0.18.0: Exploiting column chunks for faster ingestion and lower memory use
Rerun is an easy-to-use visualization toolbox for multimodal and temporal data.
Try it live at https://rerun.io/viewer.
📖 Release blogpost: http://rerun.io/blog/column-chunks
🧳 Migration guide: http://rerun.io/docs/reference/migration/migration-0-18
- Python:
pip install rerun-sdk - Rust:
cargo add rerunandcargo install rerun-cli --locked - Online demo: https://rerun.io/viewer/version/0.18.0/
- C++
FetchContent: https://github.com/rerun-io/rerun/releases/download/0.18.0/rerun_cpp_sdk.zip
0.18.Release.hero.mp4
✨ Overview & highlights
Rerun 0.18 introduces new column-oriented APIs and internal storage datastructures (Chunk & ChunkStore) that can both simplify logging code as well as improve ingestion speeds and memory overhead by a couple orders of magnitude in many cases (timeseries-heavy workloads in particular).
These improvements come in 3 broad categories:
- a new
sendfamily of APIs, available in all 3 SDKs (Python, C++, Rust), - a new, configurable background compaction mechanism in the datastore,
- new CLI tools to filter, prune and compact RRD files.
Furthermore, we started cleaning up our data schema, leading to various changes in the way represent transforms & images.
New send APIs
Unlike the regular row-oriented log APIs, the new send APIs let you submit data in a columnar form, even if the data extends over multiple timestamps.
This can both greatly simplify logging code and drastically improve performance for some workloads, in particular timeseries, although we have already seen it used for other purposes!
API documentation:
API usage examples:
Python timeseries
Using log() (slow, memory inefficient):
rr.init("rerun_example_scalar", spawn=True)
for step in range(0, 64):
rr.set_time_sequence("step", step)
rr.log("scalar", rr.Scalar(math.sin(step / 10.0)))Using send() (fast, memory efficient):
rr.init("rerun_example_send_columns", spawn=True)
rr.send_columns(
"scalars",
times=[rr.TimeSequenceColumn("step", np.arange(0, 64))],
components=[rr.components.ScalarBatch(np.sin(times / 10.0))],
)C++ timeseries
Using log() (slow, memory inefficient):
const auto rec = rerun::RecordingStream("rerun_example_scalar");
rec.spawn().exit_on_failure();
for (int step = 0; step < 64; ++step) {
rec.set_time_sequence("step", step);
rec.log("scalar", rerun::Scalar(std::sin(static_cast<double>(step) / 10.0)));
}Using send() (fast, memory efficient):
const auto rec = rerun::RecordingStream("rerun_example_send_columns");
rec.spawn().exit_on_failure();
std::vector<double> scalar_data(64);
for (size_t i = 0; i < 64; ++i) {
scalar_data[i] = sin(static_cast<double>(i) / 10.0);
}
std::vector<int64_t> times(64);
std::iota(times.begin(), times.end(), 0);
auto time_column = rerun::TimeColumn::from_sequence_points("step", std::move(times));
auto scalar_data_collection =
rerun::Collection<rerun::components::Scalar>(std::move(scalar_data));
rec.send_columns("scalars", time_column, scalar_data_collection);Rust timeseries
Using log() (slow, memory inefficient):
let rec = rerun::RecordingStreamBuilder::new("rerun_example_scalar").spawn()?;
for step in 0..64 {
rec.set_time_sequence("step", step);
rec.log("scalar", &rerun::Scalar::new((step as f64 / 10.0).sin()))?;
}Using send() (fast, memory efficient):
let rec = rerun::RecordingStreamBuilder::new("rerun_example_send_columns").spawn()?;
let timeline_values = (0..64).collect::<Vec<_>>();
let scalar_data: Vec<f64> = timeline_values
.iter()
.map(|step| (*step as f64 / 10.0).sin())
.collect();
let timeline_values = TimeColumn::new_sequence("step", timeline_values);
let scalar_data: Vec<Scalar> = scalar_data.into_iter().map(Into::into).collect();
rec.send_columns("scalars", [timeline_values], [&scalar_data as _])?;Background compaction
The Rerun datastore now continuously compacts data as it comes in, in order find a sweet spot between ingestion speed, query performance and memory overhead.
This is very similar to, and has many parallels with, the micro-batching mechanism running on the SDK side.
You can read more about this in the dedicated documentation entry.
Post-processing of RRD files
To help improve efficiency for completed recordings, Rerun 0.18 introduces some new commands for working with rrd files.
Multiple files can be merged, whole entity paths can be dropped, and chunks can be compacted.
You can read more about it in the new CLI reference manual, but to give a sense of how it works the below example merges all recordings in a folder and runs chunk compaction using the max-rows and max-bytes settings:
rerun rrd compact --max-rows 4096 --max-bytes=1048576 /my/recordings/*.rrd > output.rrdOverhauled 3D transforms & instancing
As part of improving our arrow schema and in preparation for reading data back in the SDK, we've split up transforms into several parts.
This makes it much more performant to log large number of transforms as it allows updating only the parts you're interested in, e.g. logging a translation is now as lightweight as logging a single position.
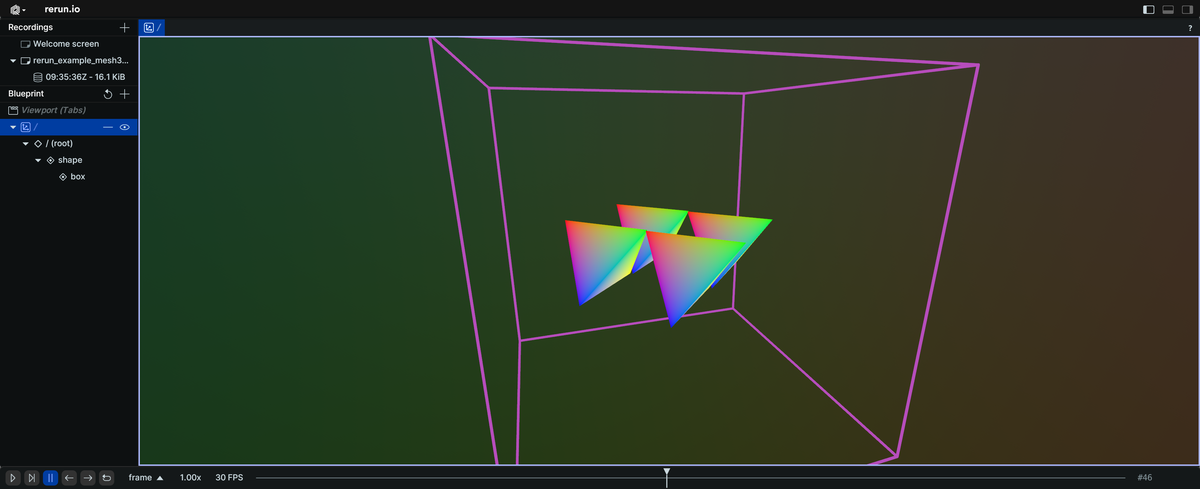
There are now additionally InstancePoses3D which allow you to do two things:
- all 3D entities: apply a transform to the entity without affecting its children
Mesh3D/Asset3D/Boxes3D/Ellipsoids3D: instantiate objects several times with different poses, known as "instancing"- Support for instancing of other archetypes is coming in the future!
All four tetrahedron meshes on this screen share the same vertices and are instanced using an InstancePoses3D archetype with 4 different translations
⚠️ Breaking changes
.rrdfiles from older versions won't load correctly in Rerun 0.18mesh_material: Materialhas been renamed toalbedo_factor: AlbedoFactor#6841Transform3Dis no longer a single component but split into its constituent parts. From this follow various smaller API changes- Python:
NV12/YUY2are now logged withImage ImageEncodedis deprecated and replaced withEncodedImage(JPEG, PNG, …) andImage(NV12, YUY2, …)DepthImageandSegmentationImageare no longer encoded as a tensors, and expects its shape in[width, height]order
🧳 Migration guide: http://rerun.io/docs/reference/migration/migration-0-18
🔎 Details
🪵 Log API
- Add
Ellipsoids3Darchetype #6853 (thanks @kpreid!) - Dont forward datatype extensions beyond the FFI barrier #6777
- All components are now consistently implemented by a datatype #6823
- Add new
archetypes.ImageEncodedwith PNG and JPEG support #6874 - New transform components:
Translation3D&TransformMat3x3#6866 - Add Scale3D component #6892
- Angle datatype stores now only radians #6916
- New
DepthImagearchetype #6915 - Port
SegmentationImageto the new image archetype style #6928 - Add components for
RotationAxisAngleandRotationQuat#6929 - Introduce
TransformRelationcomponent #6944 - New
LeafTransform3D, replacingOutOfTreeTransform3D#7015 - Remove
Scale3D/Transform3D/TranslationRotationScale3Ddatatypes, removeTransform3Dcomponent #7000 - Rewrite
Imagearchetype #6942 - Use
LeafTranslation(centers),LeafRotationQuatandLeafRotationAxisAngledirectly onBoxes3D/Ellipsoids3D#7029 - Removed now unused
Rotation3Dcomponent & datatype #7030 - Introduce new ImageFormat component #7083
🌊 C++ API
- Fix resetting time destroying recording stream #6914
- Improve usability of
rerun::Collectionby providing free functions forborrow&take_ownership#7055 - Fix crash on shutdown when using global recording stream variables in C++ #7063
- C++ API for
send_columns#7103 - Add numeric SDK version macros to C/C++ #7127
🐍 Python API
- New temporal batch APIs #6587
- Python SDK: Rename
ImageEncodedtoImageEncodedHelper#6882 - Introduce
ImageChromaDownsampled#6883 - Allow logging batches of quaternions from numpy arrays #7038
- Add
__version__and__version_info__to rerun package #7104 - Restore support for the legacy notebook mechanism from 0.16 #7122
🦀 Rust API
- Recommend install rerun-cli with
--locked#6868 - Remove
TensorBuffer::JPEG,DecodedTensor,TensorDecodeCache#6884
🪳Bug Fixes
- Respect 0.0 for start and end boundaries of scalar axis #6887 (thanks @amidabucu!)
- Fix text log/document view icons #6855
- Fix outdated use of view coordinates in
Spaces and Transformsdoc page #6955 - Fix zero length transform axis having an effect bounding box used for heuristics etc #6967
- Disambiguate plot labels with multiple entities ending with the same part #7140
rerun rrd compact: always put blueprints at the start of the recordings #6998- Fix 2D objects in 3D affecting bounding box and thus causing flickering of automatic pinhole plane distance #7176
- Fix a UI issue where a visualiser would have both an override and default set for some component #7206
🌁 Viewer improvements
- Add cyan to yellow colormap #7001 (thanks @rasmusgo!)
- Add optional solid/filled (triangle mesh) rendering to
Boxes3DandEllipsoids#6953 (thanks @kpreid!) - Improve bounding box based heuristics #6791
- Time panel chunkification #6934
- Integrate new data APIs with EntityDb/UI/Blueprint things #6994
- Chunkified text-log view with multi-timeline display #7027
- Make the recordings panel resizable #7180
🚀 Performance improvements
- Optimize large point clouds #6767
- Optimize data clamping in spatial view #6870
- Add
--blueprinttoplot_dashboard_stress#6996 - Add
Transformablessubscriber for improvedTransformContextperf #6997 - Optimize gap detector on dense timelines, like
log_tick#7082 - Re-enable per-series parallelism #7110
- Query: configurable timeline|component eager slicing #7112
- Optimize out unnecessary sorts in line series visualizer #7129
- Implement timeseries query clamping #7133
- Chunks:
- Implement ChunkStore and integrate it everywhere #6570
Chunkconcatenation primitives #6857- Implement on-write
Chunkcompaction #6858 - CLI command for compacting recordings #6860
- CLI command for merging recordings #6862
ChunkStore: implement new component-less indices and APIs #6879- Compaction-aware store events #6940
- New and improved iteration APIs for
Chunks #6989 - New chunkified latest-at APIs and caches #6992
- New chunkified range APIs and caches #6993
- New
Chunk-based time-series views #6995 - Chunkified, deserialization-free Point Cloud visualizers #7011
- Chunkified, (almost)deserialization-free Mesh/Asset visualizers #7016
- Chunkified, deserialization-free LineStrip visualizers #7018
- Chunkified, deserialization-free visualizers for all standard shapes #7020
- Chunkified image visualizers #7023
- Chunkify everything left #7032
- Higher compaction thresholds by default (x4) #7113
🧑🏫 Examples
- Add LeRobot example link #6873 (thanks @02alexander!)
- Add link to chess robot example #6982 (thanks @02alexander!)
- add depth compare example #6885 (thanks @pablovela5620!)
- Add mini NVS solver example #6888 (thanks @pablovela5620!)
- Add link to GLOMAP example #7097 (thanks @02alexander!)
- Add
send_columnsexamples for images, fix rustsend_columnshandling of listarrays #7172
📚 Docs
- New code snippet for Transform3D demonstrating an animated hierarchy #6851
- Implement codegen of doclinks #6850
- Add example for different data per timeline on
Events and Timelinesdoc page #6912 - Add troubleshooting section to pip install issues with outdated pip version #6956
- Clarify in docs when ViewCoordinate is picked up by a 3D view #7034
- CLI manual #7149
🖼 UI improvements
- Display compaction information in the recording UI #6859
- Use markdown for the view help widget #6878
- Improve navigation between entity and data results in the selection panel #6871
- Add support for visible time range to the dataframe view #6869
- Make clamped component data distinguishable in the "latest at" table #6894
- Scroll dataframe view to focused item #6908
- Add an explicit "mode" view property to the dataframe view #6927
- Introduce a "Selectable Toggle" widget and use it for the 3D view's camera kind #7064
- Improve entity stats when hovered #7074
- Update the UI colors to use our (blueish) ramp instead of pure greys #7075
- Query editor for the dataframe view #7071
- Better ui for
Blobs, especially those representing images #7128 - Add button for copying and saving images #7156
🕸️ Web
✨ Other enhancement
- Support decoding multiplexed RRD streams #7091
- Query-time clears (latest-at only) #6586
- Introduce
ChunkStore::drop_entity_path#6588 - Implement
Chunk::cell#6875 - Implement
Chunk::iter_indices#6877 - Drop, rather than clear, removed blueprint entities #7120
- Implement support for
RangeQueryOptions::include_extended_bounds#7132
🧑💻 Dev-experience
- Introduce
Chunkcomponent-level helpers andUnitChunk#6990 - Vastly improved support for deserialized iteration #7024
- Improved CLI: support wildcard inputs for all relevant
rerun rrdsubcommands #7060 - Improved CLI: explicit CLI flags for compaction settings #7061
- Improved CLI: stdin streaming support #7092
- Improved CLI: stdout streaming support #7094
- Improved CLI: implement
rerun rrd filter#7095 - Add support for
rerun rrd filter --drop-entity#7185
🗣 Refactors
- Forward Rust (de-)serialization of transparent datatypes #6793
- CLI refactor: introduce
rerun rrd <compare|print|compact>subscommand #6861 - Remove legacy query engine and promises #7033
- Implement
RangeQueryOptionsdirectly withinRangeQuery#7131
📦 Dependencies
- Update to glam 0.28 & replace
macawwith forkre_math#6867