collector is a script written in Bash, it is intended to automate some tedious tasks of reconnaissance and information gathering.
This tool allows you to gather some information that should help you identify what to do next and where to look.
Recommended to run on vps with 1VCPU and 2GB ram.
To run you need to install some tools and get some API keys.
Lists of API/Web Sites for recon used in the collector:
* alienvault
* binaryedge
* builitwith
* censys
* certspotter
* commoncrawl
* crt.sh
* dnsdb
* dnsdumpster
* hackertarget
* rapiddns
* riskiq
* securitytrails
* threatcrowd
* threatminer
* virustotal
* webarchive
* whoisxmlapi
Lists of tools for recon used in the collector:
* amass
* dnssearch
* gobuster
* nmap
* shodan
* subfinder
Lists of tools for web data function used in the collector:
* aquatone
* chromium
* dirsearch
* git-dumper
* gobuster
* httpx
* nuclei
* wayback
In the future I pretend to use dnsrecon, massdns, sublist3r and others tools to get more subdomains and others information.
But to facility this work I made another script get those tools:
curl -kLOs https://raw.githubusercontent.com/skateforever/pentest-scripts/main/useful/get-tools.sh
chmod +x get-tools.sh
./get-tools.sh -u root -l /opt/pentest/ -p web
You don't need to run the collector or get-tools.sh from root.
If you'll run the collector with another user, you can try run the get-tool.sh like that:
sudo -H ./get-tools.sh -u skate4ever -l /opt/pentest/ -p web
After that, you can configure the collector.cfg and use as below.
This is a little manual to use collector.
By default you have two choices:
1. -u |--url
2. -d |--domains
3. -dl|--domain-list
Using collector with url (-u|--url option)!
When you use the "-u|--url" option, it just need to call the collector:
./collector --url https://domain.com
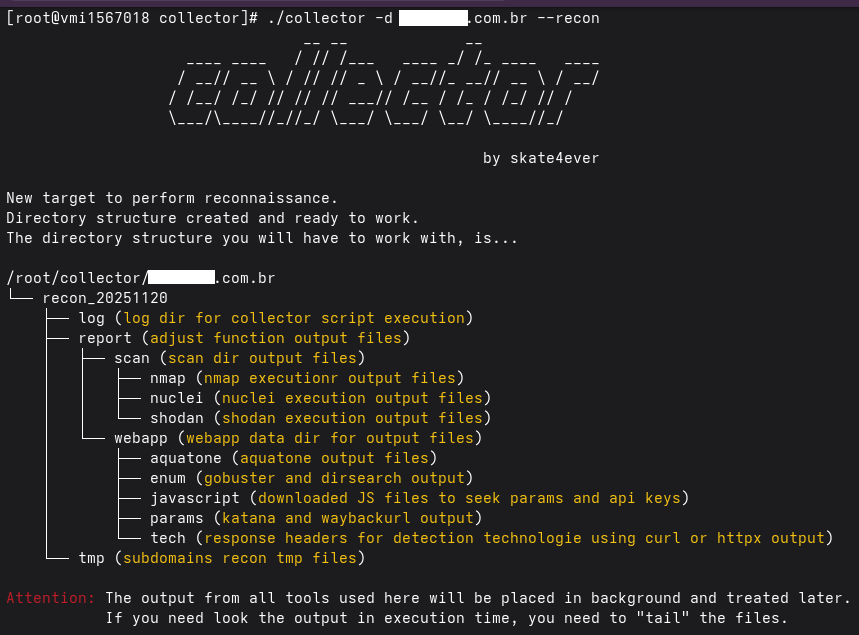
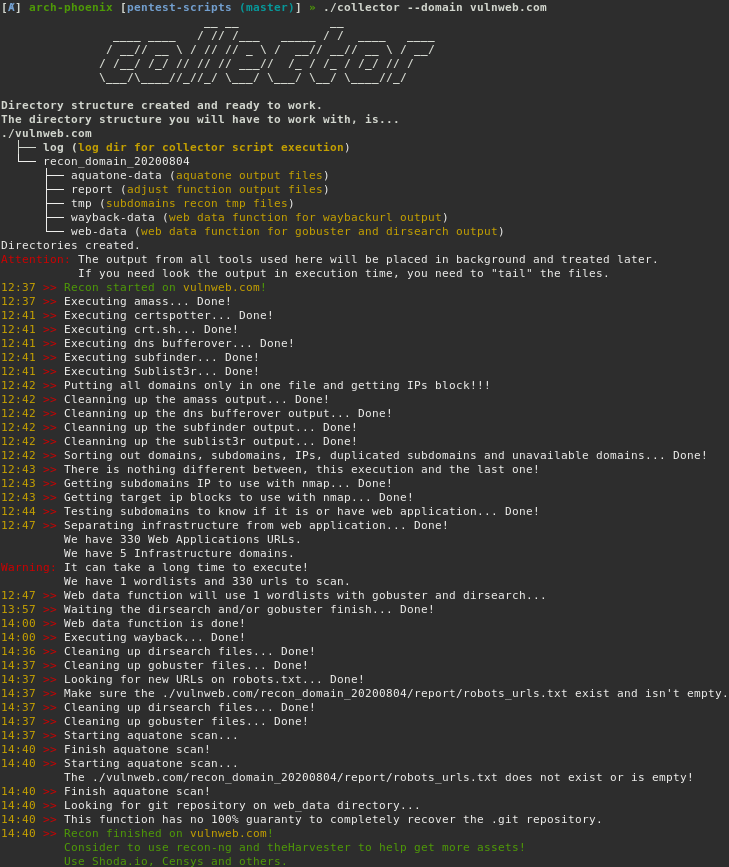
Using collector in default reconnaissance with main domain (-d|--domain or -dl|--domain-list options)!
You will need to inform some few options to get the collector work properly, below I will show you the basics to use the main recon option of collector.
First you NEED to choice what tool you want use to identify web ports are open, two values the option "-wtd|--web-tool-detection" accept:
* curl
* httpx
Second you NEED to inform if the detection will be short (-wsd|--web-short-detection) or long (-wld|--web-long-detection):
* short detection will test only 80, 443, 8080 and 8443 ports
* long detection will test more than hundred ports
Now that you know the important points, the command to perform a simple execution of collector if you put the DNS servers in collector.cfg is:
`./collector --domain domain.com --web-short-detection --web-tool-detection curl`
***OR***
`./collector --domain-list domains.txt --web-short-detection --web-tool-detection curl`
If you decide to use the command line to inform the DNS servers the command will be:
`./collector -d domain.com -ws`
Look at this point, the collector had your execution of recon with some active gathering information trying to determine if a web server/page exist in determinate port beyond to access directories and files in web pages.
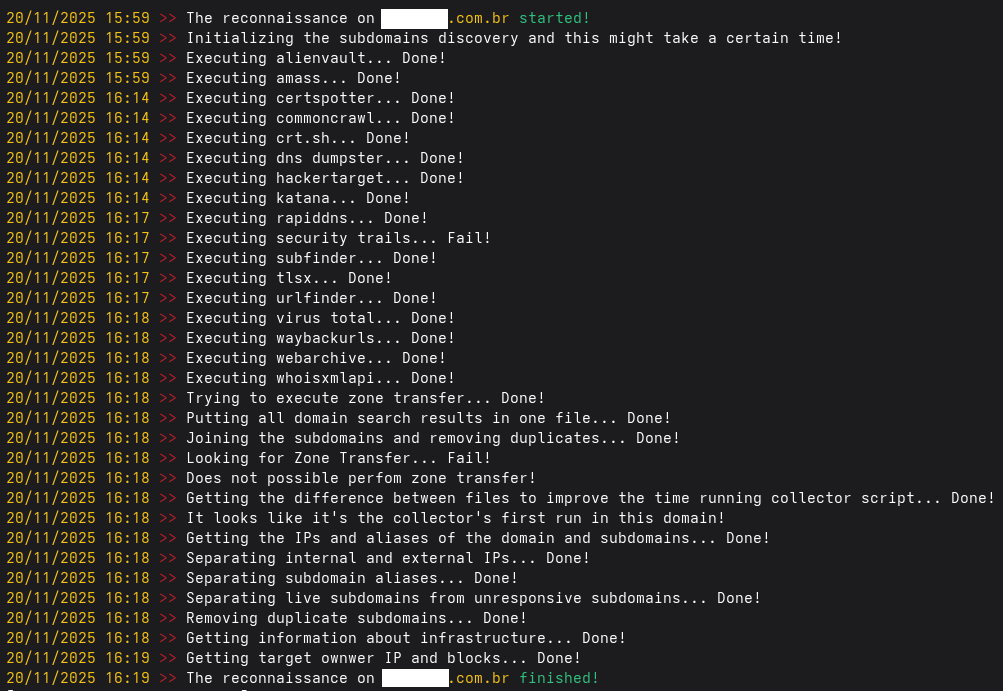
To reduce the amount of traffic generated by set of tools used by collector, you will prefer to use the --recon options.
This options will be execute to determine what is web server/page and stop.
Thus the command to use is (if you have the DNS servers in collector.cfg, see above to know how to use DNS servers with collector):
`./collector --domain domain.com --web-short-detection --web-tool-detection curl --recon`
If you decide to perfom a web data collection after use --recon option, you just need to execute the collector with -w|--web-data option, like this:
`./collector --domain domain.com --web-data`
Now you have the basics funcionality of collector, but if you need or decide to change something on your recon parameters of collector, you can use see the help option:
-d |--domain - Specify a valid domain [needed].
-dl |--domain-list - Specify a valid domain [needed].
-e |--exclude-domains - Specify excluded subdomains after all treated files [used only with -d|--domain]:
use -e domain1.com,domain2.com or --exclude-domains domain1.com,domain2.com
-k |--kill - Will kill the current execution of collector, you need to specify the domain as argument.
-ka |--kill-all - Will kill the current execution of collector and delete the directory of results from current execution, you need to specify the domain as argument.
-l |--limit-urls - Specify the url quantity to run dirsearch and gobuster for dirs and files enumeration [used only with -d|--domain]:
use -l 10 or --limit-urls 10
-o |--output - This option when specified will use the directory to save the output of collector script if omitted the default value is:
/home/leandro/pentest/scripts/recon/collector
- This option as well as others can be configured on collector.cfg, variable output_dir or use the parameters like:
use -o /path/of/output or --output-dir /path/of/output
-p |--proxy - This option will use a provided proxy (with port) to avoid or bypass WAF block.
use -p or --proxy
-r |--recon - Will execute a recon until you find out what domains are webpage: used only with -d|--domain WITHOUT -wd|--web-data.
-s |--subdomain-brute - Specify the wordlist to put in dns_wordlist array and execute gobuster and dnssearch brute force [used only with -d|--domain]
by default the array is empty and not execute amass, gobuster and dnssearch. This option take a long time to finish, use this own your need!
The success of use those tools is a good wordlist:
use -s /path/to/wordlist1,/path/to/wordlist2 or --subdomain-brute /path/to/wordlist1,/path/to/wordlist2
-u |--url - Specify a valid url [needed].
-wd |--web-data - Will execute a web data dig after execution of collector with recon option (--recon): used only with -d|--domain WITHOUT -r|--recon.
-wld|--web-long-detection - Will execute the long list of ports setup in collector.cfg as variable web_port_long_detection.
-wsd|--web-short-detection - Will execute the short list of ports setup in collector.cfg as variable web_port_short_detection.
-wtd|--web-tool-detection - You need to inform what tool to perform web application detection the tool can be curl OR httpx.
-ww |--web-wordlists - Specity more wordlists to put in web_wordlist array, by default we use the /dirsearch/db/dicc.txt
as the first wordlist to enumerate dirs and files from website.
use -ww /path/to/wordlist1,/path/to/wordlist2 or --web-wordlists /path/to/wordlist1,/path/to/wordlist2
Use as you need.
- Create a dated folder with recon notes
- Grab subdomains using:
- Amass, certspotter, cert.sh, subfinder and Sublist3r
- Dns bruteforcing using amass, gobuster and dnssearch
- The diff_domains function to improve the time of execution, get just what change on target infraestructure
- Perform nmap to live hosts
- Probe for live hosts over some ports like 80, 443, 8080, etc
- The web_data funtion from collector work when you put a list of URLs from file.
- Perform dirsearch and gobuster for all subdomains
- Scrape wayback
- Rebuild GIT repository
Alfredo Casanova with some bash code corrections.
Caue Bici with code review and answer some questions about python programming.
Enderson Maia with the help on Dockerfile and shellcheck tip.
Henrique Galdino the help with some curl options.
Icaro Torres with the ideia to diff files from a day ago to improve the execution time of the script.
Manoel Abreu with the ideia to use the git-dumper.py in rebuild_git function.
Rener aka gr1nch thanks to made the splitter, you rocks dude!!
Ulisses Alves with code review and answer some questions about python programming!
https://0xsp.com/offensive/red-teaming-toolkit-collection
https://medium.com/@ricardoiramar/subdomain-enumeration-tools-evaluation-57d4ec02d69e
https://github.com/riramar/Web-Attack-Cheat-Sheet
https://inteltechniques.com/blog/2018/03/06/updated-osint-flowcharts/
https://github.com/sehno/Bug-bounty/blob/master/bugbounty_checklist.md
https://github.com/renergr1nch/splitter
https://bitbucket.org/splazit/docker-privoxy-alpine/src/master/
https://github.com/essandess/adblock2privoxy
https://0xpatrik.com/subdomain-enumeration-2019/
https://blog.securitybreached.org/2017/11/25/guide-to-basic-recon-for-bugbounty/
https://medium.com/@shifacyclewala/the-complete-subdomain-enumeration-guide-b097796e0f3
https://www.secjuice.com/penetration-testing-for-beginners-part-1-an-overview/
https://www.secjuice.com/reconnaissance-for-beginners/
https://medium.com/@Asm0d3us/weaponizing-favicon-ico-for-bugbounties-osint-and-what-not-ace3c214e139
https://medium.com/hackernoon/10-rules-of-bug-bounty-65082473ab8c
https://https://findomain.app/findomain-advanced-automated-and-modern-recon/
https://www.offensity.com/de/blog/just-another-recon-guide-pentesters-and-bug-bounty-hunters/
https://medium.com/hackcura/learning-path-for-bug-bounty-6173557662a7
https://eslam3kl.medium.com/simple-recon-methodology-920f5c5936d4
https://github.com/nahamsec/Resources-for-Beginner-Bug-Bounty-Hunters
https://www.offensity.com/en/blog/just-another-recon-guide-pentesters-and-bug-bounty-hunters/
https://blog.projectdiscovery.io/reconnaissance-a-deep-dive-in-active-passive-reconnaissance/
https://0xffsec.com/handbook/information-gathering/subdomain-enumeration/#content-security-policy-csp-header
https://www.ceeyu.io/resources/blog/subdomain-enumeration-tools-and-techniques
https://securitytrails.com/blog/dns-enumeration
https://securitytrails.com/blog/whois-records-infosec-industry
Warning: The code of all scripts find here was originally created for personal use, it generates a substantial amount of traffic, please use with caution.