
- Course: CS315 Algorithm Design and Analysis
- Project: Implementing and analyzing two algorithms (naive and optimized) for calculating the Jaccard similarity between two texts.
The objective of this project is to implement two approaches to calculate the Jaccard Similarity between two sets of words from different texts:
- Naive Algorithm: A simple, brute-force approach to compute the Jaccard similarity.
- Optimized Algorithm: A more efficient solution with improvements in time complexity.
Jaccard similarity is a measure used to compare the similarity between two sets. It is defined as the size of the intersection divided by the size of the union of the sets:
J(A, B) = |A ∩ B| / |A ∪ B|
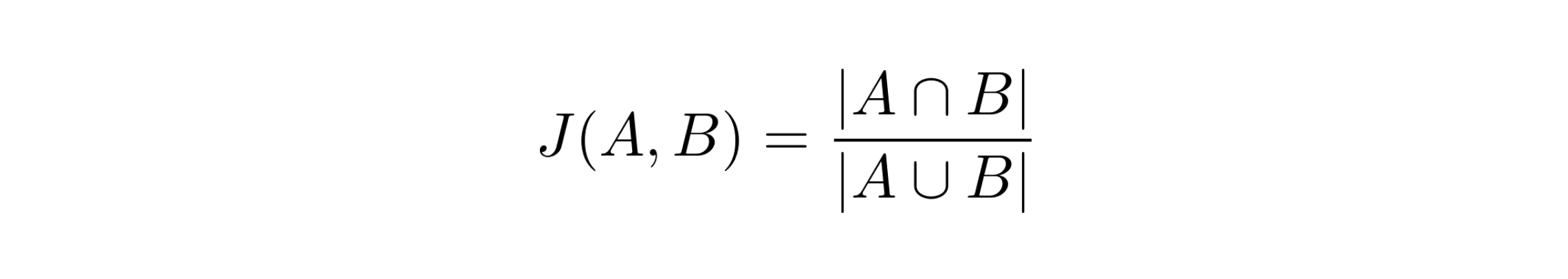
Where:
- ( A ) and ( B ) are two sets of words (i.e., tokens) extracted from the texts.
-
Naive Algorithm:
- This algorithm directly computes the union and intersection of two sets of words.
- Time complexity: (O(n^2)).
-
Optimized Algorithm:
- The optimized approach uses more efficient data structures (hashes) to reduce the time complexity.
- Time complexity: (O(n)).
- Two texts (represented as strings or lists of words) for which the similarity is to be calculated.
- A numeric value representing the Jaccard similarity between the two texts.
- Compare the time complexity and performance of both algorithms.
- Analyze the trade-offs between simplicity (naive approach) and efficiency (optimized approach).
- Gain practical experience in implementing and analyzing algorithms in Python.
algorithm1.py: Contains the naive implementation of Jaccard Similarity.algorithm2.py: Contains the optimized implementation of Jaccard Similarity.- Sample Text Files:
smallSample_a.txt,smallSample_b.txtmediumSample_a.txt,mediumSample_b.txtlargeSample_a.txt,largeSample_b.txt
- Clone the repository.
- Run
algorithm1.pyto execute the naive Jaccard Similarity algorithm on the text files. - Run
algorithm2.pyto execute the optimized Jaccard Similarity algorithm on the text files. - Compare the results and performance using the provided sample data.
Both scripts will read the input text files and output the Jaccard Similarity score for each pair of text samples.
If the script encounters a FileNotFoundError or path issue, follow these steps to resolve the problem:
-
Modify the
base_pathVariable:Open the Python file (
algorithm1.pyoralgorithm2.py) and locate the variablebase_path. This variable should hold the directory path where your text files are stored.Example: base_path = "C:\\path\\to\\CS315_Project\\" # Insert your actual path here
-
Leave
base_pathEmpty If Not Needed:If your script and the text files are in the same folder, you can leave the
base_pathvariable as an empty string:base_path = ""
This project was collaboratively developed by:
-
Muhannad Majed
GitHub: @iMD10 -
Mohammed Saleh
GitHub: @rayq-q -
Mohammed Mansour
GitHub: @MrM3ROF -
Eyad Fahad
GitHub: @commando-xxt