Neighborhood Graph and Tree for Indexing High-dimensional Data
トップ / インストール / コマンド / ライセンス / 関連文献 / About Us / English
大量(数百万から数千万)の高次元ベクトルデータ(数十~数千次元)に対して高速な近似近傍検索を可能とするコマンド及びライブラリを提供します。
- 2019/11/04 NGT チュートリアル をリリースしました。
- 2019/06/26 Jaccard距離が利用可能になりました。(v1.7.6)
- 2019/06/10 PyPI NGT パッケージ v1.7.5 が利用可能になりました。
- 2019/01/17 Python NGTはPYPIからpipでインストールが可能になりました。(v1.5.1)
- 2018/12/14 NGTQ (NGT with Quantization) が利用可能になりました。(v1.5.0)
- 2018/08/08 ONNGが利用可能になりました。(v1.4.0)
- OS:Linux、macOS
- データの追加削除が可能
- 共有メモリ(マップドメモリ)のオプションによるNGTではメモリサイズを超えるデータが利用可能
- データ型:1バイト整数、4バイト単精度浮動小数点
- 距離関数:L1、L2、コサイン類似度、角度、ハミング、ジャッカード
- 対応言語:Python、Ruby、Go、C、C++
- 分散サーバ:ngtd, vald
- 量子化版NGT(NGTQ)は10億ものデータの検索が可能
$ brew install ngt
$ unzip NGT-x.x.x.zip
$ cd NGT-x.x.x
$ mkdir build
$ cd build
$ cmake ..
$ make
$ make install
$ ldconfig /usr/local/lib
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
$ brew install cmake
$ brew install gcc@9
$ export CXX=/usr/local/bin/g++-9
$ export CC=/usr/local/bin/gcc-9
$ unzip NGT-x.x.x.zip
$ cd NGT-x.x.x
$ mkdir build
$ cd build
$ cmake ..
$ make
$ make install
メモリマップドファイルを用いた共有メモリにインデックスを配置することが可能です。共有メモリを利用することにより複数のプロセスが同一のインデックスを利用する場合にメモリ使用量を抑制することが可能です。さらに、メモリにロードできないような大量のオブジェクトを有するインデックスを扱うことが可能なだけでなく、インデックスをオープンする時間を削減することも可能です。共有メモリを利用するにはビルド時の変更が必要となりますので、cmake実行時に以下のパラメータを追加してください。
$ cmake -DNGT_SHARED_MEMORY_ALLOCATOR=ON ..
注:ロック機能はありませんので、複数プロセスで同一のインデックスを利用する場合には参照のみでご使用ください。
約500万以上のオブジェクトを登録する場合には、検索速度向上のために以下のパラメータを追加してください。
$ cmake -DNGT_LARGE_DATASET=ON ..
- Python
- Ruby (Thanks Andrew!)
- Go
- C
- C++(sample code)
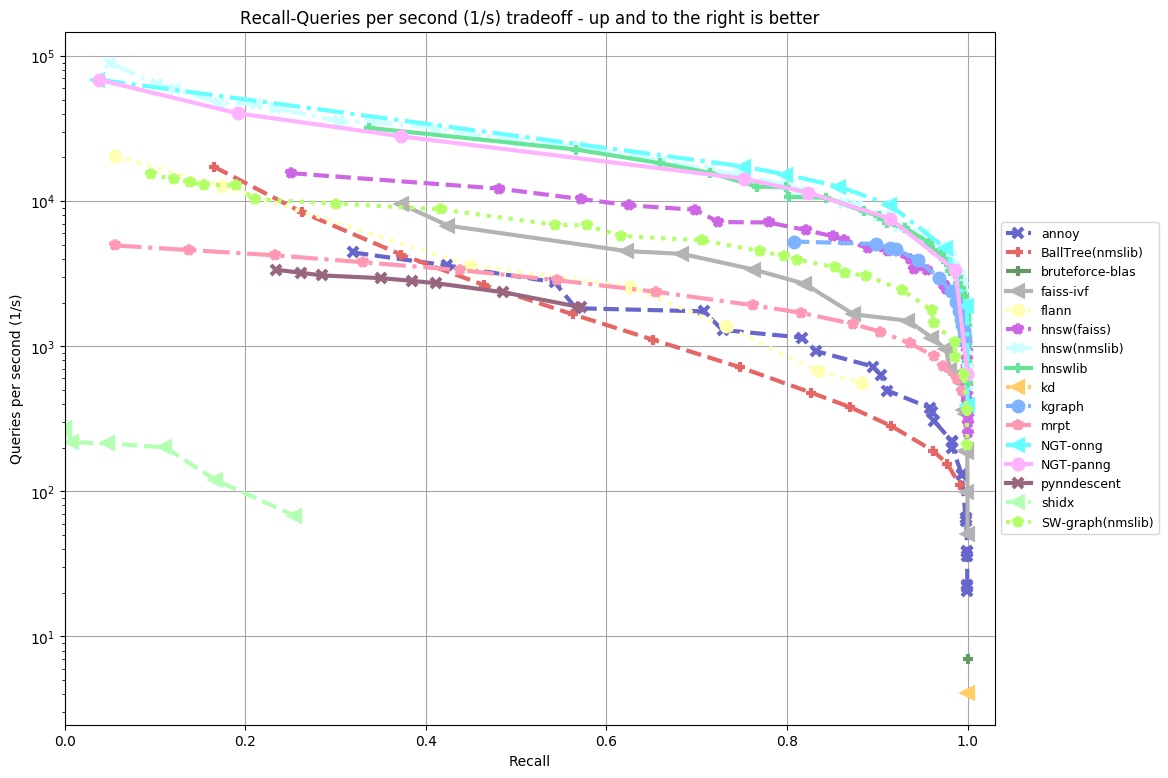
以下はAWS c5.4xlargeのインスタンス上で測定したNGT v1.7.5のベンチマーク(ann benchmarks)の結果です。




Copyright (C) 2015-2020 Yahoo Japan Corporation
ヤフー株式会社はApacheライセンスバージョン2.0の下で本ソフトウェアを公開致します。以下のサイトよりライセンスの内容をご確認頂けます。
http://www.apache.org/licenses/LICENSE-2.0
ヤフー株式会社は本ソフトウェアが利用している技術の特許権を取得しています。ただし、本ソフトウェアを介して権利化された技術を利用する場合に限り、Apacheライセンスバージョン2.0の下で特許権が行使されることはありません。
本ソフトウェアへのソースコードのご提供者は貢献者ライセンスに同意して頂きます。
なお、GitHub (https://github.com/yahoojapan/NGT) へのご提供の場合のみ、個別の同意書面なしに、上記貢献者ライセンスに同意して頂いたと見なしますので、ご注意ください。
- Iwasaki, M., Miyazaki, D.: Optimization of Indexing Based on k-Nearest Neighbor Graph for Proximity. arXiv:1810.07355 [cs] (2018). (pdf)
- Iwasaki, M.: Pruned Bi-directed K-nearest Neighbor Graph for Proximity Search. Proc. of SISAP2016 (2016) 20-33. (pdf)
- Sugawara, K., Kobayashi, H. and Iwasaki, M.: On Approximately Searching for Similar Word Embeddings. Proc. of ACL2016 (2016) 2265-2275. (pdf)
- Iwasaki, M.: Applying a Graph-Structured Index to Product Image Search (in Japanese). IIEEJ Journal 42(5) (2013) 633-641. (pdf)
- Iwasaki, M.: Proximity search using approximate k nearest neighbor graph with a tree structured index (in Japanese). IPSJ Journal 52(2) (2011) 817-828. (pdf)
- Iwasaki, M.: Proximity search in metric spaces using approximate k nearest neighbor graph (in Japanese). IPSJ Trans. on Database 3(1) (2010) 18-28. (pdf)