A personal project for analyzing given data from 3 hospitals and plotting necessary statistics. This project involves usage of libraries such as Pandas, Matplotlib and Numpy to process and plot data based on the given information from three hospitals:
- General
- Prenatal
- Sports
The CSV files for the 3 hospitals are in the 'test' folder of the repository.
Files in the test folder are loaded into the script using read_csv() method of the pandas module. The following are 20 random lines of data from the files.




Once the dataset is ready, it is time to process it. To do that, the first step is handling NaN (Not a Number) values.
- Delete all the empty rows.
- Replace the NaN values in the gender column of the prenatal hospital with f (we can assume that the prenatal treats only women).
- Replace the NaN values in the bmi, diagnosis, blood_test, ecg, ultrasound, mri, xray, children, months columns with zeroes.
Once the NaN values are handled, values are corrected and normalized. Let's take a closer look at the gender column. It's a big mess: there we have female, male, man, woman. The data in this colum needs to be corrected. The values should be either f or m. The improvised dataset is shown below. Once again, 20 random lines of data were extracted from the merged and corrected dataset.

The dataset has been cleared of empty rows and values. Some values have also been corrected, and now we can start a comprehensive study of our data. In this stage, we will find the main statistical characteristics of our data, consider data distributions, and so on.
These questions will be answered using statistical methods:
-
Which hospital has the highest number of patients?
Using mode() function, hospital with the highest number of patients is extracted.
-
What share of the patients in the general hospital suffers from stomach-related issues? Round the result to the third decimal place?
Using .loc to locate and filter required data from general hospital and round off value
-
What share of the patients in the sports hospital suffers from dislocation-related issues? Round the result to the third decimal place?
Using .loc to locate and filter required data from sports hospital and round off value
-
What is the difference in the median ages of the patients in the general and sports hospitals?
Using median() method to compare.
-
After data processing at the previous stages, the blood_test column has three values: t= a blood test was taken, f= a blood test wasn't taken, and 0= there is no information. In which hospital the blood test was taken the most often? How many blood tests were taken?
Creating a pivot table with values='blood_test' aggfunc='count' to find the hospital with the most blood tests.

Graphics are arguably the most accessible way to represent the data and its structure. Sometimes, it can help to find the main data patterns and deviations. We will use data visualization methods to conclude our dataset.
The following graphs will be plotted and the questions will be answered:
-
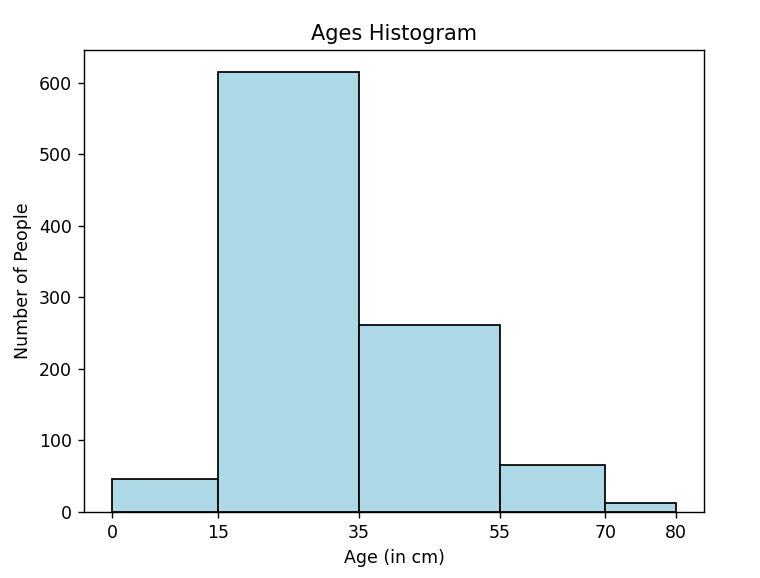
What is the most common age of a patient among all hospitals? Plot a histogram and choose one of the following age ranges: 0-15, 15-35, 35-55, 55-70, or 70-80.
From the plotted histogram, it was found that 15-35 was the most common age group.
-
What is the most common diagnosis among patients in all hospitals? Create a pie chart.
From the generated pie chart, it was found that pregnancy is the most common diagnosis.
-
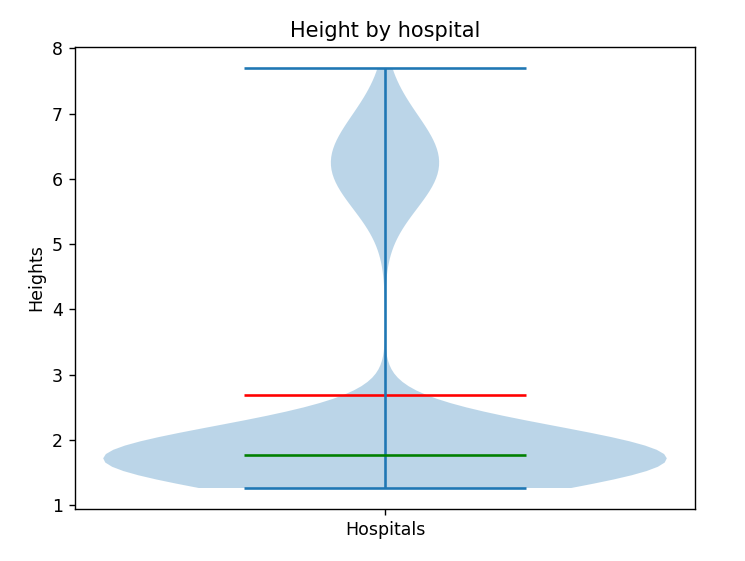
Build a violin plot of height distribution by hospitals. What is the main reason for the gap in values? Why there are two peaks, which correspond to the relatively small and big values?
The gap between values is due to the presence of athletes in the sports hospital who generally tend to be taller than the general population, and that other hospitals even include children, which shifts the curve even more. The presence of two peaks is due to the use of two different measurement systems. The height in both prenatal and general is measured in meters (m), while the sports hospital uses feet (ft), where 1 foot is 0.3048 meters.