![]()
Blazingly fast1 Vulkan glTF viewer.

- Support glTF 2.0, including:
- PBR material rendering with runtime IBL resources (spherical harmonics + pre-filtered environment map) generation from input equirectangular map.
- Runtime missing tangent attribute generation using MikkTSpace algorithm for indexed primitive.
- Runtime missing per-face normal and tangent attribute generation using tessellation shader (if supported) or screen-space fragment shader for non-indexed primitive.
- Unlimited
TEXCOORD_<i>attributes: can render a primitive that has arbitrary number of texture coordinates. OPAQUE,MASK(using alpha testing and Alpha To Coverage) andBLEND(using Weighted Blended OIT) materials.- Multiple scenes.
- Binary format (
.glb).
- Support glTF 2.0 extensions:
KHR_materials_unlitfor lighting independent material shadingKHR_texture_basisufor BC7 GPU compression texture decodingEXT_mesh_gpu_instancingfor instancing multiple meshes with the same geometry
- Use 4x MSAA by default.
- Support HDR and EXR skybox.
- File loading using platform-native file dialog.
- Pixel perfect node selection and transformation using ImGuizmo.
- Arbitrary sized outline rendering using Jump Flooding Algorithm.
- Conditionally render a node with three-state visibility in scene hierarchy tree.
- GUI for used asset resources (buffers, images, samplers, etc.) list with docking support.
Followings are not supported:
- Primitive Type except for
TRIANGLES. - Animation.
- Normalized/Sparse accessors.
Click the below image will redirect the page to the YouTube video (due to the GitHub's policy, I cannot directly embed the video into markdown).
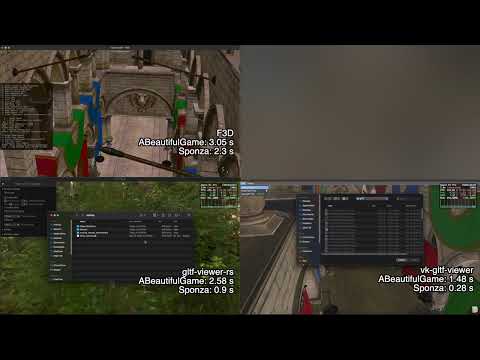
See Performance Comparison page for the performance comparison with other desktop glTF viewers.
I initially developed this application for leveraging Vulkan's performance and using some modern GPU features, like bindless/GPU driven rendering/etc. There are two main goals for this application: speed and memory consumption. Here are some key points:
- Fully bindless: no descriptor set update/vertex buffer binding during rendering.
- Descriptor sets are only updated at the model loading time.
- Textures are accessed with runtime-descriptor indexing using
VK_EXT_descriptor_indexingextension. - Use Vertex Pulling with
VK_KHR_buffer_device_address. Only index buffers are bound to the command buffer.
- Fully GPU driven rendering: uses both instancing and multi draw indirect with optimally sorted rendering order. Regardless of the material count and scene's complexity, all scene nodes can be rendered with up to 24 draw calls in the worst case2.
- Has 6 pipelines for 3 material types (
OPAQUE,MASK,BLEND) and 2 primitive types (Indexed, Non-Indexed) combinations. - Indexed primitive index type can be either
UNSIGNED_BYTE(if GPU supportsVK_EXT_index_type_uint8),UNSIGNED_SHORTorUNSIGNED_INT, and each type requires a single draw call. - Each material can be either double-sided or not, and cull mode have to be set based on this.
- Therefore, if scene consists of the primitives of all combinations, it requires 24 draw calls. Of course, it would be ~6 draw calls in most case.
- Has 6 pipelines for 3 material types (
- Significant less asset loading time: glTF buffer memories are directly
memcpyed into the GPU memory with dedicated transfer queue. No pre-processing is required!- Thanks to the vertex pulling, pipeline is vertex input state agnostic, therefore no pre-processing is required.
- Also, it considers whether the GPU is UMA (unified memory architecture) or not, and use the optimal way to transfer the buffer data.
- For downside, it does not support normalized texture coordinate accessors and sparse accessors.
- Asynchronous IBL resources generation using only compute shader: cubemap generation (including mipmapping), spherical harmonics calculation and prefiltered map generation are done in compute shader, which can be done with the graphics operation in parallel.
- Use subgroup operation to directly generate 5 mipmaps in a single dispatch with L2 cache friendly way (if you're wondering about this, here's my repository which explains the method in detail).
- Use subgroup operation to reduce the spherical harmonics.
- Multithreaded image decoding and MikkTSpace tangent attribute generation.
- Used frames in flight to stabilize the FPS.
- Primary rendering pass is done with multiple subpasses, which makes most of the used attachment images memoryless. If your GPU is tile based, only jump flood images and swapchain images would be existed in the physical memory.
- Use explicit queue family ownership transfer and avoid
VK_IMAGE_USAGE_STORAGE_BITflags for the images, which can enable the Delta Color Compression (DCC) in the AMD GPUs (I've not tested this in an AMD GPUs). - As mentioned in above, direct copying the buffer data can reduce the memory footprint during the loading time.
- After IBL resource generation, equirectangular map and cubemap image sizes are reduced with pre-color correction. This leads up to ~4x smaller GPU memory usage if you're using higher resolution cubemap.
The extensions and feature used in this application are quite common in the modern desktop GPU drivers, so I hope you don't have any problem with this.
Tip
My primary development environment is Apple M1 Pro, so if you're MoltenVK user, you'll be able to run this application.
Show requirements list
- Vulkan 1.2 or later
- Device Extensions
VK_KHR_dynamic_renderingVK_KHR_synchronization2VK_EXT_extended_dynamic_state(dynamic state cull mode)VK_KHR_swapchain- (optional)
VK_KHR_swapchain_mutable_format(proper ImGui gamma correction, UI color will lose the color if the extension not presented) - (optional)
VK_EXT_index_type_uint8(if not presented, unsigned byte primitive indices will re-generated withuint16_ts)
- Device Features
VkPhysicalDeviceFeaturessamplerAnistropyshaderInt64multiDrawIndirectshaderStorageImageWriteWithoutFormatindependentBlend(Weighted Blended OIT)- (optional)
tessellationShader(if not presented, non-indexed primitive's per-face normal/tangent will be generated in fragment shader)
VkPhysicalDeviceVulkan11FeaturesshaderDrawParameters(usegl_BaseInstancefor primitive index)storageBuffer16BitAccessuniformAndStorageBuffer16BitAccessmultiview(reducing cubemap image precision with color correction)
VkPhysicalDeviceVulkan12FeaturesbufferDeviceAddressdescriptorIndexingdescriptorBindingSampledImageUpdateAfterBinddescriptorBindingStorageImageUpdateAfterBindruntimeDescriptorArraystorageBuffer8BitAccessuniformAndStorageBuffer8BitAccessscalarBlockLayouttimelineSemaphoreshaderInt8- (optional)
drawIndirectCount(If not presented, GPU frustum culling will be unavailable and fallback to the CPU frustum culling.)
VkPhysicalDeviceDynamicRenderingFeaturesVkPhysicalDeviceSynchronization2FeaturesVkPhysicalDeviceExtendedDynamicStateFeaturesEXT- (optional)
VkPhysicalDeviceIndexTypeUint8FeaturesEXT(if not presented, unsigned byte primitive indices will re-generated withuint16_ts)
- Device Limits
- Subgroup size must be at least 16 and 64 at maximum.
- Sampler anisotropy must support 16x.
- Loading asset texture count must be less than
maxDescriptorSetUpdateAfterBindSampledImages - Cubemap size must be less than
2^(maxDescriptorSetUpdateAfterBindStorageImages).
This project requires support for C++20 modules and the C++23 standard library. The supported compilers are:
- Clang 18.1.2
- MSVC 19.42
The following build tools are required:
- CMake 3.30
- Ninja 1.11
Additionally, you need vcpkg for dependency management. Make sure VCPKG_ROOT environment variable is defined as your vcpkg source directory path!
This project depends on:
- boost-container
- CGAL (due to its usage, this project is licensed under GPL.)
- fastgltf
- GLFW
- glm
- ImGui
- ImGuizmo
- KTX-Software
- MikkTSpace
- Native File Dialog Extended
- OpenEXR
- stb_image
- My own Vulkan-Hpp helper library, vku (branch
module), which has the following dependencies:
Dependencies will be automatically fetched via vcpkg.
Tip
This project uses GitHub Runner to ensure build compatibility on Windows (with MSVC), macOS and Linux (with Clang), with dependency management handled by vcpkg. You can check the workflow files in the .github/workflows folder.
First, you have to clone the repository.
git clone https://github.com/stripe2933/vk-gltf-viewer
cd vk-gltf-viewerThe CMake preset is given by default.
cmake --preset=default
cmake --build build -t vk-gltf-viewerThe executable will be located in build folder.
Install libc++ and extra build dependencies from apt.
sudo apt install libc++-dev libc++abi-dev xorg-dev libtool libltdl-devAdd the following CMake user preset file in your project directory. I'll assume your Clang compiler executable is at /usr/bin/.
CMakeUserPresets.json
{
"version": 6,
"configurePresets": [
{
"name": "linux-clang-18",
"inherits": "default",
"cacheVariables": {
"CMAKE_C_COMPILER": "/usr/bin/clang-18",
"CMAKE_CXX_COMPILER": "/usr/bin/clang++-18",
"CMAKE_CXX_FLAGS": "-stdlib=libc++",
"CMAKE_EXE_LINKER_FLAGS": "-stdlib=libc++ -lc++abi",
"VCPKG_OVERLAY_TRIPLETS": "${sourceDir}/triplets",
"VCPKG_TARGET_TRIPLET": "x64-linux-clang"
}
}
]
}VCPKG_OVERLAY_TRIPLETS and VCPKG_TARGET_TRIPLET configuration parameters are mandatory for make vcpkg uses Clang compiler instead of the system default compiler. Add following vcpkg toolchain and triplet files.
clang-toolchain.cmake
set(CMAKE_C_COMPILER /usr/bin/clang-18)
set(CMAKE_CXX_COMPILER /usr/bin/clang++-18)
set(CMAKE_CXX_FLAGS "-stdlib=libc++")
set(CMAKE_EXE_LINKER_FLAGS "-stdlib=libc++ -lc++abi")triplets/x64-linux-clang.cmake
set(VCPKG_TARGET_ARCHITECTURE x64)
set(VCPKG_CRT_LINKAGE dynamic)
set(VCPKG_LIBRARY_LINKAGE static)
set(VCPKG_CMAKE_SYSTEM_NAME Linux)
set(VCPKG_CHAINLOAD_TOOLCHAIN_FILE ${CMAKE_CURRENT_LIST_DIR}/../clang-toolchain.cmake)Configure and build the project with linux-clang-18 configuration preset.
cmake --preset=linux-clang-18
cmake --build build -t vk-gltf-viewerThe executable will be located in build folder.
Install extra build dependencies from homebrew.
brew install autoconf automake libtool nasmAdd the following CMake user preset file in your project directory. I'll assume your Clang compiler executable is at /opt/homebrew/opt/llvm/bin/.
CMakeUserPresets.json
{
"version": 6,
"configurePresets": [
{
"name": "macos-clang",
"inherits": "default",
"cacheVariables": {
"CMAKE_C_COMPILER": "/opt/homebrew/opt/llvm/bin/clang",
"CMAKE_CXX_COMPILER": "/opt/homebrew/opt/llvm/bin/clang++",
"CMAKE_CXX_FLAGS": "-nostdinc++ -nostdlib++ -isystem /opt/homebrew/opt/llvm/include/c++/v1",
"CMAKE_EXE_LINKER_FLAGS": "-L /opt/homebrew/opt/llvm/lib/c++ -Wl,-rpath,/opt/homebrew/opt/llvm/lib/c++ -lc++",
"VCPKG_OVERLAY_TRIPLETS": "${sourceDir}/triplets",
"VCPKG_TARGET_TRIPLET": "arm64-macos-clang"
}
}
]
}VCPKG_OVERLAY_TRIPLETS and VCPKG_TARGET_TRIPLET configuration parameters are mandatory for make vcpkg uses Clang compiler instead of the system default compiler. Add following vcpkg toolchain and triplet files.
clang-toolchain.cmake
set(CMAKE_C_COMPILER /opt/homebrew/opt/llvm/bin/clang)
set(CMAKE_CXX_COMPILER /opt/homebrew/opt/llvm/bin/clang++)
set(CMAKE_CXX_FLAGS "-nostdinc++ -nostdlib++ -isystem /opt/homebrew/opt/llvm/include/c++/v1")
set(CMAKE_EXE_LINKER_FLAGS "-L /opt/homebrew/opt/llvm/lib/c++ -Wl,-rpath,/opt/homebrew/opt/llvm/lib/c++ -lc++")triplets/arm64-macos-clang.cmake
set(VCPKG_TARGET_ARCHITECTURE arm64)
set(VCPKG_CRT_LINKAGE dynamic)
set(VCPKG_LIBRARY_LINKAGE static)
set(VCPKG_CMAKE_SYSTEM_NAME Darwin)
set(VCPKG_CHAINLOAD_TOOLCHAIN_FILE ${CMAKE_CURRENT_LIST_DIR}/../clang-toolchain.cmake)Configure and build the project with macos-clang configuration preset.
cmake --preset=macos-clang
cmake --build build -t vk-gltf-viewerThe executable will be located in build folder.
All shaders are located in the shaders folder and will be automatically compiled to SPIR-V format during the CMake configuration time. The result SPIR-V binary files are located in the build/shader folder.
- Basis Universal texture support (
KHR_texture_basisu). - Automatic camera position adjustment based on the bounding sphere calculation.
- Frustum culling
- CPU frustum culling (Note: still experimental; unexpected popped in/out may happened.)
- GPU frustum culling
- Occlusion culling
- Reduce skybox memory usage with BC6H compressed cubemap.
- Animations.
This project is licensed under the GPL-v3 License. See the LICENSE file for details.
Footnotes
-
I like this term because it's hilarious for several reasons, but it's no joke! It has the significantly faster glTF model loading speed than the other the viewers I've tested. See Performance Comparison page for details. ↩
-
Applied for standard glTF 2.0 asset only. Asset with material related extensions may require additional draw calls for pipeline changing. ↩