Internals
Chandan B.N, Feb 2006
OpenGrok contains these main packages:
- org.opengrok.analysis: Responsible for analyzing programs, source files, archives like ZIP, tar, documents like man pages, xml and html files, images etc.,
- org.opengrok.index: Builds or updates the Lucene index, recursively going down the directory tree.
- org.opengrok.search: Has utilities that provide interface for search results, matched context etc.
- org.opengrok.history: Abstraction for source code version control.
- org.opengrok.web: Utility routines used by the the web application.
Think of the package as a separate department having engineers (called Analyzers) who are subject matter experts in each type of program or file type. CAnalyzer knows something about C programming language. The ELF Analyzer knows how to read a ELF symbol and string table from an ELF (executable) file.
Central to analysis, is the Analyzer Guru. He knows all the Analyzers by name. Most analyzers sit in static offices. Hiring a new Analyzer for each analysis work was a bit expensive.

When the indexer thinks he needs to analyze a file to be indexed, he calls Analyzer Guru. Analyzer Guru knows exactly who to send the file to. He creates a blank Lucene Document and a FileInputStream and gives it to the appropriate Analyzer. He knows the Analyzers by name, because they would initially tell him the file extensions and magic numbers of file types they are experts in.
On getting a document, an Analyzer sends it to his boss (super) to get it filled with more Lucene fields. A boss sends it to his boss, and so on. Higher up the management chain, they do less (specialized) work. For example while CAnalyzer knows a great deal about C keywords and comments and knows how to generate hyper-text cross-reference a C file, his boss Plain Analyzer can only read plain text files. He has poor punctuation skills and ignores most of the punctuation marks that he thinks are unnecessary. He knows what websites and email addresses are, so when he is asked to cross reference a file, he just hyper-links the URLs he can recognize.
Plain Analyzer also does an important job. He out sources finding definitions in a program file to Exuberant Ctags. He sends out the file to exuberant ctags, which tells him exactly what symbols are considered definitions. Plain Analyzer adds that information to the Lucene Document.
His boss, File Analyzer is the boss of the department. Every one reports to him. All he does is to stamp the Lucene document with file date and name and sends it back.
This package quite modular. It can be extended to analyze any program type. To add an Analyzer for a new type of programming language or file type, just extend or copy one of the suitable Analyzers and introduce his name to Analyzer Guru.
To get the version control history Analyzer Guru, calls his old friend the good old History Guru. This guy is much older than Analyzer Guru, and his silky long beard almost touches the ground. He has several assistants called History Readers. They just read the version control log history for a given file and directory. Currently there are assistants who can read Subversion, CVS and SCCS logs. To be able to support a new type of source code version control, just hire a new assistant reader who can read the logs.
Analyzer Guru on getting his Document returned back with different information like definitions, full-text, symbols, history, sends it back to the Indexer.
The index is the inverted index of all files in the source trees. For every unique word in the source tree it contains a list of files where the word can be found. While tools like cscope and ctags also build indexes, they can't incrementally update it. They just rebuild it from scratch. OpenGrok uses the modern indexing methods and can incrementally update its index. (i.e update only the changed/added/deleted files since last index build)
To know what files changed or got created or deleted we keep a sorted list of files in the index tagged with the files last modified date (converted in to a alphanumeric string such that dateString(date1) < dateString(date2) if date1 < date2. We traverse the file tree depth first at each stage sorting the child nodes, by which we get a sorted list of file paths.
It boils down to finding the diffs between two sorted lists (list of files on disk Vs list of files in the index). Left hand side is the file tree whose index on the right side needs to be updated. To begin with assume we had a correctly indexed tree Yesterday.
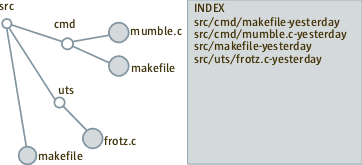
Let us say Today we removed a makefile and added a new file foo.c and modified frotz.c. During first pass we see that makefile-yesterday and frotz.c-today on our index-list did not match tree-traversal list. So we delete those lines (i.e documents) from the index.

During second pass we see that foo.c-today and frotzc-today are new and we add the documents to the index.
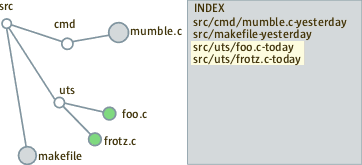
The Lucene inverted index can be either opened to add more documents or delete existing documents at a time. To update a document you must delete it first, close the index and add it again. To optimize for faster updates, we first delete in the index all the changed or deleted files in the source tree. In the second pass we add all the documents not in the index.