forked from TannerGilbert/Machine-Learning-Explained
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
1158c7d
commit 930338e
Showing
23 changed files
with
2,496 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,67 @@ | ||
| # Decision Trees | ||
|
|
||
|  | ||
|
|
||
| Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data. DTs are highly interpretable, capable of achieving high accuracy for many tasks while requiring little data preparation. | ||
|
|
||
| ## Creating a decision tree – Recursive Binary Splitting | ||
|
|
||
| Growing a tree involves continuously splitting the data into subsets to minimize some cost function. At each step, all features are considered, and different split points are tried and tested using a cost function. The split with the lowest cost is then selected. The process gets repeated until some stopping point (mentioned later). This algorithm is recursive in nature as the groups formed after each split can be subdivided using the same strategy. | ||
|
|
||
| ## Cost of a split | ||
|
|
||
| The cost of a split determines how good it is to split at that specific feature value. For regression cost functions like the sum of squared errors or the standard deviation are used. | ||
|
|
||
| <p align="center"><img src="/Algorithms/decision_tree/tex/99b4cda42ce5d6085705dc7458181012.svg?invert_in_darkmode&sanitize=true" align=middle width=150.0321735pt height=47.806078649999996pt/></p> | ||
|
|
||
| <p align="center"><img src="/Algorithms/decision_tree/tex/55fafb270a7563e9c79658b7e1a606e2.svg?invert_in_darkmode&sanitize=true" align=middle width=177.521784pt height=59.17867724999999pt/></p> | ||
|
|
||
| For classification the Gini Index is used: | ||
|
|
||
| <p align="center"><img src="/Algorithms/decision_tree/tex/3952bc7dadde93e3af8e54d66588d8b9.svg?invert_in_darkmode&sanitize=true" align=middle width=133.613238pt height=47.806078649999996pt/></p> | ||
|
|
||
| Where J is the set of all classes, and pi is the fraction of items belonging to class i. A split should ideally have an error value of zero, which means that the resulting groups contain only one class. The worst gini purity is 0.5, which occurs when the classes in a group are split 50-50. | ||
|
|
||
| ## When should you stop splitting? | ||
|
|
||
| Now you might ask when to stop growing the tree? This is an important question because if we would keep splitting and splitting the decision tree would get huge, quite fast. Such complex trees are slow and dent to overfit. Therefore, we will set a predefined stopping criterion to halt the construction of the decision tree. | ||
|
|
||
| The two most common stopping methods are: | ||
| * Minimum count of training examples assigned to a leaf node, e.g., if there are less than 10 training points, stop splitting. | ||
| * Maximum depth (maximum length from root to leaf) | ||
|
|
||
| A larger tree might perform better but is also more prone to overfit. Having too large of a min count or too small of a maximum depth could stop the training to early and result in bad performance. | ||
|
|
||
| ## Pruning | ||
|
|
||
| Pruning is a technique that reduces the size of decision trees by **removing sections of the tree** that have little importance. Pruning reduces the complexity of the final model, and hence improves predictive accuracy by reducing overfitting. | ||
|
|
||
| There are multiple pruning techniques available. In this article, we'll focus on two: | ||
| * Reduced error pruning | ||
| * Cost complexity pruning | ||
|
|
||
| ### Reduced error pruning | ||
|
|
||
| One of the simplest forms of pruning is reduced error pruning. Starting at the leaves, each node is replaced with its most popular class. If the loss function is not negatively affected, then the change is kept, else it is reverted. While a somewhat naive approach to pruning, reduced error pruning has the advantage of speed and simplicity. | ||
|
|
||
| ### Cost complexity pruning | ||
|
|
||
| Cost complexity pruning, also known as weakest link pruning, is a more sophisticated pruning method. It creates a series of trees T0 to Tn where T0 is the initial tree, and Tn is the root alone. The tree at step **i** is created by removing a subtree from tree **i-1** and replacing it with a leaf node. | ||
|
|
||
| For more information, check out: | ||
|
|
||
| [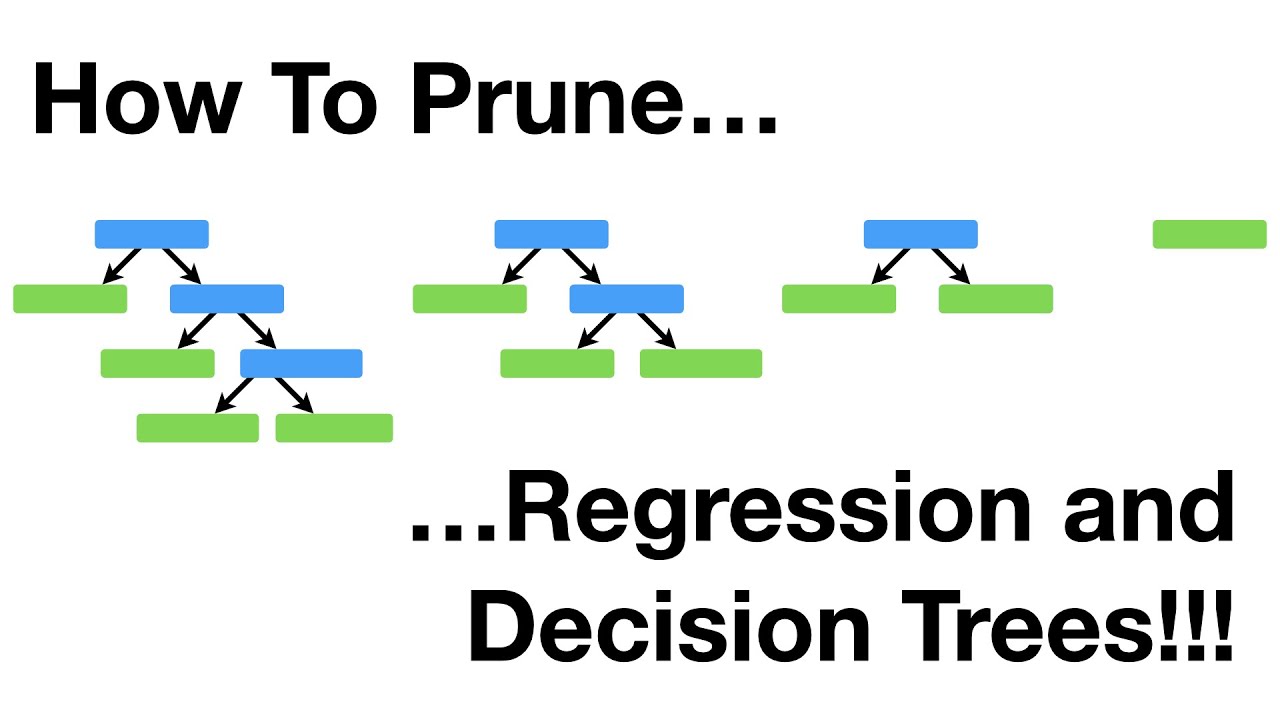](https://youtu.be/D0efHEJsfHo) | ||
|
|
||
| ## Code | ||
|
|
||
| * [Decision Tree Classifier](code/decision_tree_classification.py) | ||
| * [Decision Tree Regressor](code/decision_tree_regression.py) | ||
|
|
||
| ## Credit / Other resources | ||
|
|
||
| * [Decision Trees in Machine Learning](https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052) | ||
| * [A Guide to Decision Trees for Machine Learning and Data Science](https://towardsdatascience.com/a-guide-to-decision-trees-for-machine-learning-and-data-science-fe2607241956) | ||
| * [Scikit-Learn 1.10 Decision Trees](https://scikit-learn.org/stable/modules/tree.html) | ||
| * [How To Implement The Decision Tree Algorithm From Scratch In Python](https://machinelearningmastery.com/implement-decision-tree-algorithm-scratch-python/) | ||
| * [Implementing Decision Tree From Scratch in Python](https://medium.com/@penggongting/implementing-decision-tree-from-scratch-in-python-c732e7c69aea) | ||
| * [Decision Tree from Scratch in Python](https://towardsdatascience.com/decision-tree-from-scratch-in-python-46e99dfea775) |
36 changes: 36 additions & 0 deletions
36
Algorithms/decision_tree/tex/3952bc7dadde93e3af8e54d66588d8b9.svg
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Oops, something went wrong.