-
Notifications
You must be signed in to change notification settings - Fork 7
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #105 from mila-iqia/development
Release 3.0
- Loading branch information
Showing
52 changed files
with
518 additions
and
789 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
File renamed without changes.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,36 +1,226 @@ | ||
| [](https://travis-ci.com/github/mila-iqia/cookiecutter-pyml) | ||
| # AMLRT Cookiecutter - Initialize a new project | ||
|
|
||
| About | ||
| ----- | ||
| First, git clone this project template locally. | ||
|
|
||
| A cookiecutter is a generic project template that will instantiate a new project with sane defaults. This repo contains our custom cookiecutter (`cookiecutter-pyml`) which will generate a new python deep learning package preconfigured with best practices in mind. It currently supports: | ||
| git clone https://github.com/mila-iqia/cookiecutter-pyml.git | ||
|
|
||
| * Pytorch (PyTorch Lightning) | ||
| * Github Actions (CI/CD) | ||
| * Sphinx (documentation) | ||
| * Tensorboard (experiment tracking) | ||
| * Orion (hyperparameter optimization) | ||
| * Flake8 (linting) | ||
| * Pytest (unit testing) | ||
| Select a name for the new project; in the following we assume that | ||
| the name is `${PROJECT_NAME}`. Change it accordingly to the correct name. | ||
|
|
||
| More information on what a cookiecutter is [here.](https://cookiecutter.readthedocs.io) | ||
| Rename your just-cloned folder to the new project name: | ||
|
|
||
| Quickstart | ||
| ---------- | ||
| mv cookiecutter-pyml ${PROJECT_NAME} | ||
|
|
||
| Install the latest version of cookiecutter: | ||
| Now go into the project folder and delete the git history. | ||
|
|
||
| pip install -U cookiecutter | ||
| cd ${PROJECT_NAME} | ||
| rm -fr .git | ||
|
|
||
| Generate your project using our template. Make sure to use the command exactly as you see it here. | ||
| This will use cookiecutter to instantiate your new project from our template (https://github.com/mila-iqia/cookiecutter-pyml.git). | ||
| This is done so that your new project will start with a clean git history. | ||
| Now, initialize the repository with git: | ||
|
|
||
| cookiecutter https://github.com/mila-iqia/cookiecutter-pyml.git | ||
| git init | ||
|
|
||
| Follow the CLI instructions, then cd into your newly created project folder: | ||
| And perform the first commit: | ||
|
|
||
| cd $YOUR_PROJECT_NAME | ||
| git add . | ||
| git commit -m 'first commit' | ||
|
|
||
| Follow the instructions in the README in the newly created repository (`$YOUR_PROJECT_NAME/README.md`) to get started with your new project (in particular, the section "Instructions to setup the project"). | ||
| Go on github and follow the instructions to create a new project. | ||
| When done, do not add any file, and follow the instructions to | ||
| link your local git to the remote project, which should look like this: | ||
| (PS: these instructions are reported here for your convenience. | ||
| We suggest to also look at the GitHub project page for more up-to-date info) | ||
|
|
||
| Enjoy the cookies! | ||
| git remote add origin [email protected]:${GITHUB_USERNAME}/${PROJECT_NAME}.git | ||
| git branch -M main | ||
| git push -u origin main | ||
|
|
||
| At this point, the local code is versioned with git and pushed to GitHub. | ||
| You will not need to use the instructions in this section anymore, so we | ||
| suggest to delete this section ("AMLRT Cookiecutter - Initialize a new project") entirely. | ||
| (by doing so it will be clear that the initialization has been already done, | ||
| and all you need from now on is just to git clone from the repository you | ||
| just pushed, i.e., `[email protected]:${GITHUB_USERNAME}/${PROJECT_NAME}.git`). | ||
|
|
||
| # amlrt_project (change this name to the name of your project) | ||
|
|
||
| Replace this line with a short description about your project! | ||
|
|
||
| ## Instructions to setup the project | ||
|
|
||
| ### Install the dependencies: | ||
| First, activate a virtual environment (recommended). | ||
| Install the package in `editable` mode so you can modify the source directly: | ||
|
|
||
| pip install -e . | ||
|
|
||
| To add new dependencies, simply add them to the setup.py. | ||
|
|
||
| ### Setup pre-commit hooks: | ||
| These hooks will: | ||
| * validate flake8 before any commit | ||
| * check that jupyter notebook outputs have been stripped | ||
|
|
||
| cd .git/hooks/ && ln -s ../../hooks/pre-commit . | ||
|
|
||
| ### Setup Continuous Integration | ||
|
|
||
| Continuous integration will run the following: | ||
| - Unit tests under `tests`. | ||
| - End-to-end test under `exmaples/local`. | ||
| - `flake8` to check the code syntax. | ||
| - Checks on documentation presence and format (using `sphinx`). | ||
|
|
||
| We support the GitHub Actions for running CI. | ||
|
|
||
| Github actions are already configured in `.github/workflows/tests.yml`. | ||
| Github actions are already enabled by default when using Github, so, when | ||
| pushing to github, they will be executed automatically for pull requests to | ||
| `main` and to `develop`. | ||
|
|
||
| ## Running the code | ||
|
|
||
| ### Run the tests | ||
| Just run (from the root folder): | ||
|
|
||
| pytest | ||
|
|
||
| ### Run the code/examples. | ||
| Note that the code should already compile at this point. | ||
|
|
||
| Running examples can be found under the `examples` folder. | ||
|
|
||
| In particular, you will find examples for: | ||
| * local machine (e.g., your laptop). | ||
| * a slurm cluster. | ||
|
|
||
| For both these cases, there is the possibility to run with or without Orion. | ||
| (Orion is a hyper-parameter search tool - see https://github.com/Epistimio/orion - | ||
| that is already configured in this project) | ||
|
|
||
| #### Run locally | ||
|
|
||
| For example, to run on your local machine without Orion: | ||
|
|
||
| cd examples/local | ||
| sh run.sh | ||
|
|
||
| This will run a simple MLP on a simple toy task: sum 5 float numbers. | ||
| You should see an almost perfect loss of 0 after a few epochs. | ||
|
|
||
| Note you have a new `output` folder which contains models and a summary of results: | ||
| * best_model: the best model checkpoint during training | ||
| * last_model: the last model checkpoint during training | ||
| * lightning_logs: contains the tensorboard logs. | ||
|
|
||
| To view tensorboard logs, simply run: | ||
|
|
||
| tensorboard --logdir output | ||
|
|
||
| #### Run on a remote cluster (with Slurm) | ||
|
|
||
| First, bring you project on the cluster (assuming you didn't create your | ||
| project directly there). To do so, simply login on the cluster and git | ||
| clone your project: | ||
|
|
||
| git clone [email protected]:${GITHUB_USERNAME}/${PROJECT_NAME}.git | ||
|
|
||
| Then activate your virtual env, and install the dependencies: | ||
|
|
||
| cd amlrt_project | ||
| pip install -e . | ||
|
|
||
| To run with Slurm, just: | ||
|
|
||
| cd examples/slurm | ||
| sh run.sh | ||
|
|
||
| Check the log to see that you got an almost perfect loss (i.e., 0). | ||
|
|
||
| #### Measure GPU time (and others) on the Mila cluster | ||
|
|
||
| You can track down the GPU time (and other resources) of your jobs by | ||
| associating a tag to the job (when using `sbatch`). | ||
| To associate a tag to a job, replace `my_tag` with a proper tag, | ||
| and uncomment the line (i.e., remove one #) from the line: | ||
|
|
||
| ##SBATCH --wckey=my_tag | ||
|
|
||
| This line is inside the file `examples/slurm_mila/to_submit.sh`. | ||
|
|
||
| To get a sumary for a particular tag, just run: | ||
|
|
||
| sacct --allusers --wckeys=my_tag --format=JobID,JobName,Start,Elapsed -X -P --delimiter=',' | ||
|
|
||
| (again, remember to change `my_tag` into the real tag name) | ||
|
|
||
| #### GPU profiling on the Mila cluster | ||
|
|
||
| It can be useful to monitor and profile how you utilise your GPU (usage, memory, etc.). For the | ||
| time being, you can only monitor your profiling in real-time from the Mila cluster, i.e. while your | ||
| experiments are running. To monitor your GPU, you need to setup port-forwarding on the host your | ||
| experiments are running on. This can be done in the following way: | ||
|
|
||
| Once you have launched your job on the mila cluster, open the log for your current experiment: | ||
|
|
||
| `head logs/amlrt_project__<your_slurm_job_id>.err` | ||
|
|
||
| You should see printed in the first few lines the hostname of your machine, e.g., | ||
|
|
||
| ``` | ||
| INFO:amlrt_project.utils.logging_utils:Experiment info: | ||
| hostname: leto35 | ||
| git code hash: a51bfc5447d188bd6d31fac3afbd5757650ef524 | ||
| data folder: ../data | ||
| data folder (abs): /network/tmp1/bronzimi/20191105_cookiecutter/amlrt_project/examples/data | ||
| ``` | ||
|
|
||
| In a separate shell on your local computer, run the following command: | ||
|
|
||
| `ssh -L 19999:<hostname>.server.mila.quebec:19999 <username>@login.server.mila.quebec -p 2222` | ||
|
|
||
| where `<username>` is your user name on the Mila cluster and `<hostname>` is the name of the machine your job is currenty running on (`leto35` in our example). You can then navigate your local browser to `http://localhost:19999/` to view the ressources being used on the cluster and monitor your job. You should see something like this: | ||
|
|
||
| 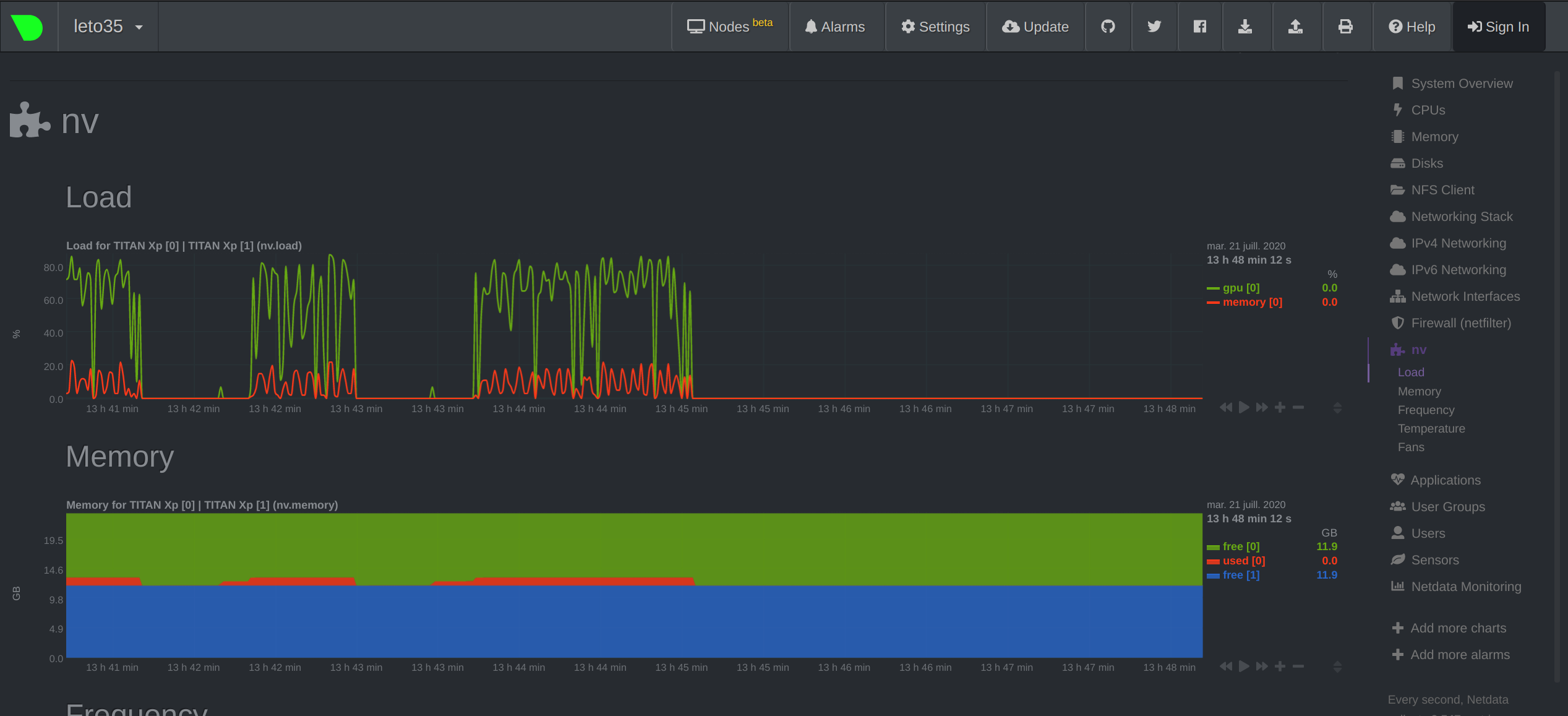 | ||
| {%- endif %} | ||
|
|
||
| #### Run with Orion on the Slurm cluster | ||
|
|
||
| This example will run orion for 2 trials (see the orion config file). | ||
| To do so, go into `examples/slurm_orion`. | ||
| Here you can find the orion config file (`orion_config.yaml`), as well as the config | ||
| file (`config.yaml`) for your project (that contains the hyper-parameters). | ||
|
|
||
| In general, you will want to run Orion in parallel over N slurm jobs. | ||
| To do so, simply run `sh run.sh` N times. | ||
|
|
||
| When Orion has completed the trials, you will find the orion db file. | ||
|
|
||
| You will also find the output of your experiments in `orion_working_dir`, which | ||
| will contain a folder for every trial. | ||
| Inside these folders, you can find the models (the best one and the last one), the config file with | ||
| the hyper-parameters for this trial, and the log file. | ||
|
|
||
| You can check orion status with the following commands: | ||
| (to be run from `examples/slurm_orion`) | ||
|
|
||
| export ORION_DB_ADDRESS='orion_db.pkl' | ||
| export ORION_DB_TYPE='pickleddb' | ||
| orion status | ||
| orion info --name my_exp | ||
|
|
||
| ### Building docs: | ||
|
|
||
| Documentation is built using sphinx. It will automatically document all functions based on docstrings. | ||
| To automatically generate docs for your project, navigate to the `docs` folder and build the documentation: | ||
|
|
||
| cd docs | ||
| make html | ||
|
|
||
| To view the docs locally, open `docs/_build/html/index.html` in your browser. | ||
|
|
||
|
|
||
| ## YOUR PROJECT README: | ||
|
|
||
| * __TODO__ |
File renamed without changes.
File renamed without changes.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.