
Transfer Learning has achieved state-of-the-art results recently in Machine Learning and specially, Natural Language Processing tasks. However, for low resource corporas where there is a lack of pre-trained model checkpoints available. We propose Joint Learn which leverages task specific weight-sharing for training multiple sequence classification tasks simulataneously and has empirically showed resulting in more generalizable models. Joint Learn is a PyTorch based comprehensive toolkit for weight-sharing in text classification settings.
| Joint Learn LSTM Self Attention | Joint Learn Transformer LSTM Self Attention |
|---|---|
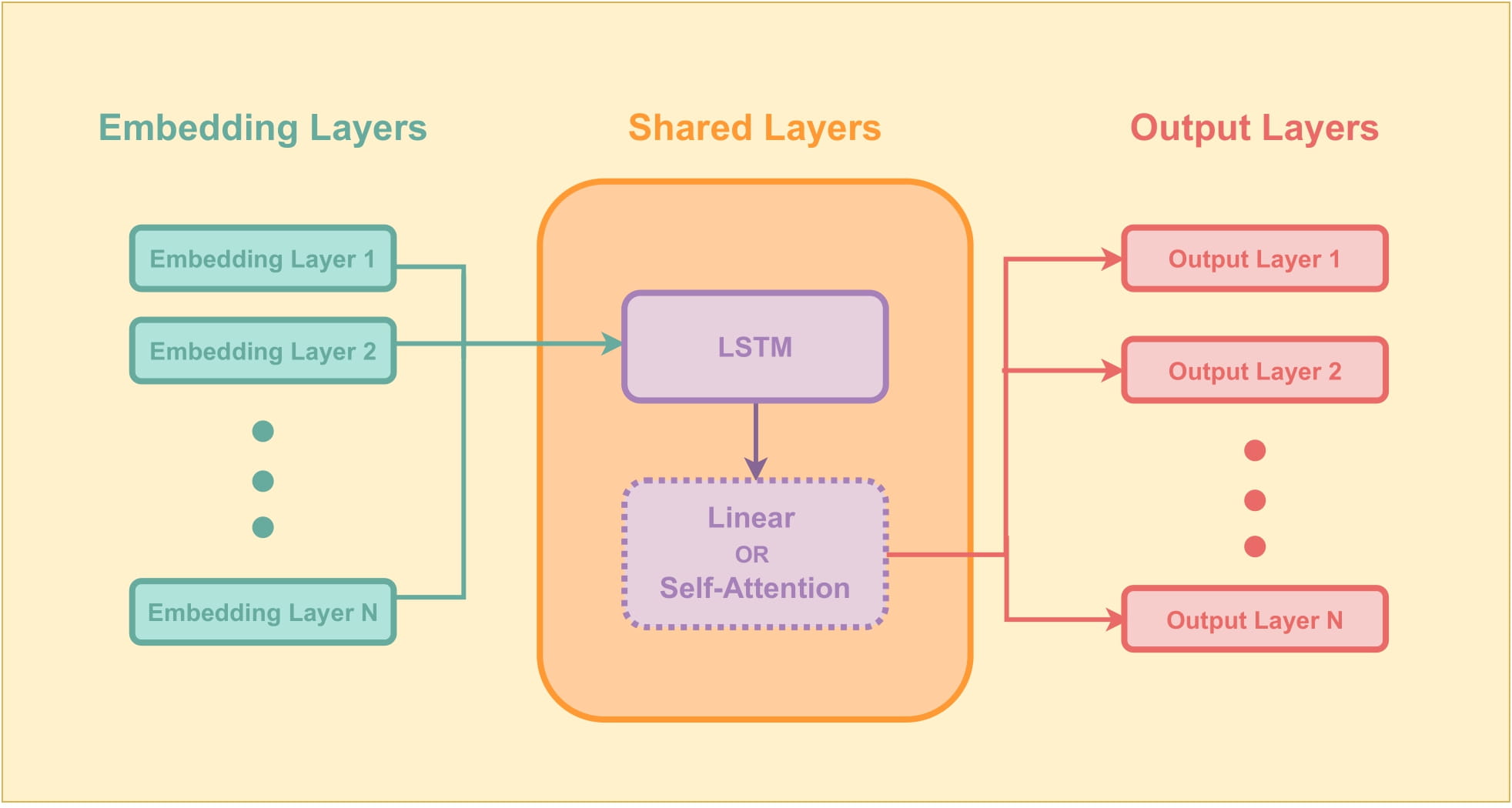 |
## init jl lstm
jl_lstm = JLLSTMClassifier(
batch_size=batch_size,
hidden_size=hidden_size,
lstm_layers=lstm_layers,
embedding_size=embedding_size,
dataset_hyperparams=dataset_hyperparams,
device=device,
)
## define optimizer and loss function
optimizer = torch.optim.Adam(params=jl_lstm.parameters())
train_model(
model=jl_lstm,
optimizer=optimizer,
dataloaders=jl_dataloaders,
max_epochs=max_epochs,
config_dict={"device": device, "model_name": "jl_lstm"},
) ## init jl transformer lstm
jl_lstm = JLLSTMTransformerClassifier(
batch_size=batch_size,
hidden_size=hidden_size,
lstm_layers=lstm_layers,
embedding_size=embedding_size,
nhead=nhead,
transformer_hidden_size=transformer_hidden_size,
transformer_layers=transformer_layers,
dataset_hyperparams=dataset_hyperparams,
device=device,
max_seq_length=max_seq_length,
)
## define optimizer and loss function
optimizer = torch.optim.Adam(params=jl_lstm.parameters())
train_model(
model=jl_lstm,
optimizer=optimizer,
dataloaders=jl_dataloaders,
max_epochs=max_epochs,
config_dict={"device": device, "model_name": "jl_lstm"},
) ## init jl lstm self-attention
jl_lstm = JLLSTMAttentionClassifier(
batch_size=batch_size,
hidden_size=hidden_size,
lstm_layers=lstm_layers,
embedding_size=embedding_size,
dataset_hyperparams=dataset_hyperparams,
bidirectional=bidirectional,
fc_hidden_size=fc_hidden_size,
self_attention_config=self_attention_config,
device=device,
)
## define optimizer and loss function
optimizer = torch.optim.Adam(params=jl_lstm.parameters())
train_model(
model=jl_lstm,
optimizer=optimizer,
dataloaders=jl_dataloaders,
max_epochs=max_epochs,
config_dict={
"device": device,
"model_name": "jl_lstm_attention",
"self_attention_config": self_attention_config,
},
) ## init jl lstm Self-Attention with Transformer Encoder
jl_lstm = JLLSTMTransformerAttentionClassifier(
batch_size=batch_size,
hidden_size=hidden_size,
lstm_layers=lstm_layers,
embedding_size=embedding_size,
nhead=nhead,
transformer_hidden_size=transformer_hidden_size,
transformer_layers=transformer_layers,
dataset_hyperparams=dataset_hyperparams,
bidirectional=bidirectional,
fc_hidden_size=fc_hidden_size,
self_attention_config=self_attention_config,
device=device,
max_seq_length=max_seq_length,
)If you find this repository helpful, feel free to cite our publication Hindi/Bengali Sentiment Analysis Using Transfer Learning and Joint Dual Input Learning with Self Attention:
@article{khan2022hindi,
title={Hindi/Bengali Sentiment Analysis Using Transfer Learning and Joint Dual Input Learning with Self Attention},
author={Khan, Shahrukh and Shahid, Mahnoor},
journal={BOHR International Journal of Research on Natural Language Computing (BIJRNLC)},
year={2022}
}