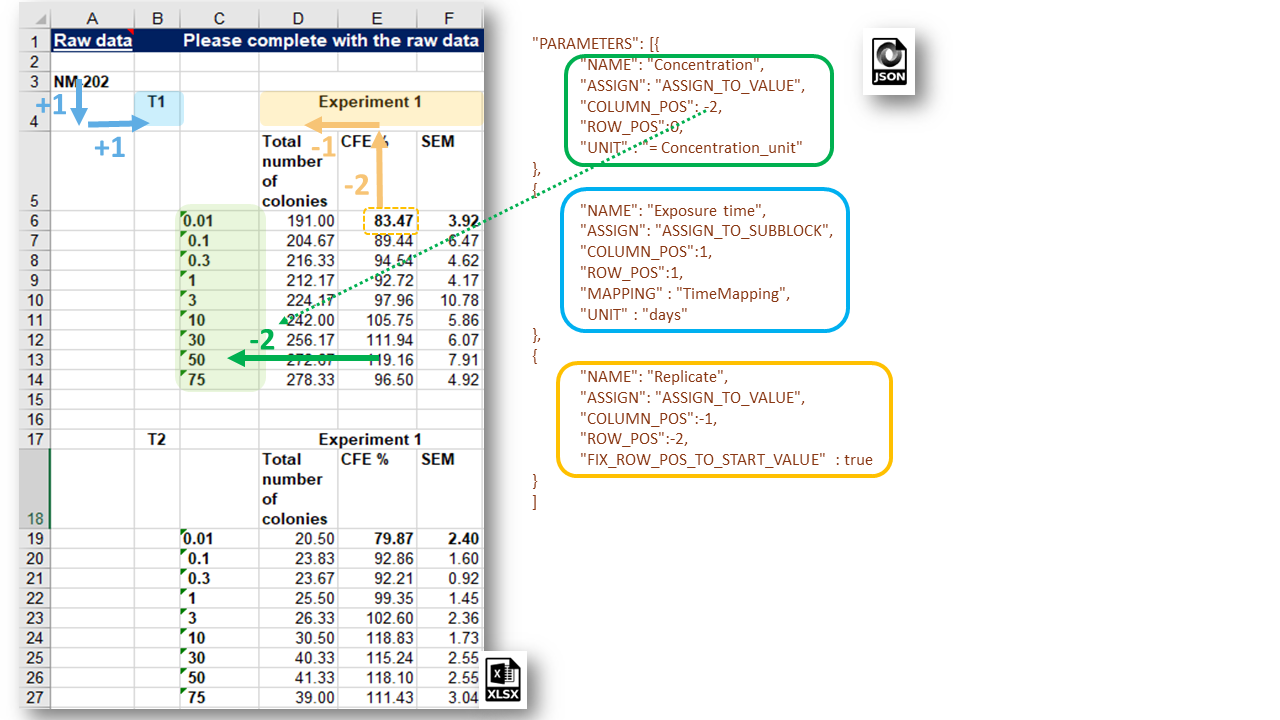
Figure below demonstrates variability of parameter assigning. Concentrations are spanned in parallel with the measurement values, hence ASSIGN_TO_VALUE mode is applied. Exposure time is the same for the entire sub-block, hence ASSIGN_TO_SUBBLOCK mode is used. If needed, additional Boolean attributes FIX_ROW_POS_TO_START_VALUE and FIX_COLUMN_POS_TO_START_VALUE can be used to fix one of the dimensions (columns or rows) to the beginning cell of the value group as it is done for the “Replicate” condition from the example shown in Figure 13.
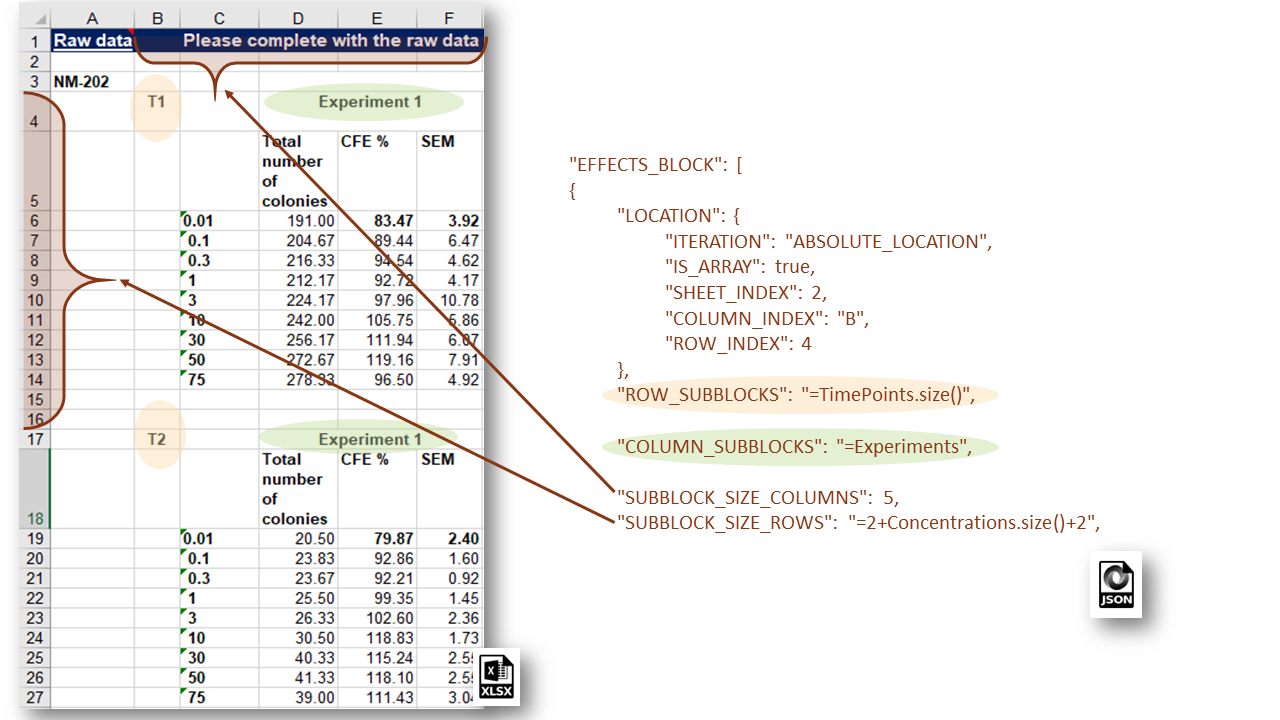
The NMDataParser supports expressions with predefined variables to allow a more flexible definition of the blocks, sub-blocks and value groups. For example, SUBBLOCK_SIZE_ROWS attribute (the vertical size of each sub-block) is equal to 4 + number of concentrations used in the CFE assay.
The following expression is used: 2 + Concentrations.size() + 2 i.e. count 2 rows above and 2 rows beneath the main group of measurements spanning all concentration values: 0.01, 0.1, 0.3 ,…,75 ug/cm2.
Hard coding the block and sub-block sizes is always an option (e.g. use directly 13 instead of “=2 + Concentrations.size() + 2”) but expressions usage gives more flexibility and allows reuse of same JSON configuration for parsing multiple Excel files. For instance, CFE experiments with different sets of exposure times, replicates and concentrations will be parsed with the same JSON if expressions are used.
Following table summarizes the fields needed for configuration of a value group.
| JSON attribute | meaning |
|---|---|
| NAME | the name of the values (typically used to define the endpoint) |
| ENDPOINT_TYPE | the type of the endpoint (describes how the value is obtained, e.g. average, row, etc.) |
| UNIT | the measurement unit |
| START_COLUMN | the start column of the value group |
| END_COLUMN | the end column of the value group |
| START_ROW | the start row of the value group |
| END_ROW | the end row of the value group |
The EDLs for value groups parameters (i.e. the experimental conditions) and some other effect blocks attributes use four different types of Excel data addressing called “assigning” defined be the attributes COLUMN_POS and ROW_POS. Basically the assigning defines what element of the effect block will be used as a starting point for the “coordinate system” used for relative addressing (i.e. defined the context for COLUMN_POS and ROW_POS) within the Excel sheet. The supported assigning types are:
- ASSIGN_TO_EXCEL_SHEET – parameter location is an address defined in the manner of basic EDL i.e. in terms of Excel sheets indices, column indices and row indices;
- ASSIGN_TO_VALUE - parameter location is defined as relative shifts to the current individual value from the value group.
- ASSIGN_TO_SUBBLOCK - parameter location is defined as relative shifts to the beginning the current sub-block.
- ASSIGN_TO_BLOCK – parameter location is defined as relative shifts to the beginning of the block.
Most often the value group spans a single column (or single row) as shown in the examples below. However, it is possible to handle even more complex cases where a given value group spans a block of Excel cells containing more than one column/row and describes several different endpoints within the same Protocol Application. Figure below illustrates the relative addressing of the position of the error values for a value group of measurements of the CFE assay. The value group is defined in the fourth column of the sub-block (START_COLUMN = END_COLUMN = 4) while the error values are placed in the column left to the values i.e. ERROR_COLUMN_SHIFT = 1 and ERROR_ROW_SHIFT = 0 (is omitted in this case since it is the default value 0). The error shifts are always defined in assigning mode ASSIGN_TO_VALUE.
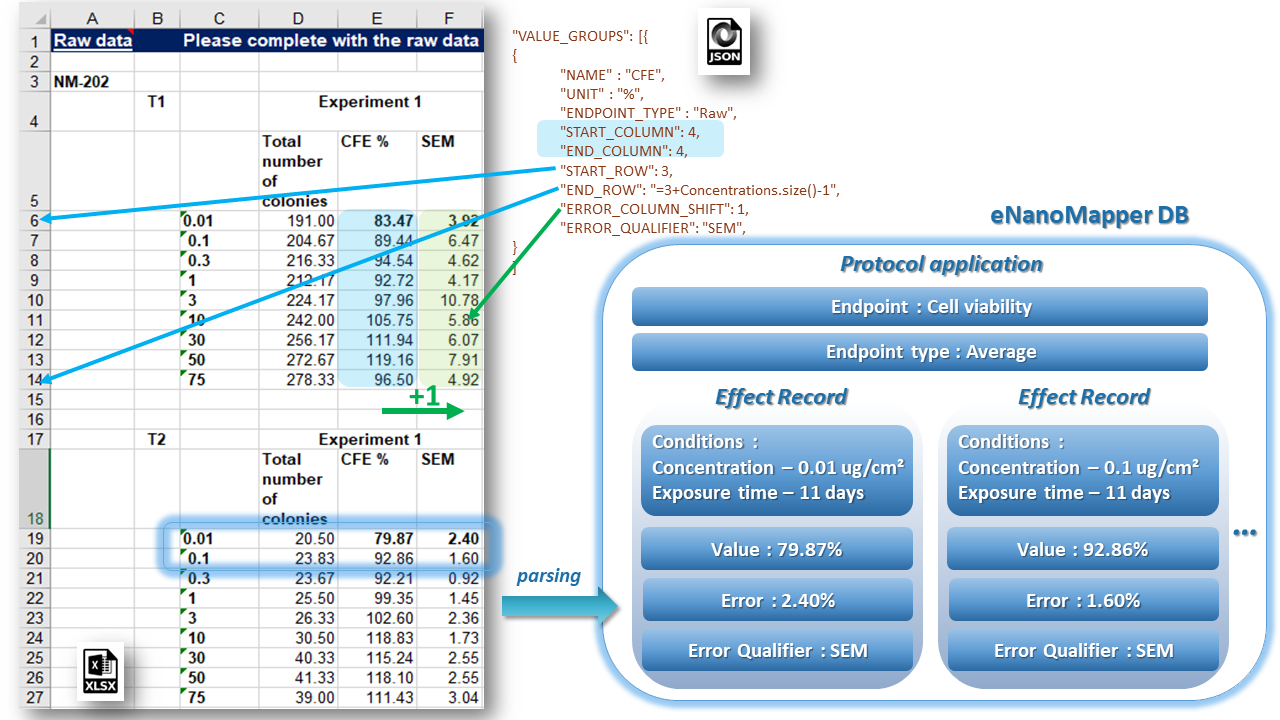
Figure below demonstrates variability of parameter assigning. Concentrations are spanned in parallel with the measurement values, hence ASSIGN_TO_VALUE mode is applied. Exposure time is the same for the entire sub-block, hence ASSIGN_TO_SUBBLOCK mode is used. If needed, additional Boolean attributes FIX_ROW_POS_TO_START_VALUE and FIX_COLUMN_POS_TO_START_VALUE can be used to fix one of the dimensions (columns or rows) to the beginning cell of the value group as it is done for the “Replicate” condition from the example shown below.