TreeMix: Compositional Constituency-based Data Augmentation for Natural Language Understanding (NAACL 2022)
Pytorch Implementation of TreeMix
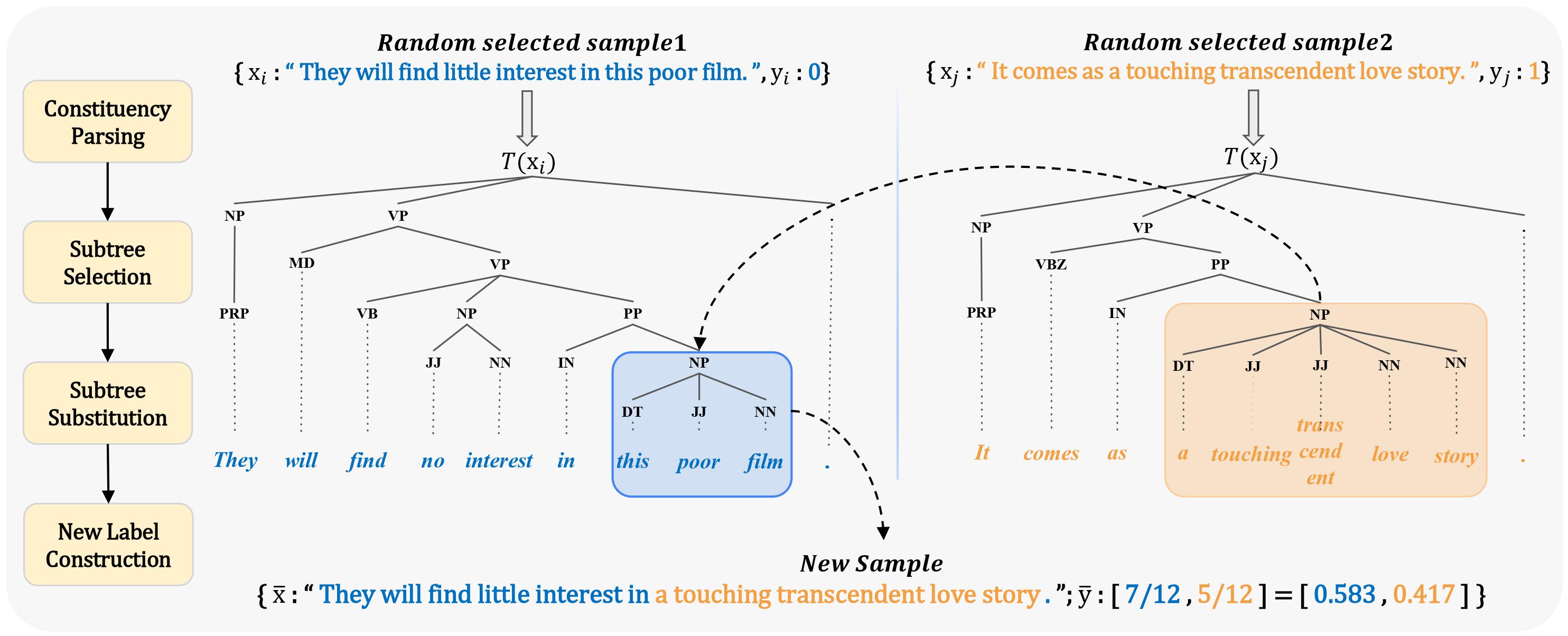
Data augmentation is an effective approach to tackle over-fitting. Many previous works have proposed different data augmentations strategies for NLP, such as noise injection, word replacement, back-translation etc. Though effective, they missed one important characteristic of language–compositionality, meaning of a complex expression is built from its subparts. Motivated by this, we propose a compositional data augmentation approach for natural language understanding called TreeMix. Specifically, TreeMix leverages constituency parsing tree to decompose sentences into constituent sub-structures and the Mixup data augmentation technique to recombine them to generate new sentences. Compared with previous approaches, TreeMix introduces greater diversity to the samples generated and encourages models to learn compositionality of NLP data. Extensive experiments on text classification and semantic parsing benchmarks demonstrate that TreeMix outperforms current stateof-the-art data augmentation methods.
|__ DATA
|__ SST2
|__ data
|__ train.csv --> raw train dataset
|__ test.csv --> raw test dataset
|__ train_parsing --> consituency parsing results
|__ generated
|__ times2_min0_seed0_0.3_0.1_7k --> augmentation dataset(hugging face dataset format) with 2 times bigger, seed 0, lambda_L=0.1, lambda_U=0.3, total size=7k
|__ logs --> best results log
|__ runs --> tensorboard results
|__ aug --> augmentation only baseline
|__ raw --> standard baseline
|__ raw_aug --> TreeMix results
|__ checkpoints
|__ best.pt --> Best model checkpoints
|__ process_data / --> Download & Semantic parsing using Stanfordcorenlp tooktiks
|__ Load_data.py --> Loading raw dataset and augmentation dataset
|__ get_data.py --> Download all dataset from huggingface dataset and perform constituency parsing to obtain processed dataset
|__ settings.py --> Hyperparameter settings & Task settings
|__ online_augmentation
|__ __init__.py --> Random Mixup
|__ Augmentation.py --> Subtree Exchange augmentation method based on consituency parsing results for all dataset(single sentence classification, sentence relation classification, SCAN dataset)
|__ run.py --> Train for one dataset
|__ batch_train.py -> Train with different datasets and different settings, specified by giving specific arguments
pip install -r requirements.txt
Note that to successfully run TreeMix, you must install stanfordcorenlp. Please refer to this
corenlp for more information.
cd process_data
python get_data.py --data {DATA} --corenlp_dir {CORENLP}
DATA indicates the dataset name, CORENLP indicates the directory of stanfordcorenlp . After this process, you could get corresponding data folder in DATA/ and train_parsing.csv.
python Augmentation.py --data {DATASET} --times {TIMES} --lam1 {LAM1} --lam2 {LAM2} --seeds {SEEDS}
Augmentation with different arguments, will generate #(TIMES)×#(SEEDS) extra dataset. DATASET could be list of data name such as 'sst2 rte', since 'trec' has two versions, you need to input --label_name {} to specify whether the trec-fine or trec-coarse set. Besides, by typing --low_resource , it will generated partial augmentation dataset as well as partial train set. You can modify the hyperparameter lambda_U and lambda_L by changing LAM1 and LAM2 . TIMES could be a list of intergers such as 2,5 to assign the size of the augmentation dataset.
python batch_train.py --mode {MODE} --data {DATASET}
Evaluation one dataset for all its augmenation set with specific mode. MODE can be 'raw', 'aug', 'raw_aug', which indicates train the model with raw dataset only, augmentation dataset only and combination of raw and augmentation set respectively. DATASET should be one specific dataset name. This will report all results of a specifc dataset in /log. If not specified, the hyperparameters will be set as in /process_data/settings.py, please look into this file for more arguments information.