Tutorial Small Model R
Download and install Aurelius. This article was tested with Aurelius 0.7.1; newer versions should work with no modification. R >= 3.0.1 is required.
Launch an R session and load the aurelius library:
R version 3.0.1 (2013-05-16) -- "Good Sport"
Copyright (C) 2013 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
Natural language support but running in an English locale
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> library(aurelius)
To "test models in Titus," you'll also need to download and install Titus and install the R packages rPython and RJSONIO. This article was tested with Titus 0.7.1; newer versions should work with no modification. Python >= 2.6 and < 3.0 is required.
Launch a Python prompt and import PFAEngine to verify the installation:
Python 2.7.6
Type "help", "copyright", "credits" or "license" for more information.
>>> from titus.genpy import PFAEngine
If you can't load Titus in a Python prompt, R won't be able to load Titus, either. (And the directory that you launch Python or R from can matter.)
This tutorial follows up on the previous one, in which we converted the following decision tree to PFA using Titus in Python:
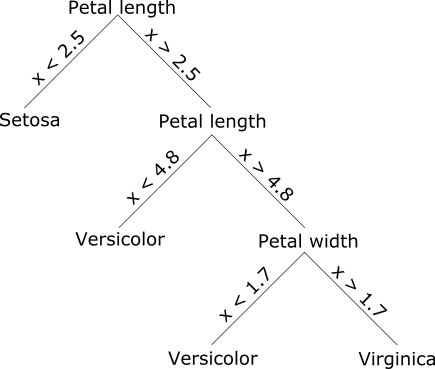
Now we will do it using Aurelius in R. As before, we will start with a simple if-statement implementation and follow up with a more realistic implementation that separates model parameters from code.
To hard-wire the above model in R, we'd write code like the following:
action <- function(input) {
if (input$petal_length_cm < 2.5)
"setosa"
else if (input$petal_length_cm < 4.8)
"versicolor"
else if (input$petal_width_cm < 1.7)
"versicolor"
else
"virginica"
}Aurelius lets us convert that directly into PFA, after we wrap it up with input and output schemas.
pfaDocument <- pfa.config(
input = avro.record(list(
sepal_length_cm = avro.double,
sepal_width_cm = avro.double,
petal_length_cm = avro.double,
petal_width_cm = avro.double)),
output = avro.string,
action = expression(
if (input$petal_length_cm < 2.5)
"setosa"
else if (input$petal_length_cm < 4.8)
"versicolor"
else if (input$petal_width_cm < 1.7)
"versicolor"
else
"virginica"))
cat(json(pfaDocument))The key R function is expression, which withholds R code from execution, so that Aurelius can inspect it and replace it with the equivalent PFA. The json function can either fill a string in memory (as above) or stream the model to disk (if you give it a fileName parameter; see its documentation).
Although Aurelius will fail if it finds code that it doesn't understand, it does not do a detailed check of the document. For that, we either have to save the model as a file and open it in Titus or Hadrian, or we can send it to Titus through this command in R:
engine <- pfa.engine(pfaDocument)
engine$action(list(sepal_length_cm = 5.1,
sepal_width_cm = 3.5,
petal_length_cm = 1.4,
petal_width_cm = 0.2))This only works if you have Titus, rPython, and RJSONIO installed (see above).
Just as you could manipulate JSON-like objects in Python because they were nested Python dict, list, strings, numbers, and True, False, None, you can manipulate JSON-like objects in R because they are named lists, unnamed lists, character arrays, numbers, and TRUE, FALSE, NULL (no vectors, data frames, environments, or other types of R objects!). The pfa.config function turns R code into these lists-of-lists and the engines made by pfa.engine expect data in that form.
This tests the engine against the Iris dataset that is built into R.
for (i in 1:150)
print(paste(engine$action(list(sepal_length_cm = iris$Sepal.Length[i],
sepal_width_cm = iris$Sepal.Width[i],
petal_length_cm = iris$Petal.Length[i],
petal_width_cm = iris$Petal.Width[i])),
"vs", iris$Species[i]))For the same reasons as in the previous tutorial, we want the model parameters to be in the "cell" or "pool" section of PFA, not the "action". Since the progression from building the model by hand to using library functions was to illustrate features of PFA, we can skip to the library functions in this tutorial.
tm <- avro.typemap(
Input = avro.record(list(
sepal_length_cm = avro.double,
sepal_width_cm = avro.double,
petal_length_cm = avro.double,
petal_width_cm = avro.double)),
Output = avro.string)
tm2 <- avro.typemap(
TreeNode = avro.record(list(
field = avro.enum(list("sepal_length_cm", "sepal_width_cm",
"petal_length_cm", "petal_width_cm")),
operator = avro.string,
value = avro.double,
pass = avro.union("TreeNode", tm("Output")),
fail = avro.union("TreeNode", tm("Output"))),
"TreeNode"))
pfaDocument <- pfa.config(
input = tm("Input"),
output = tm("Output"),
cells = list(
tree = pfa.cell(tm2("TreeNode"), list(
field = "petal_length_cm",
operator = "<",
value = 2.5,
pass = list(string = "Iris-setosa"),
fail = list(TreeNode = list(
field = "petal_length_cm",
operator = "<",
value = 4.8,
pass = list(string = "Iris-versicolor"),
fail = list(TreeNode = list(
field = "petal_width_cm",
operator = "<",
value = 1.7,
pass = list(string = "Iris-versicolor"),
fail = list(string = "Iris-virginica")
))
))
))
),
action = expression(
model.tree.simpleWalk(
input, tree, function(d = tm("Input"), t = tm2("TreeNode") -> avro.boolean) {
model.tree.simpleTest(d, t)
})
))The tm and tm2 objects are typemaps: functions that yield the full definition of a type the first time it is requested and just the name of the type subsequently. This ensures that each type is declared exactly once in the PFA document (a requirement to ensure consistency). There are two typemaps because "TreeNode" depends on "Output".
Also note that the functions called in the converted R code are PFA functions. Aurelius can convert R's binary operators to the equivalent PFA functions, but it would be too confusing if it attempted to convert R functions as well.
Although everything inside of the expression is syntactically valid R code, there are a few small deviations from how it is interpreted.
- Function parameter lists in PFA need data types while R doesn't so we require default parameters (with
=) and interpret them as the data types. In the function above,d = tm("Input")means argumentdhas typetm("Input"). - Functions in PFA require return values, so we do that with either
. = RETURNTYPEor-> RETURNTYPE(by an underhanded use of the assignment operator). - List indexes in PFA start with 0, not with 1 as in R.
- PFA types don't make a distinction between double brackets (
[[and]]) and single brackets ([and]). You may use them interchangeably.
The primary use of Aurelius is to convert models from R libraries into PFA. Each R package represents its model parameters differently, so Aurelius needs functions for each model type, and currently
are covered. More are being added.
In this part of the tutorial, we will generate some fake data, build a random forest model on it, and convert that to PFA.
library(randomForest)
# make a fake data table
x1 <- as.factor(sample(c("one", "two", "three", "four", "five"), 1000, replace = TRUE))
x2 <- rnorm(1*1000, 0, 10)
y <- as.factor(x1 == "one")
levels(y)[levels(y) == FALSE] <- "bad"
levels(y)[levels(y) == TRUE] <- "good"
dataFrame <- data.frame(x1, x2, y)
names(dataFrame)[1:2] <- c(paste("x", 1:2, sep=""))
# fit a forest to this data
forest <- randomForest(y~., data = dataFrame, ntree = 100, maxnodes = 5)Aurelius functions for converting models from the randomForest library are named pfa.randomForest.*. The code below converts the forest into a list-of-lists with the right structure for a PFA document.
pfaForest <- lapply(c(1:forest$ntree), function (i) {
treeTable <- pfa.randomForest.extractTree(forest, whichTree = i, labelVar = TRUE)
forestParams <- pfa.randomForest.buildOneTree(
treeTable,
1,
valueNeedsTag = TRUE,
dataLevels = list(x1 = list("one", "two", "three", "four", "five")),
fieldTypes = list("x1" = "string", "x2" = "double"))$TreeNode
})To show more features, let's assume that sometimes x2 is missing and we need to impute a value before sending it to the forest (pre-processing). Let's further assume that we want to impute x2 using the exponentially weighted moving average of non-missing values. The model will have two cells: one for the forest (unchanging) and one for the current value of the exponentially weighted moving average (changing).
# now we have a distinction between Input and Derived types,
# and also have a RunningAverage and more complex Output
tm <- avro.typemap(
Input = avro.record(list(
x1 = avro.string,
x2 = avro.union(avro.null, avro.double)),
"Input"),
Derived = avro.record(list(
x1 = avro.string,
x2 = avro.double),
"Derived"),
RunningAverage = avro.record(list(
mean = avro.double),
"RunningAverage"),
TreeNode = avro.record(list(
field = avro.enum(list("x1", "x2"), "Fields"),
operator = avro.string,
value = avro.union(avro.array(avro.string), avro.double),
pass = avro.union("TreeNode", avro.string),
fail = avro.union("TreeNode", avro.string)),
"TreeNode"),
Breakdown = avro.map(avro.double),
Output = avro.record(list(
winner = avro.string,
breakdown = avro.map(avro.double)),
"Output")
)
# parameters that get baked into the PFA
EWMA_ALPHA <- 0.1
EWMA_START <- mean(x2)
# build the rest of the PFA around it (make an R list-of-lists structure)
pfaDocument <- pfa.config(
input = tm("Input"),
output = tm("Output"),
action = expression(
# pre-processing
derived <- new(tm("Derived"),
x1 = s.lower(input$x1),
x2 = u.imputeX2(input$x2)),
# model (tree-scoring function is built by composing
# model.tree.simpleWalk with model.tree.simpleTest;
# forest-scoring is just a repeated application for
# all trees in the forest)
scores <- a.map(forest, function(tree = tm("TreeNode") -> avro.string) {
model.tree.simpleWalk(
derived,
tree,
function(d = tm("Derived"), node = tm("TreeNode") -> avro.boolean) {
model.tree.simpleTest(d, node)
})
}),
# post-processing
winner <- a.mode(scores),
breakdown <- new(tm("Breakdown"),
bad = a.count(scores, "bad") / a.len(scores),
good = a.count(scores, "good") / a.len(scores)),
# output
new(tm("Output"), winner = winner, breakdown = breakdown)),
# persistent data: tree parameters and running average of x2 for imputing
cells = list(
forest = pfa.cell(avro.array(tm("TreeNode")), pfaForest),
runningAverage = pfa.cell(tm("RunningAverage"), list(mean = EWMA_START))),
# user-defined functions: imputes value of x2 when missing
fcns = list(
imputeX2 = expression(function(possiblyNull = avro.union(avro.null, avro.double) -> avro.double) {
if (!is.null(x <- possiblyNull)) {
# update average
runningAverage <<- function(old = tm("RunningAverage") -> tm("RunningAverage")) {
stat.sample.updateEWMA(x, EWMA_ALPHA, old)
}
# but return the real value
x
}
else {
# use the average
runningAverage$mean
}
}))
)If you have Titus, rPython, and RJSONIO installed, test it with a missing and a non-missing value.
# test it with Titus right here in R
engine <- pfa.engine(pfaDocument)
datum <- '{"x1": "THREE", "x2": {"double": 3.14}}' # non-missing value
cat(paste("test", datum, "\n"))
print(engine$action(unjson(datum)))
datum <- '{"x1": "Three", "x2": null}' # missing value
cat(paste("test", datum, "\n"))
print(engine$action(unjson(datum)))Since this is a moderately large model, we'll use it as an example to test in the next two tutorials. If you don't get to this point, don't worry; we have a sample copy of myModel.pfa and myData.jsons ready for downloading.
# output as PFA (serialize the list-of-lists as JSON)
json(pfaDocument, fileName = "myModel.pfa")
# create some test data for Hadrian
writeLines(
mapply(
function(x1, x2) {
json(list(x1 = toupper(x1),
x2 = if (x2 %% 1.0 > 0.9) NULL else list(double = x2)))
},
dataFrame$x1,
dataFrame$x2),
con = "myData.jsons",
sep = ""
)