migrate_v4_CN_low latency



Note: 如果觉得Github的Wiki访问太慢,可以访问 Gitee 镜像。
直播应用中,RTMP和HLS基本上可以覆盖所有客户端观看(参考:DeliveryHLS),HLS主要是延时比较大,RTMP主要优势在于延时低。
低延迟的部署实例参考:Usage: Realtime
低延时应用场景包括:
- 互动式直播:譬如2013年大行其道的美女主播,游戏直播等等各种主播,流媒体分发给用户观看。用户可以文字聊天和主播互动。
- 视频会议:SRS的DEMO就有视频会议应用,我们要是有同事出差在外地,就用这个视频会议开内部会议。其实会议1秒延时无所谓,因为人家讲完话后,其他人需要思考,思考的延时也会在1秒左右。当然如果用视频会议吵架就不行。
- 其他:监控,直播也有些地方需要对延迟有要求,互联网上RTMP协议的延迟基本上能够满足要求。
RTMP的特点如下:
- Adobe支持得很好:RTMP实际上是现在编码器输出的工业标准协议,基本上所有的编码器(摄像头之类)都支持RTMP输出。原因在于PC市场巨大,PC主要是Windows,Windows的浏览器基本上都支持flash,Flash又支持RTMP支持得灰常好。
- 适合长时间播放:因为RTMP支持的很完善,所以能做到flash播放RTMP流长时间不断流,当时测试是100万秒,即10天多可以连续播放。对于商用流媒体应用,客户端的稳定性当然也是必须的,否则最终用户看不了还怎么玩?我就知道有个教育客户,最初使用播放器播放http流,需要播放不同的文件,结果就总出问题,如果换成服务器端将不同的文件转换成RTMP流,客户端就可以一直播放;该客户走RTMP方案后,经过CDN分发,没听说客户端出问题了。
- 延迟较低:比起YY的那种UDP私有协议,RTMP算延迟大的(延迟在1-3秒),比起HTTP流的延时(一般在10秒以上)RTMP算低延时。一般的直播应用,只要不是电话类对话的那种要求,RTMP延迟是可以接受的。在一般的视频会议(参考SRS的视频会议延时)应用中,RTMP延时也能接受,原因是别人在说话的时候我们一般在听,实际上1秒延时没有关系,我们也要思考(话说有些人的CPU处理速度还没有这么快)。
- 有累积延迟:技术一定要知道弱点,RTMP有个弱点就是累积误差,原因是RTMP基于TCP不会丢包。所以当网络状态差时,服务器会将包缓存起来,导致累积的延迟;待网络状况好了,就一起发给客户端。这个的对策就是,当客户端的缓冲区很大,就断开重连。当然SRS也提供配置。
主要有人老是问这个问题,如何降低HLS延迟。
HLS解决延时,就像是爬到枫树上去捉鱼,奇怪的是还有人喊,看那,有鱼。你说是怎么回事。
我只能说你在参与谦哥的魔术表演,错觉罢了。
如果你真的确信有,请用实际测量的图片来展示出来,参考下面延迟的测量。
如何测量延时,是个很难的问题,不过有个行之有效的方法,就是用手机的秒表,可以比较精确的对比延时。参考:RTMP延时测量
经过测量发现,在网络状况良好时:
- RTMP延时可以做到0.8秒左右(SRS也可以)。
- 多级边缘节点不会影响延迟(和SRS同源的某CDN的边缘服务器可以做到)
- Nginx-Rtmp延迟有点大,估计是缓存的处理,多进程通信导致?
- GOP是个硬指标,不过SRS可以关闭GOP的cache来避免这个影响,参考后面的配置方法。
- 服务器性能太低,也会导致延迟变大,服务器来不及发送数据。
- 客户端的缓冲区长度也影响延迟。譬如flash客户端的NetStream.bufferTime设置为10秒,那么延迟至少10秒以上。
当开启最低延迟配置后,SRS会禁用mr(merged-read),并且在consumer队列中使用超时等待,大约每收到1-2个视频包就发送给客户端,达到最低延迟目标。
测试vp6纯视频流能达到0.1秒延迟,参考#257。配置文件:
vhost mrw.srs.com {
# whether enable min delay mode for vhost.
# for min latence mode:
# 1. disable the publish.mr for vhost.
# 2. use timeout for cond wait for consumer queue.
# @see https://github.com/ossrs/srs/issues/257
# default: off
min_latency off;
}
RTMP的Read效率非常低,需要先读一个字节,判断是哪个chunk,然后读取header,接着读取payload。因此上行支持的流的路数大约只有下行的1/3,譬如SRS1.0支持下行2700上行只有1000,SRS2.0支持下行10000上行只有4500。
为了提高性能,SRS对于上行的read使用merged-read,即SRS在读写时一次读取N毫秒的数据,这个可以配置:
# the MR(merged-read) setting for publisher.
vhost mrw.srs.com {
# the config for FMLE/Flash publisher, which push RTMP to SRS.
publish {
# about MR, read https://github.com/ossrs/srs/issues/241
# when enabled the mr, SRS will read as large as possible.
# default: off
mr off;
# the latency in ms for MR(merged-read),
# the performance+ when latency+, and memory+,
# memory(buffer) = latency * kbps / 8
# for example, latency=500ms, kbps=3000kbps, each publish connection will consume
# memory = 500 * 3000 / 8 = 187500B = 183KB
# when there are 2500 publisher, the total memory of SRS atleast:
# 183KB * 2500 = 446MB
# the value recomment is [300, 2000]
# default: 350
mr_latency 350;
}
}
也就是说,当开启merged-read之后,服务器的接收缓冲区至少会有latency毫秒的数据,延迟也就会有这么多毫秒。
若需要低延迟配置,关闭merged-read,服务器每次收到1个包就会解析。
SRS永远使用Merged-Write,即一次发送N毫秒的包给客户端。这个算法可以将RTMP下行的效率提升5倍左右,SRS1.0每次writev一个packet支持2700客户端,SRS2.0一次writev多个packet支持10000客户端。
用户可以配置merged-write一次写入的包的数目,建议不做修改:
# the MW(merged-write) settings for player.
vhost mrw.srs.com {
# for play client, both RTMP and other stream clients,
# for instance, the HTTP FLV stream clients.
play {
# set the MW(merged-write) latency in ms.
# SRS always set mw on, so we just set the latency value.
# the latency of stream >= mw_latency + mr_latency
# the value recomment is [300, 1800]
# default: 350
mw_latency 350;
}
}
若需要极低延迟(损失较多性能),可以设置为100毫秒,SRS大约一次发送几个包。
什么是GOP?就是视频流中两个I帧的时间距离,如果问什么是I帧就去百度。
GOP有什么影响?Flash(解码器)只有拿到GOP才能开始解码播放。也就是说,服务器一般先给一个I帧给Flash。可惜问题来了,假设GOP是10秒,也就是每隔10秒才有关键帧,如果用户在第5秒时开始播放,会怎么样?
第一种方案:等待下一个I帧,也就是说,再等5秒才开始给客户端数据。这样延迟就很低了,总是实时的流。问题是:等待的这5秒,会黑屏,现象就是播放器卡在那里,什么也没有,有些用户可能以为死掉了,就会刷新页面。总之,某些客户会认为等待关键帧是个不可饶恕的错误,延时有什么关系?我就希望能快速启动和播放视频,最好打开就能放!
第二种方案:马上开始放,放什么呢?你肯定知道了,放前一个I帧。也就是说,服务器需要总是cache一个gop,这样客户端上来就从前一个I帧开始播放,就可以快速启动了。问题是:延迟自然就大了。
有没有好的方案?有!至少有两种:
- 编码器调低GOP,譬如0.5秒一个GOP,这样延迟也很低,也不用等待。坏处是编码器压缩率会降低,图像质量没有那么好。
- 服务器提供配置,可以选择前面两个方案之一:SRS就这么做,有个gop_cache配置项,on就会马上播放,off就低延迟。
SRS的配置项:
# the listen ports, split by space.
listen 1935;
vhost __defaultVhost__ {
# for play client, both RTMP and other stream clients,
# for instance, the HTTP FLV stream clients.
play {
# whether cache the last gop.
# if on, cache the last gop and dispatch to client,
# to enabled fast startup for client, client play immediately.
# if off, send the latest media data to client,
# client need to wait for the next Iframe to decode and show the video.
# set to off if requires min delay;
# set to on if requires client fast startup.
# default: on
gop_cache off;
}
}备注:参考conf/full.conf的min.delay.com配置。
除了GOP-Cache,还有一个有关系,就是累积延迟。SRS可以配置直播队列的长度,服务器会将数据放在直播队列中,如果超过这个长度就清空到最后一个I帧:
# the max live queue length in seconds.
# if the messages in the queue exceed the max length,
# drop the old whole gop.
# default: 30
queue_length 10;当然这个不能配置太小,譬如GOP是1秒,queue_length是1秒,这样会导致有1秒数据就清空,会导致跳跃。
有更好的方法?有的。延迟基本上就等于客户端的缓冲区长度,因为延迟大多由于网络带宽低,服务器缓存后一起发给客户端,现象就是客户端的缓冲区变大了,譬如NetStream.BufferLength=5秒,那么说明缓冲区中至少有5秒数据。
处理累积延迟的最好方法,是客户端检测到缓冲区有很多数据了,如果可以的话,就重连服务器。当然如果网络一直不好,那就没有办法了。
考虑GOP-Cache和累积延迟,推荐的低延时配置如下(参考min.delay.com):
# the listen ports, split by space.
listen 1935;
vhost __defaultVhost__ {
tcp_nodelay on;
min_latency on;
play {
gop_cache off;
queue_length 10;
mw_latency 100;
}
publish {
mr off;
}
}当然,服务器的性能也要考虑,不可以让一个SRS进程跑太高带宽,一般CPU在80%以下不会影响延迟,连接数参考性能。
SRS: 0.9.55
编码器:FMLE, video(h264, profile=baseline, level=3.1, keyframe-frequency=5seconds), fps=15, input=640x480, output(500kbps, 640x480), 无音频输出(FMLE的音频切片HLS有问题)
网络:推流为PC在北京公司内网,观看为PC北京公司内网,服务器为阿里云青岛节点。
服务器配置:
listen 1935;
vhost __defaultVhost__ {
enabled on;
play {
gop_cache off;
}
hls {
enabled on;
hls_path ./objs/nginx/html;
hls_fragment 5;
hls_window 20;
}
}结论:RTMP延迟2秒,HLS延迟24秒。
参考:
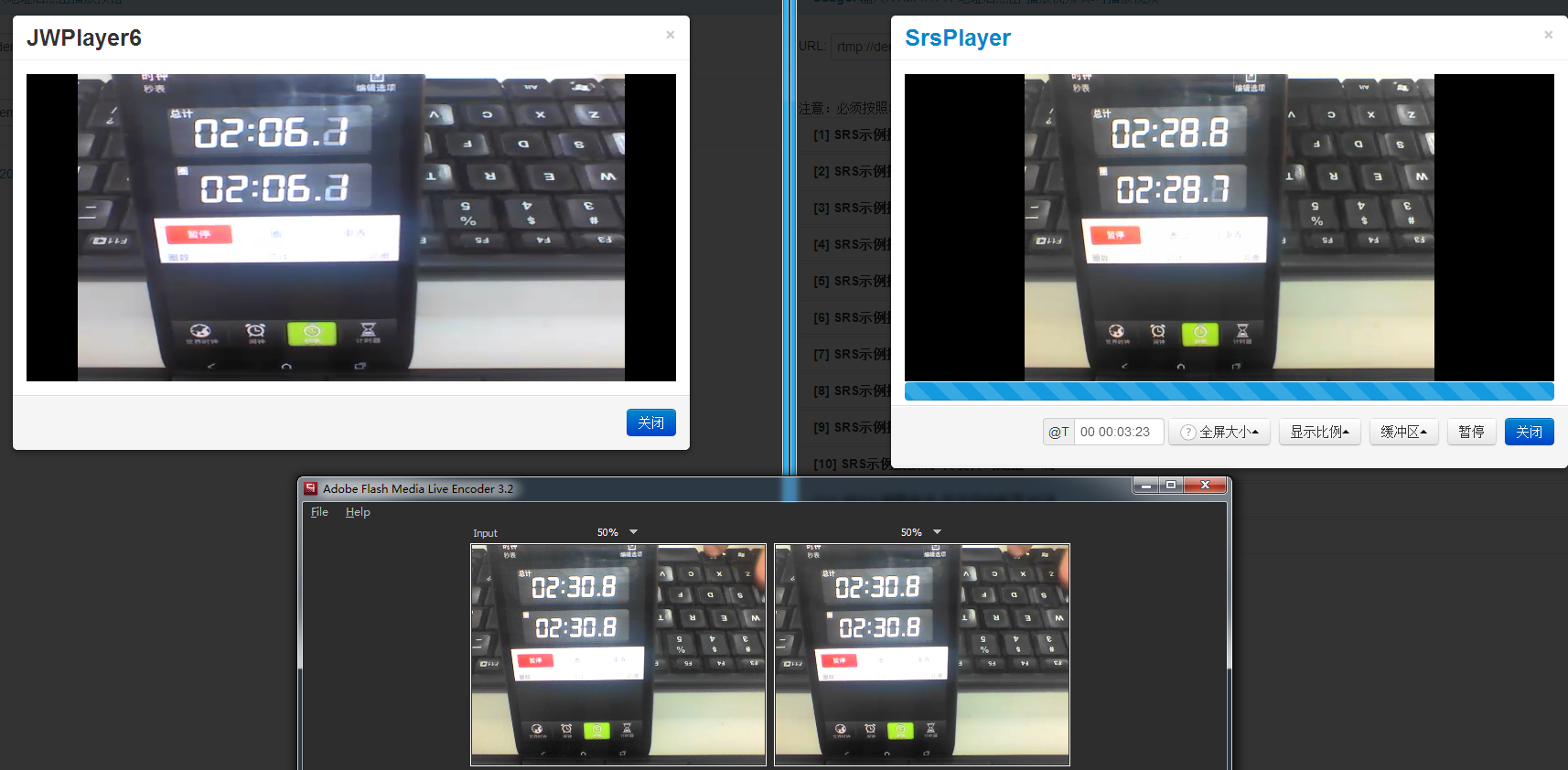
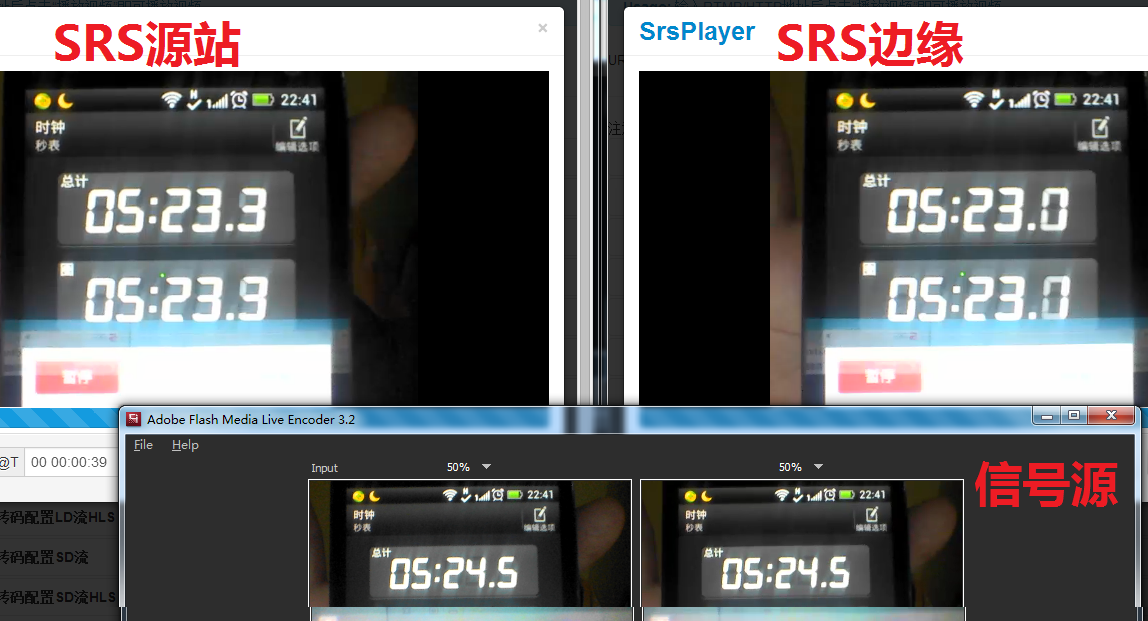
SRS集群不会增加延迟。这个是Edge模式比ingest要高级的地方,ingest需要启动进程,延迟会大。ingest主要适配多种协议,也可以主动从源站采集流,但Edge是专业的边缘模式。
参考:
Winlin 2015.8