This repo contains a Python script that crawls gig information from the "Data Processing" category on Fiverr
The aim of this project was to scrape the "Data Processing" category on Fiverr and extract gig information from the listing page.
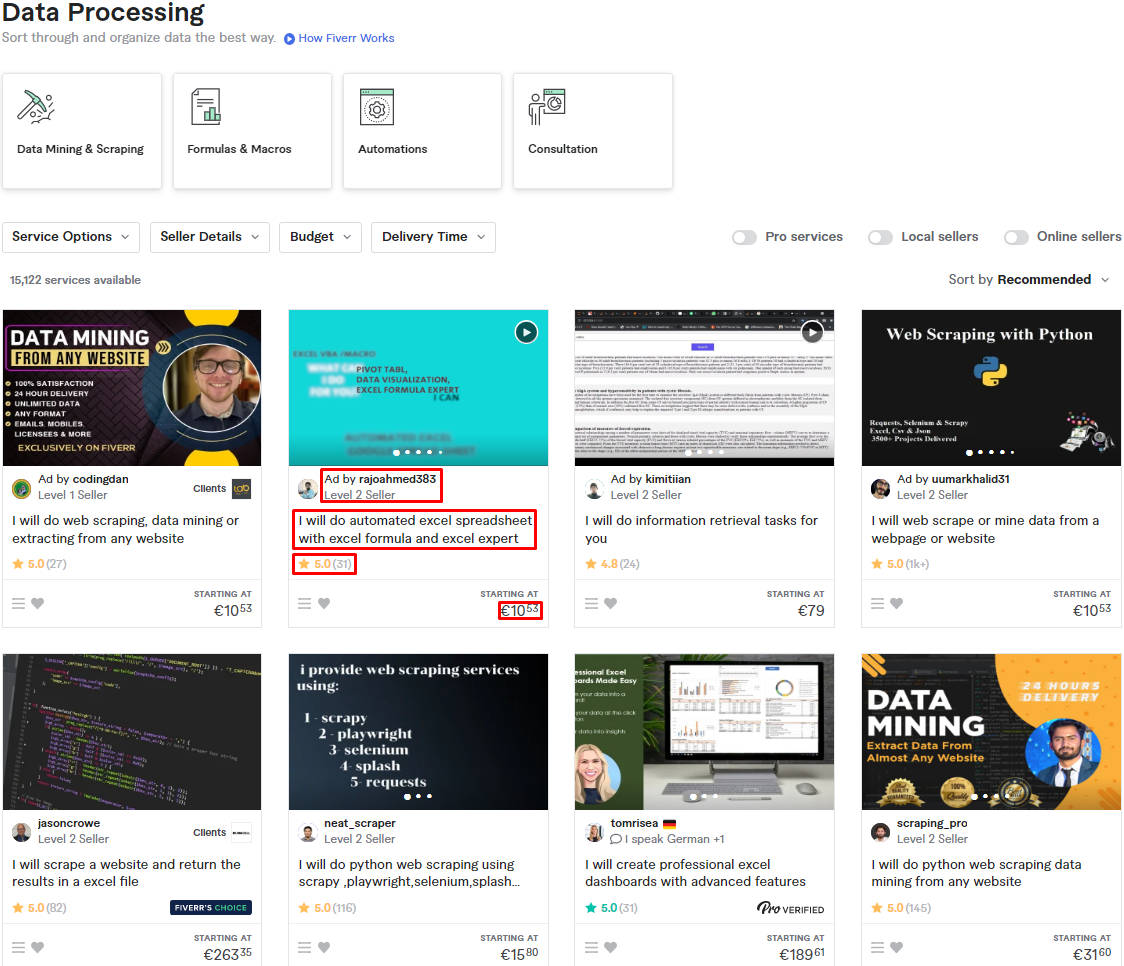
These are the fields that could be extracted from the listing page:
- seller_name
- gig_url
- seller_level (if it exists)
- gig_title
- gig rating (if it exists)
- number_of_reviews (if it exists)
- gig_starting_price
I used the scrapy framework in Python to crawl this information from the first ten pages under the "Data Processing" category. Fiverr is a difficult website to scrape. It employs many anti-bot mechanism that block your IP if you try to crawl it using the standard methods. Moreover, it is Javascript-rendered, which means that the data you want to crawl is not present in the HTML code that can be obtained by a standard GET request.
To overcome these two challenges, I used ScraperAPI, which is a proxy solution for web scraping that is designed to make scraping the web at scale as simple as possible. It does that by removing the hassle of finding high quality proxies, rotating proxy pools, detecting bans, solving CAPTCHAs, and managing geotargeting, and rendering Javascript. With simple API calls, you can get the HTML from any web page you desire and scale your requests as needed.
First, you need to create ScraperAPI account. Use the sign-up page to do that. ScraperAPI offers a free plan of 1,000 free API credits per month (with a maximum of 5 concurrent connections) for small scraping projects. For the first 7-days after you sign up, you will have access to 5,000 free requests along with all the premium features to test all capabilities of the API.
After you create your account, you should land on a page that looks like this...

Assuming you already cloned the repo via this command git clone https://github.com/omar-elmaria/fiverr_scraper.git, you should create a .env file and place your API key in it as shown below.
SCRAPER_API_KEY={INSERT_API_KEY_WITHOUT_THE_CURLY_BRACES}
When you do that, the spiders should run without problems. To fire up a spider, cd into the folder fiverr and run the following command in your terminal, replacing the variable {SPIDER_NAME} with the name of the spider you want to run.
scrapy crawl SPIDER_NAME
After the spider finishes its job, a JSON file will appear in your directory showing you the results. It will look something like this.
 N.B. The picture is truncated to preserve space. Not all fields are shown
N.B. The picture is truncated to preserve space. Not all fields are shown
In this project, I created two spiders, fiverr_spider_sync and fiverr_spider_async. The first one utilizes the standard logic suggested by the scrapy documentation to crawl paginated websites. It works by obtaining the link to the next page via a CSS or XPATH selector and sending a scrapy.Request with a callback function to crawl the next page with the same parsing function used for the first page. This logic is shown below.
# def parse(self, response):
# ... parsing logic is written here
# Add pagination logic (synchronous). This is at the end of the parse function after the fields are yielded to a dictionary
next_page = response.css("li.pagination-arrows > a::attr(href)").get() # Obtain the link to the next page
current_page = response.css("li.page-number.active-page > span::text").get() # Obtain the current page number
if next_page is not None and int(current_page) <= 10:
yield scrapy.Request( # Send a new scrapy.Request that loops back to the parse function to crawl the same data on the next
client.scrapyGet(url = next_page, country_code = "de", render = True),
callback = self.parse,
dont_filter = True
)The problem with this logic is that it kills concurrency because you need to wait for one page to be rendered and crawled before you can send a request to the next page and crawl it. That's where the second spider fiverr_spider_async comes in. It sends requests to the 10 pages that I want to crawl asynchronously and parses the data whenever it receives back a response from Fiverr's server. I recommend you use that spider because it is 5 to 7 times faster than the other one.
Whenever you use ScraperAPI, it is recommended that you add these settings to your spider class. You can check how the dictionary below is added to the spider class by looking at one of the spider Py files.
# Define the dictionary that contains the custom settings of the spiders. This will be used in all other spiders
custom_settings_dict = {
"FEED_EXPORT_ENCODING": "utf-8", # UTF-8 deals with all types of characters
"RETRY_TIMES": 10, # Retry failed requests up to 10 times (10 instead of 3 because Fiverr is a hard site to scrape)
"AUTOTHROTTLE_ENABLED": False, # Disables the AutoThrottle extension (recommended to be used with proxy services unless the website is tough to crawl)
"RANDOMIZE_DOWNLOAD_DELAY": False, # If enabled, Scrapy will wait a random amount of time (between 0.5 * DOWNLOAD_DELAY and 1.5 * DOWNLOAD_DELAY) while fetching requests from the same website
"CONCURRENT_REQUESTS": 5, # The maximum number of concurrent (i.e. simultaneous) requests that will be performed by the Scrapy downloader
"DOWNLOAD_TIMEOUT": 60, # Setting the timeout parameter to 60 seconds as per the ScraperAPI documentation
"FEEDS": {"JSON_OUTPUT_FILE_NAME.json":{"format": "json", "overwrite": True}} # Export to a JSON file with an overwrite functionality
}ScraperAPI allows you to use different options in your API calls to customize your requests. Please check the Customise API Functionality section in the API documentation to see what each of these option means and how it affects your API credits.
- render
- country_code
- premium
- session_number
- keep_headers
- device_type
- autoparse
- ultra_premium
In this project, I use render to render the Javascript content of Fiverr, country_code to send my requests from German IP addresses, and premium to use high quality proxies that lower the porbability of the spider getting blocked and not returning any data.
Whenever you send similar requests to a webpage, which is the case we have with this spider, Scrapy automatically filters out the duplicate ones, which prevents you from crawling all the data you want. To prevent this behavior, you should set the dont_filter parameter in the scrapy.Request method to True like so...
url = "https://www.fiverr.com/categories/data/data-processing?source=category_tree"
yield scrapy.Request(
client.scrapyGet(url = url, country_code = "de", render = True, premium = True),
callback = self.parse,
dont_filter = True
)If you want to run your spiders as a script and not from the terminal, use the code below.
from scrapy.crawler import CrawlerProcess
class TestSpider(scrapy.Spider):
# Some code goes here...
process = CrawlerProcess() # You can also insert custom settings as a dictionary --> CrawlerProcess(settings={"CONCURRENT_REQUESTS": 5})
process.crawl(TestSpider)
process.start()If you have any questions or wish to build a scraper for a particular use case, feel free to contact me on LinkedIn