NEXT basics
NEXT has a couple components:
- a web server to connect humans with ML applications
- For each ML application, different algorithms
The basics of the web server running NEXT:
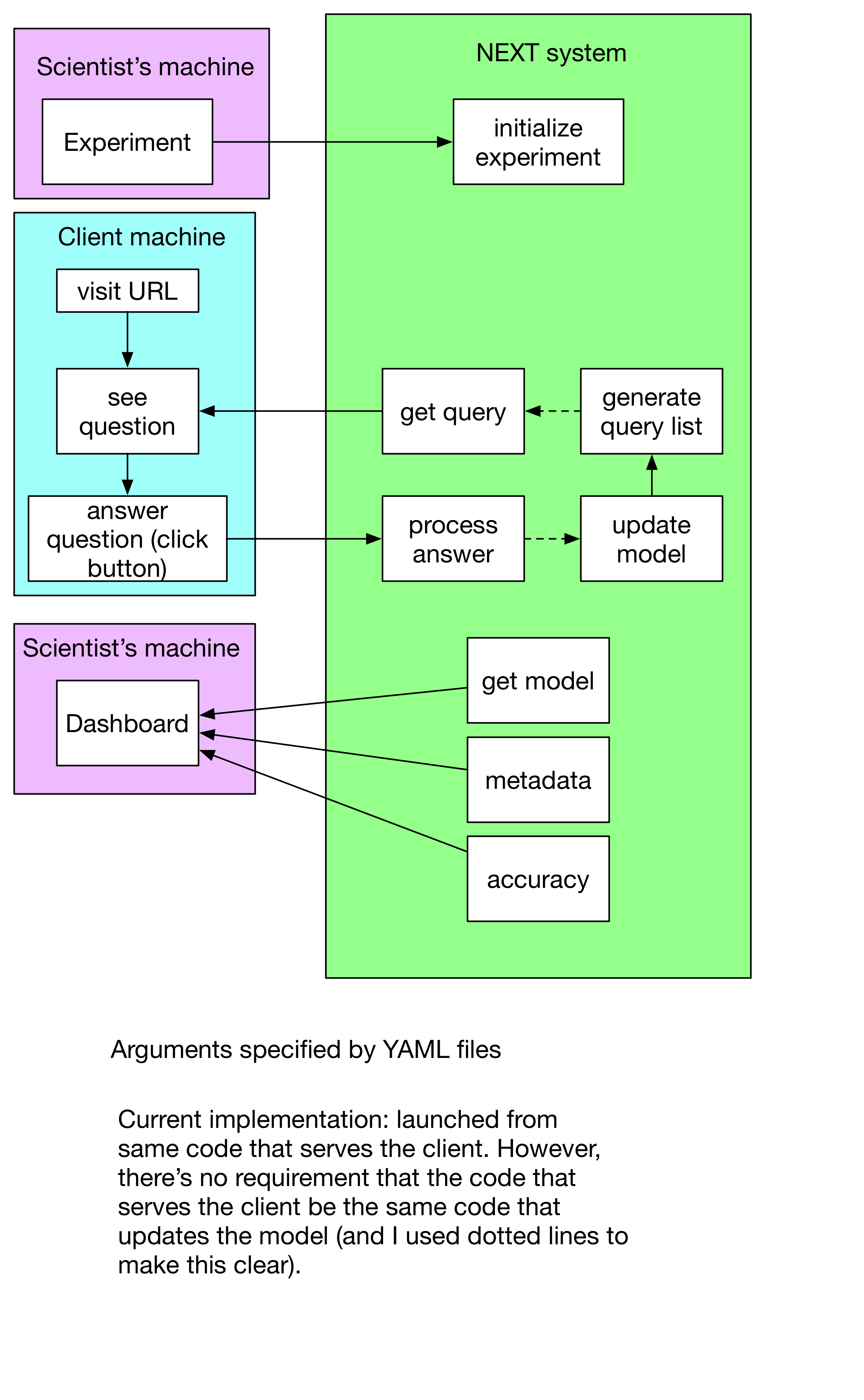
A more specific data flow (and also more details on arguments) can be found in Arguments.
It is critical that the client be served up-to-date queries -- that's the whole point of NEXT. It has to do with active learning, which requires that the queries the user answers are up to date (otherwise, there would be no gain from NEXT).
This web server will have to provide some persistent data access, likely via some database system (currently MongoDB).
Each ML application is a different question type (and is poorly named). The three applications we support by default are
- Cardinal bandits: ask for a rating on one item
- Dueling bandits: ask for the better of two items
- Triplets: ask for about three items "is A more like B or C?"
Every application has different algorithms to choose queries/ update the model (though most of an algorithm is an choosing queries)
Most algorithms have the same input and return similar (though slightly different outputs).
A brief description of how the arguments and the 4 key functions for active learning are specified in
- Basic-Algorithms
- Framework-Apps
- Arguments again, with a more detailed dataflow that points out specifics
It is most natural to implement these algorithms as classes:
class MyAlg:
def __init__(self, num_arms, features_per_arm):
self.X = np.random.randn(num_arms, features_per_arm)
self.responses = []
def get_query(self):
return informative_triplet(self.X)
def process_answer(self, ans):
self.responses += [ans]
self.X = update_model(self.responses, self.X)
def get_model(self):
return self.XWe can't do this in the current implementation, and have provided
a database wrapper called butler to help with this (so our
applications/algorithms are classes but are reinitialized every
time they're used).
This is how most active algorithms are formulated: they assume the computation is infinitely fast, which may not be true in a web service. I want to perserve this, but it'd be nice to have a cleaner separatation of client serving and model updating.
- a server that supports the API above
- with semantic separation between serving queries and updating model (e.g., if queries expensive to generate and no visitors for a long time, NEXT should spend more time generating queries)
- Supports argument and return verification
- a server dashbord that supports
- system level information (client time per call)
- system level information (CPU, memory, etc)
- (custom) meta information (application/algorithm specific)
- to show current model (application specific)
- a couple applications, each with
- a couple algorithms to choose queries
- HTML templates to ask different types of questions
- basic tests
- HTML templates to support viewing custom data
In the server, we need argument verification, both from
- client <=> application
- application <=> algorithm
The application and algorithm have their arguments specified by a YAML file.
We want a way to log custom information in the application and algorithm, and have a nice way to see these on the dashboard.