murmur2 vs murmur3
I integrated Austin Appleby's murmur3 (the 32-bit version only) as a compile time (add -DMURMUR3 to FLAGS macro in Makefile) option to vw.
In a few early runs on an older version of murmur3 I found murmur3 slightly faster than murmur2 (~3%).
Update: after upgrading to the latest version of murmur3 and running more extensive tests on bigger data-sets, I find that murmur3 is actually sllightly slower. Here are two examples:
Dataset newdev (not public):
M2: 12.512u 2.448s 0:07.94 188.2%
12.992u 2.628s 0:08.39 186.0%
12.608u 2.632s 0:08.11 187.7%
12.556u 2.668s 0:08.11 187.5%
12.632u 2.568s 0:08.10 187.5%
12.580u 2.520s 0:08.03 188.0%
12.660u 2.624s 0:08.21 186.1% Mean elapsed time: 8.127143 sec
M3: 12.824u 2.612s 0:08.23 187.4%
12.764u 2.852s 0:08.40 185.8%
12.888u 2.592s 0:08.32 185.9%
12.912u 2.624s 0:08.29 187.3%
12.736u 2.720s 0:08.25 187.2%
12.456u 2.892s 0:08.19 187.3%
13.052u 2.420s 0:08.27 187.0% Mean elapsed time 8.278571 sec (1.8632% slower)
Dataset: concatenate ner.train.gz 10 times:
M2: 19.493u 1.560s 0:14.92 141.0%
19.509u 1.520s 0:14.92 140.8%
19.553u 1.488s 0:14.92 140.9%
19.389u 1.824s 0:15.20 139.4% Mean elapsed time: 14:99 sec
M3: 19.757u 1.444s 0:15.12 140.1%
20.521u 1.388s 0:15.60 140.3%
20.301u 1.896s 0:15.84 140.0%
20.013u 1.696s 0:15.53 139.7% Mean elapsed time: 15.5225 sec (3.55% slower)
I used the data-sets in the test suite. Most data-sets don't have collisions with neither hash because -b 18 (the default) seems large enough to achieve hash sparsity.
In order to stress the hashing, I used --exact_adaptive_norm and varied the -b bits parameter from as low as 12 to induce collisions.
I found that on most data-sets I tried, once collisions are induced/forced, murmur3 had a slight advantage in hash collision avoidance.
One exception was 0002.dat where murmur2 achieves no-colisions @ -b 18 (the default) while murmur3 achieves no-collisions only at -b 21. The 2 colliding feature-names were short.
Feature Hash Value
T^BKF 10281
T^IWR 10281
T^DXJ 100053
T^GML 100053
Note: changing the seed value (hash_base constant in hash.h) from 97562527 to 0 avoids these 2 collisions. In the final commited version I switched to seed 0. Most of the results below are with seed 97562527.
A few data-sets have too few features to be interesting. They have zero collisions because too few fatures don't tend to collide. cs_test has 5 features, frank.dat has 3 features, seq_small has 7 features. These are not included in the table below. Also note that data-sets with unique numeric features don't collide unless they are hashed as strings regardless of them looking like integers (--hash all).
#-of-collisons
@ -b 18 (default) Winning hash method
DataSet #-features M2 M3 (dominates most -b 12..30 range)
0001.dat 4290 0 0 Murmur3
0002.dat 289 0 2 Murmur2
zero.dat 1032 0 0 same (also with --hash all)
wiki1K.dat 6330 0 0 same (also with --hash all)
rcv1_small.dat 23530 1 0 Murmur3
wsj_small.dat 13762 383 334 Murmur3
ner.train 292497 116204 116108 Murmur3
Having less collisions doesn't always lead to a smaller train average loss. I found some evidence among our test-suite examples that random collisions may sometime act as some kind of regularization and the surprising result is a lower average loss at the end.
Note, some charts have clipped X and/or Y ranges since otherwise the difference is too small to easily see. I did run all tests on all the 12 .. 30 bit range.
Also, not all charts have the same comparison criterion. Criterion was chosen to emphasize difference.
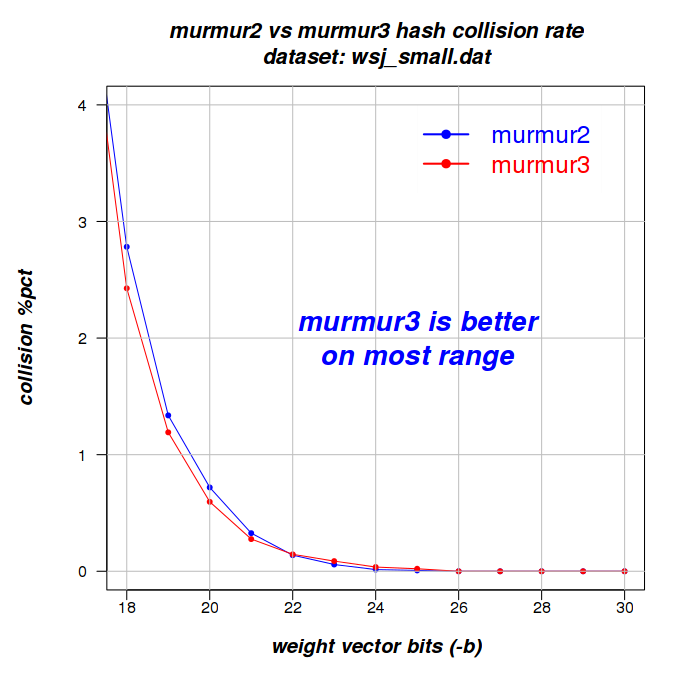
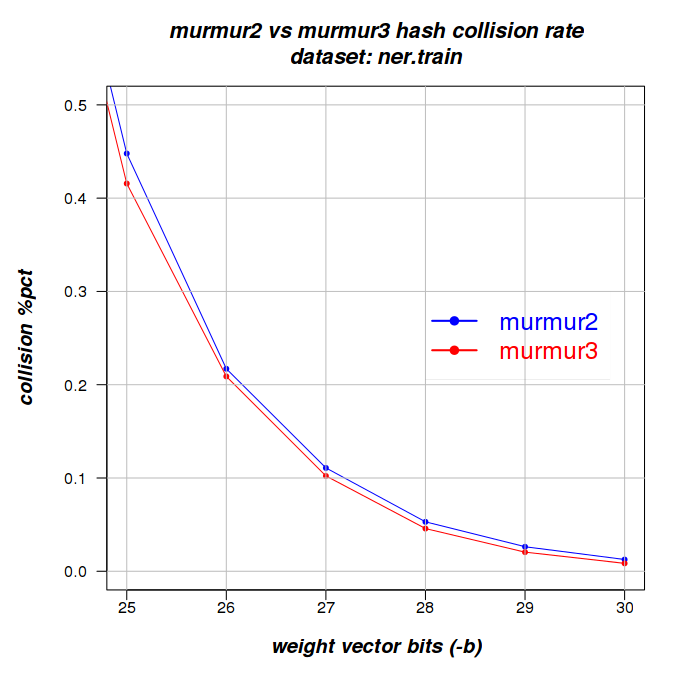
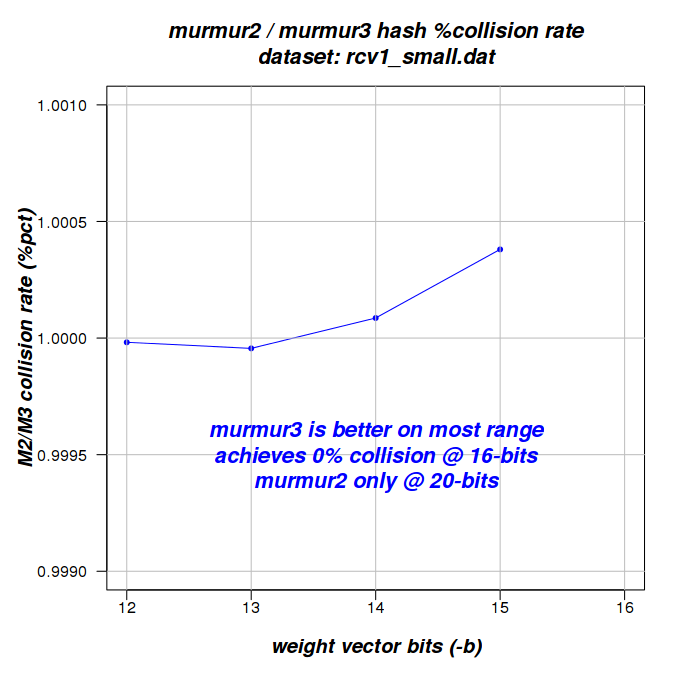
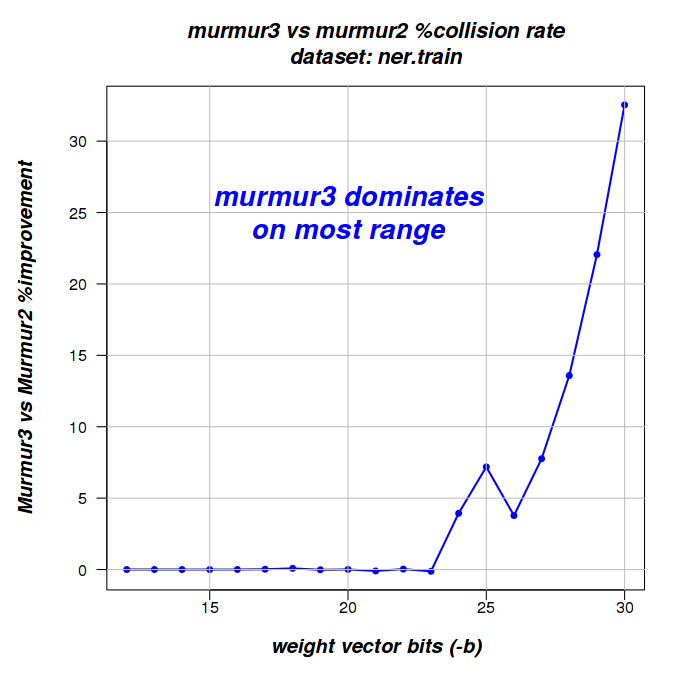
Had murmur3 been consistently faster, I would have recommended switching. While it is better on collision avoidance, the differences are small and you can achieve less collisions by simply increasing the weight-vector if you have a large number of features (using -b ...). I'm split about the advantages of Murmur3 and currently (Aug 15, 2012) I'm not sure a switch is worth it.
John felt the superior collision avoidance of murmur3 is worth the switch, especially with all the new reductions which tend to require larger per-feature space in the hash vector, so we have switched to murmur3.
The latest v 7.0 vowpal wabbit uses murmur3 (32 bit) as its core hash function. There's no longer a compile time option to switch back to murmur2.