-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
189 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,189 @@ | ||
| --- | ||
| layout: post | ||
| title: "基本时间戳顺序并发控制协议" | ||
| date: 2024-02-10 00:00:00 +000 | ||
| categories: 分布式存储系统设计与实现 | ||
| --- | ||
|
|
||
| 介绍基本时间戳顺序并发控制协议核心思路、实现方法以及该协议所具备的特性。 | ||
|
|
||
| 关键词:乐观并发控制协议、基本时间戳顺序、冲突可串行化、级联回滚、不可恢复调度序列 | ||
|
|
||
| ## 基本时间戳顺序协议(Basic Timestamp Ordering Protocol) | ||
|
|
||
| 基本时间戳顺序协议归属于“乐观并发控制协议”这一大类,并且是基于时间戳确认顺序的。 | ||
|
|
||
| 该协议的核心思路:每个事务在一开始都会标记一个唯一的时间戳,并且该时间戳是单调递增的。如果时间戳满足 \\(TS(T_i) \lt TS(T_j)\\) ,那么数据库系统会保证并发调度等价于一个串行化调度,并且该串行化调度序列就是 \\(T_i \rightarrow T_j\\)。也就是说,基于时间戳就能决定事务的串行调度顺序。 | ||
|
|
||
| 每个对象也会标记最新的读写时间戳,分别得到以下两个时间戳数值: | ||
| - W-TS(X): 数据对象 X 的写时间戳,最近一次写入的事务的时间戳 | ||
| - R-TS(X): 数据对象 X 的读时间戳,最近一次读取的事务的时间戳 | ||
|
|
||
| 事务读写对象不需要提前申请锁资源,而是依据时间戳来判断“能否读写”。任何事务访问(读或者写)数据对象的时候,都会检测时间戳大小关系。只要这个数据对象对该事务来说属于**未来的信息**,那么它就会被终止并重启。 | ||
|
|
||
| **(1)读取操作:** | ||
|
|
||
| 一个数据对象的写时间戳 W-TS(X) 大于事务的时间戳 \\(TS(T_i)\\),那么该对象对于本事务而言,就属于未来信息,不能直接读取。 | ||
|
|
||
| - 如果 TS(\\(T_i\\)) < W-TS(X), | ||
| - 那么 \\(T_i\\) 将被终止并且重启,带上一个新时间戳(TS) | ||
| - 否则, | ||
| - 允许 \\(T_i\\) 读取对象 X | ||
| - 拷贝数据对象 X 到事务的本地空间,确保事务的重复读 | ||
| - 同时将数据对象 X 上读时间戳更新为 max(R-TS(X), TS(\\(T_i\\))) | ||
|
|
||
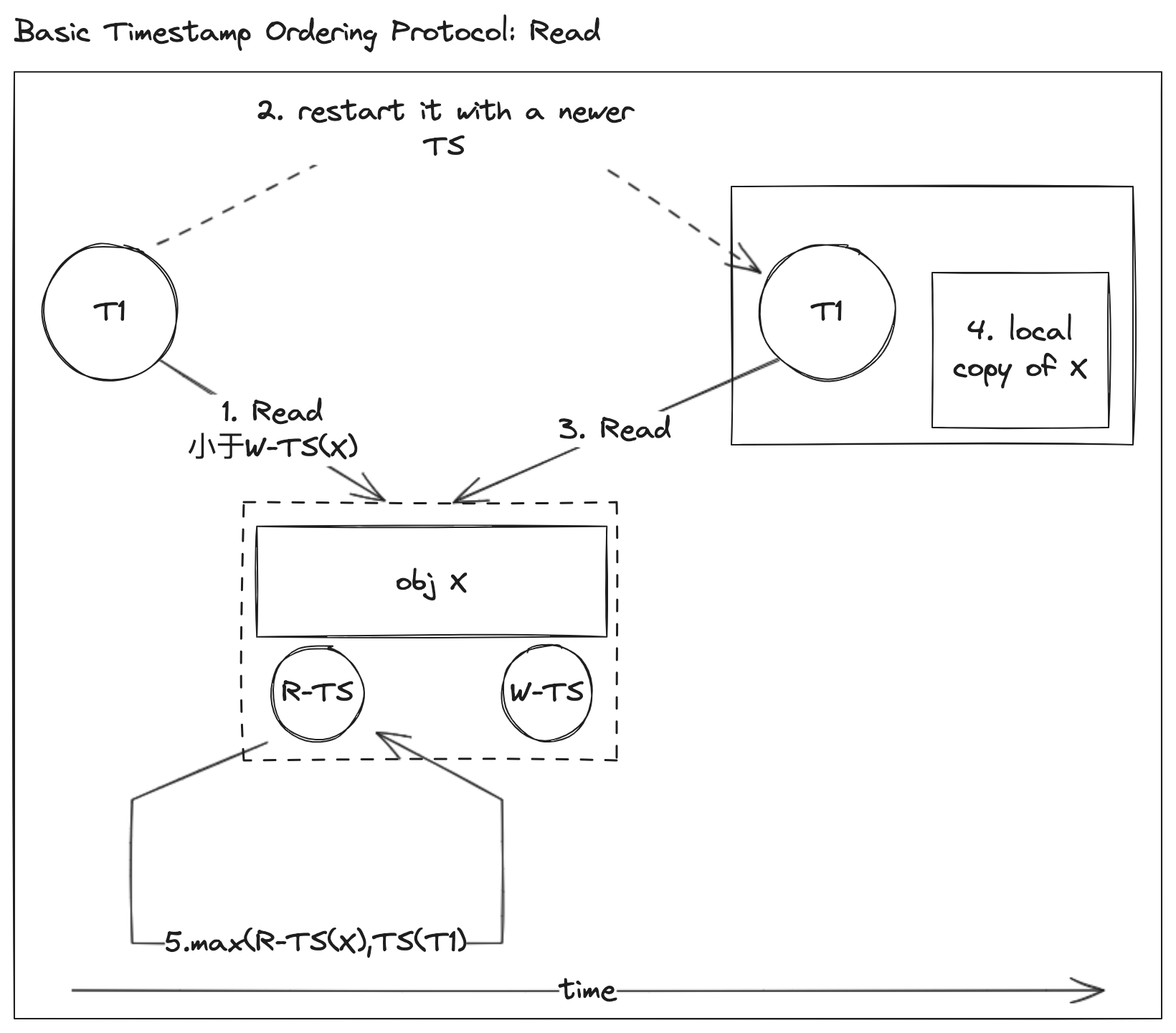
| 查看以下示例: | ||
| 1. 事务 T1 尝试读取数据对象 X,但是小于数据对象 X 写时间戳 W-TS(X),那么 T1 不能读取该数据对象,需要重启 | ||
| 2. 重启的事务 T1,会标记一个新的当前时间戳,重新执行 | ||
| 3. 此时事务 T1 的时间戳会大于数据对象 X 的写时间戳 W-TS(X) | ||
| 4. 判定可以读取后,会复制数据到私有空间,确保整个事务生命周期内都读取到相同的数据 | ||
| 5. 同时,将数据对象 X 的读时间戳更新为事务的时间戳: `max(R-TS(X), TS(T1))` 。 | ||
|
|
||
|  | ||
|
|
||
| - 失败重启事务后要赋值一个新的时间戳: | ||
| - 一个新的 TS 是必须的,要不然 T1 永远不可能成功。那么一个做法是,重启事务取新的时间戳再读取,只要在新时间戳之后该数据对象没有被更新,那么新的这次操作必然是能成功的。 | ||
| - max(R-TS(X), TS(\\(T_i\\))) 是为了确保,对象的读时间戳单调递增: | ||
| - 因为读取操作只会判断跟数据对象的写时间戳之间的关系,所以当前事务并不清楚是否有别的事务对该数据对象也进行了读取操作。比如,还有事务 T2 也读取了数据对象 X,时间戳比 T1 要大。因为事务 T1 和事务 T2 都大于 W-TS(X),两个事务都允许读取,那么可能是 T2 先读取了,然后才是 T1。也就是说此时,数据对象的 R-TS(X) 已经大于事务 T1 的时间戳,这时候要保证数据对象的时间戳单调递增,那么自然需要 `max` 操作。 | ||
| - 拷贝该对象到事务的本地空间,是为了保证可重复读: | ||
| - 这一步也很重要,一个事务有两次读取,那么第二次读取就可能因为中间有别的事务更改了数据导致失败。当然强制重启,全部从头开始执行,这也是一种方案。但是问题也很明显,很容易让读取的事务陷入饥饿状态,不断重启。更好的处理方式是在事务的私有空间中存储数据对象 X,这样后续的读取,就可以直接使用这个缓存数据。 | ||
|
|
||
| **(2)写入操作:** | ||
|
|
||
| 一个数据对象的读时间戳或者写时间戳比它自带的时间戳大,那么该数据对象对于本事务而言,就属于“未来信息”。要去更新一个这样的信息,不被允许,会被拒绝。 | ||
|
|
||
| - 如果 \\(TS(T_i) < R-TS(X)\\) 或者 \\(TS(T_i) \lt W-TS(S)\\) , | ||
| - 终止并重启事务 \\(T_i\\) ,同时标记一个新的时间戳 | ||
| - 否则, | ||
| - 允许 \\(T_i\\) 写入数据对象 X | ||
| - 拷贝该对象到事务的本地空间,保证可重复读 | ||
| - 同时更新数据对象 X 的写时间戳 W-TS(X) 为 TS(\\(T_i\\)) | ||
|
|
||
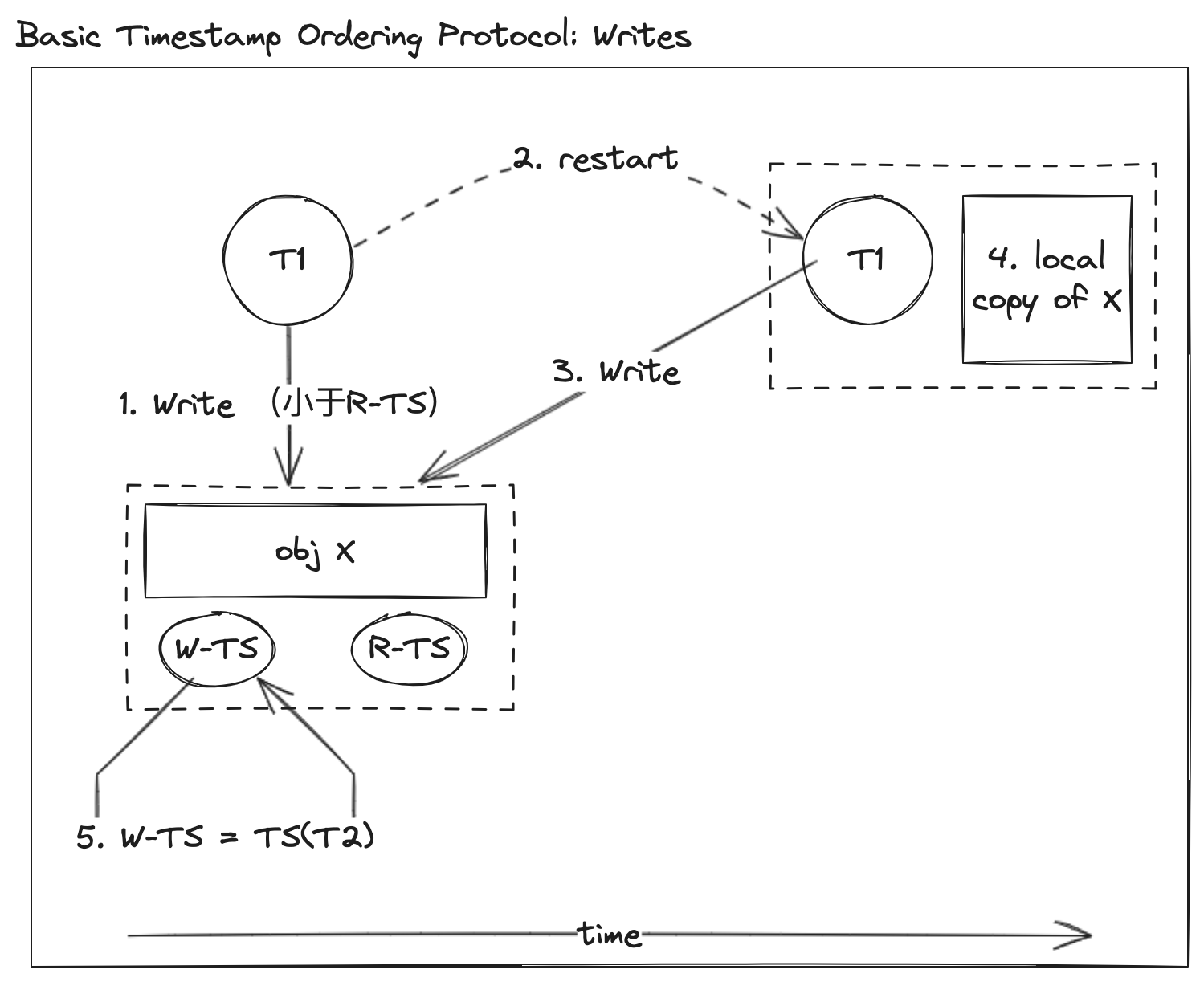
| 查看以下示例: | ||
| 1. 事务 T1 写入数据对象 X,但是小于该数据对象读时间戳 R-TS(X) ,那么事务 T1 终止重启 | ||
| 2. 重启后,带上新的时间戳再执行 | ||
| 3. 事务 T1 写入数据对象 X,大于该数据对象的写时间戳 W-TS(X)以及读时间戳 R-TS(X),那么事务 T1 可以执行,更改数据 | ||
| 4. 再拷贝该对象 X 到事务的本地空间,确保事务的重复读 | ||
| 5. 更新数据对象 X 的写时间戳 W-TS = \\(TS(T_2)\\) | ||
|
|
||
|  | ||
|
|
||
| - 为什么还要限制和读时间戳的关系,即要求 \\(TS(T_i) \ge\\) R-TS(X) : | ||
| - 如果 TS(\\(T_i\\)) < R-TS(X),说明在事务 \\(T_i\\) 写入 之前已经有别的事务(记做 \\(T_j\\))读取了该数据对象,并且 \\(TS(T_j) \gt TS(T_i)\\)。此时,不限制读时间戳的关系,允许事务 \\(T_i\\) 做更新,那么事务 \\(T_i\\) 就影响了事务 \\(T_j\\) 的读取结果。如果从冲突操作时序的上来看,因为 \\(TS(T_j) \gt TS(T_i)\\),那么 \\(T_i\\) 的写就应该发生在 \\(T_j\\) 的读和写之前。 | ||
|
|
||
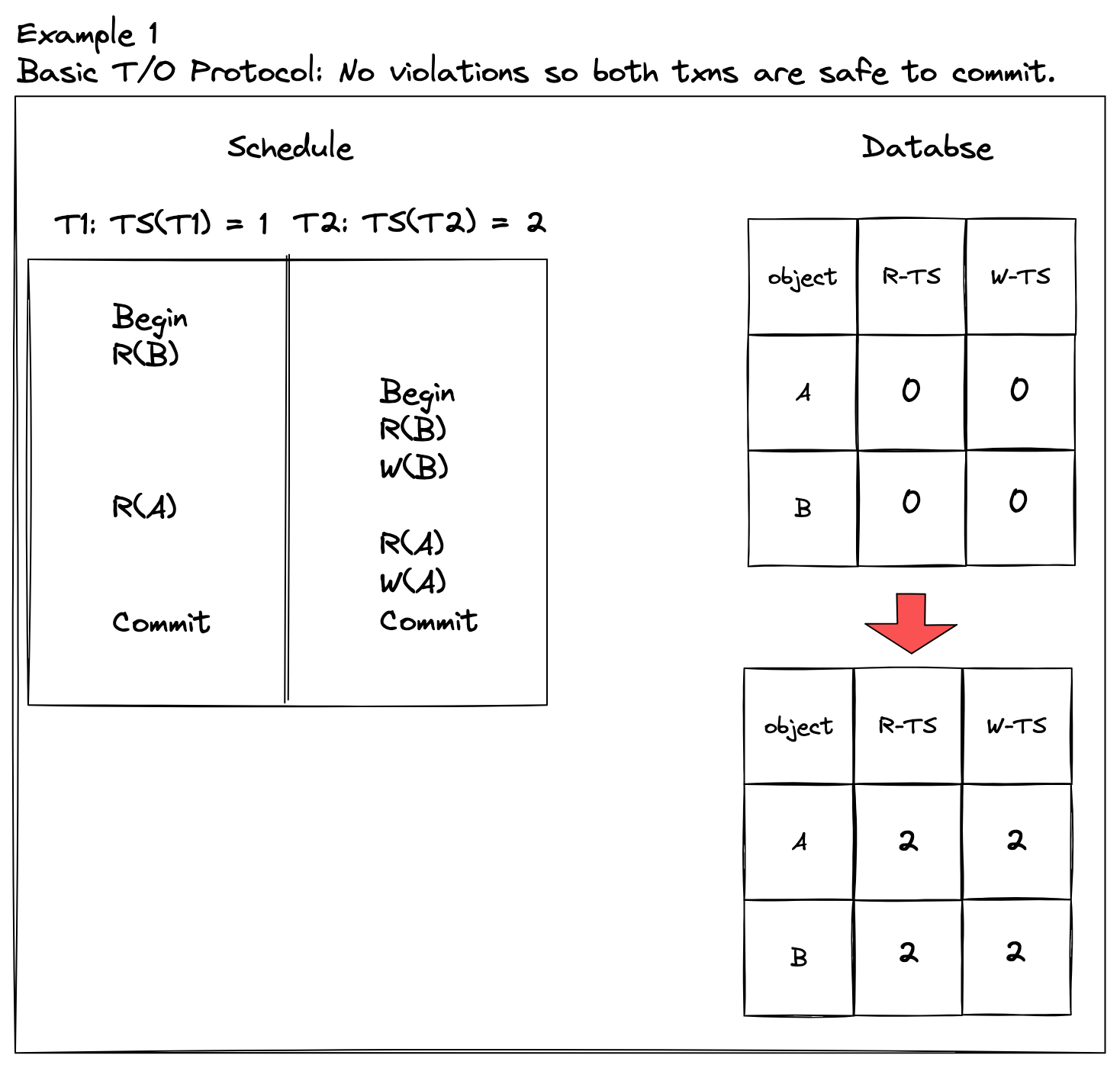
| 查看第一个示例, | ||
|
|
||
| - 事务 T1 的时间戳 TS(\\(T_1\\)) = 1,事务 T2 的时间戳是 TS(\\(T_2\\)) = 2 | ||
| - 数据库数据对象 A 和 B 的初始状态,它们的读时间戳和写时间戳都是 0 | ||
| - \\(R_1(B)\\) 操作,事务 T1 时间戳大于数据对象 B 的写时间戳,可以执行 | ||
| - 读取成功后,此时数据对象 B 的 R-TS 和 W-TS 分别是:1 和 0 | ||
| - \\(R_2(B)W_2(B)\\) 操作,事务 T2 的时间戳大于数据对象 B 的写时间戳,也大于读时间戳,所以这两个操作都能执行 | ||
| - 事务 T2 执行成功后,数据对象 B 的 R-TS 和 W-TS 分别是:2 和 2 | ||
| - 同理地,数据对象 A 也是同样流程,最终数据对象 A 的 R-TS 和 W-TS 也是:2 和 2 | ||
|
|
||
|  | ||
|
|
||
| 可以看出,两个事务虽然是交替调度,其实是冲突等价于串行化调度序列 \\(T1 \rightarrow T2\\) 。 | ||
|
|
||
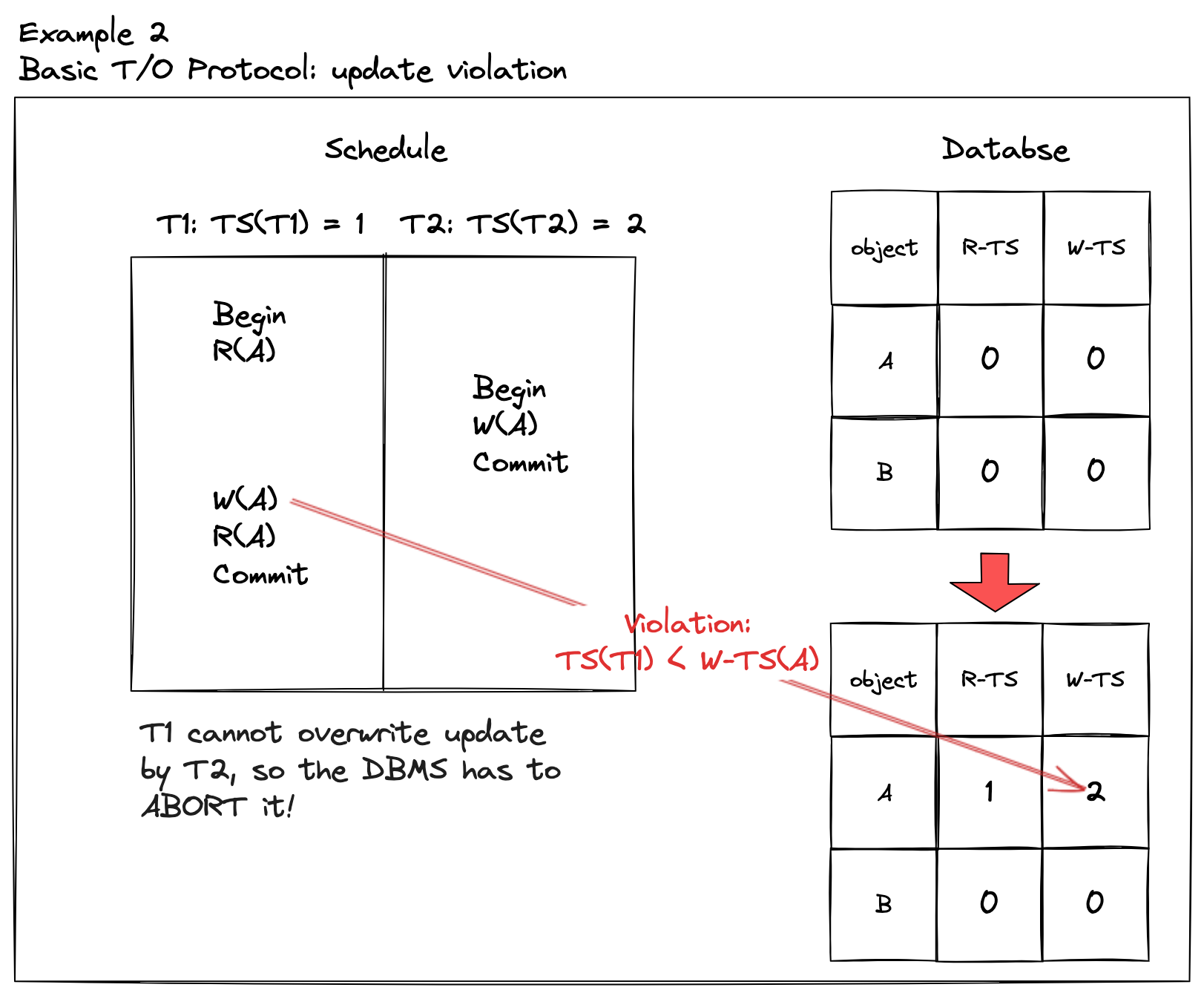
| 再看不满足时间戳关系的示例, | ||
|
|
||
| - 事务 T1 的时间戳 TS(\\(T_1\\)) = 1,事务 T2 的时间戳是 TS(\\(T_2\\)) = 2 | ||
| - 数据库数据对象 A 和 B 的初始状态,它们的读时间戳和写时间戳都是 0 | ||
| - \\(R_1(A)\\) 操作,事务 T1 时间戳大于数据对象 A 的写时间戳,可以执行 | ||
| - 执行成功,数据对象 A 的 R-TS 和 W-TS分别是:1 和 0 | ||
| - \\(W_2(A)\\) 操作,事务 T2 时间戳大于数据对象数据对象 A 的读时间戳和写时间戳,可以执行 | ||
| - 执行成功,数据对象 A 的 R-TS 和 W-TS 分别是:1和2 | ||
| - \\(W_1(A)\\) 操作,事务 T1 再准备写入的时候,其时间戳小于数据对象 A 的写时间戳,被终止 | ||
|
|
||
|  | ||
|
|
||
| 可以看出,冲突操作时序是 \\(W_2(A)W_1(A)\\) 不满足协议所要求的:如果 \\(TS(T_i) \lt TS(T_j)\\) ,那么调度序列是 \\(T_i \rightarrow T_j\\)。在并发调度情况,并不清楚事务 T1 之后会提交什么样的操作,所以当事务 T2 已经执行了写入操作后,那么事务 T1 只能回滚重来,确保最终调度序列是串行化。 | ||
|
|
||
| ## 保证冲突可串行化,并且是冲突等价于时间戳顺序的串行化调度序列 | ||
|
|
||
| 基本时间戳顺序并发控制协议会保证,只要两个事务的时间戳满足 \\(TS(T_i) \lt TS(T_j)\\),那么其并发调度一定会等价于串行化调度,并且该串行化调度序列就是时间戳顺序的 \\(T_i \rightarrow T_j\\) 。 | ||
|
|
||
| 而这里最关键的就是保证两个事务的冲突操作能够满足这一时间戳顺序。如果两个事务没有冲突操作,那么就不会有任何并发问题,他们的顺序无关紧要。 | ||
|
|
||
| 所以,基本时间戳并发控制协议,换一个描述:“该协议会保证,两个事务之间的冲突操作都会按照事务的时间戳顺序来执行,任何违背该顺序的冲突操作所对应的事务都将被回滚。如果 \\(TS(T_i) \lt TS(T_j)\\) ,就要求事务 \\(T_i\\) 的冲突操作一定要在事务 \\(T_j\\) 之前执行,最终每一对冲突操作都将按照 \\(T_i \rightarrow T_j\\) 的顺序执行。” | ||
|
|
||
| 回忆下,“冲突等价”的定义: | ||
| - 涉及相同事务、相同操作,并且 | ||
| - 每对冲突操作都以相同的方式排序 | ||
|
|
||
| 所以,可以说:“基本时间戳顺序并发控制协议,保证冲突可串行化,并且就是要冲突等价于按照时间戳顺序的串行化调度序列:\\(T_i \rightarrow T_j\\)”。 | ||
|
|
||
| 调度序列如下: | ||
|
|
||
| \\[ | ||
| S_1: R_1(A)W_2(A)W_1(A)R_1(A) | ||
| \\] | ||
|
|
||
| - \\(R_1(A)W_2(A)\\) 无法交换 | ||
| - \\(W_2(A)W_1(A)\\) 无法交换 | ||
|
|
||
| 所以, \\(S_1\\) 并不是冲突可串行化。 | ||
|
|
||
| 如果从依赖图的角度去看这个问题,这里出现了死锁。 | ||
|
|
||
| 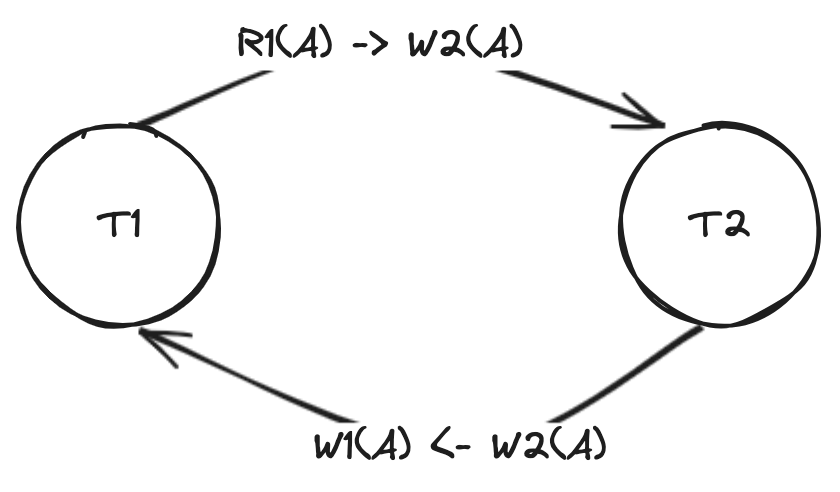 | ||
|
|
||
| 而基本时间戳顺序并发控制协议的做法是,当事务 T1 再提交写操作 \\(W_1(A)\\) 的时候,因为该操作跟 \\(W_2(A)\\) 之间是冲突操作,但是又不满足 T1 要在 T2 之前执行的时间戳顺序,会直接回滚 T1 ,最终事务 T2 执行成功,事务 T1 重新开始。由此也可以看出,基本时间戳顺序并发控制协议是无需处理死锁。 | ||
|
|
||
| ## 无法避免级联回滚 | ||
|
|
||
| 观察一下调度序列,其中 A 代表回滚: | ||
|
|
||
| \\[ | ||
| S_1: R_1(A)W_1(A)R_2(A)W_2(A)R_2(B)W_2(B)A_1 | ||
| \\] | ||
|
|
||
| 事务 T1 和 T2 的时间戳顺序关系是: \\(TS(T_1) \lt TS(T_2)\\) ,所以从时序关系上来看,事务 T2 是可以成功执行 \\(R_2(A)W_2(A)\\)。但是,问题在于事务 T1 并未提交,而是发生回滚:\\(A_1\\) 。这就出了问题,因为事务 T2 已经读取了事务 T1 的执行结果,如果事务 T2 提交了,那么就是基于错误的中间结果执行后续操作。 | ||
|
|
||
| 基础时间戳并发控制协议,要解决上述问题,就只能回滚事务 T2,而事务 T2 的回滚可能会引发别的事务回滚,出现雪崩式回滚场景,严重浪费系统性能。这就是“级联回滚”问题。 | ||
|
|
||
| ## 允许调度序列不可恢复(not recoverable) | ||
|
|
||
| 一个事务它所读取的数据对象,在此之前被其他事务更新了,那么只有在其他事务都提交之后,这一事务再提交,这才叫做可恢复调度。 | ||
|
|
||
| 但是基本时间戳顺序协议,却允许不可恢复的调度序列。查看以下调度序列: | ||
|
|
||
| \\[ | ||
| S1: W_1(A)R_2(A)W_2(B)C2A1 | ||
| \\] | ||
|
|
||
| - 初始状态,事务 T1 时间戳是 1,事务 T2 时间戳是 2 | ||
| - 事务 T1 写数据对象 A,此时数据对象 A 的写时间戳 W-TS(A) = 1 | ||
| - 事务 T2 读取数据对象 A,满足时间戳关系,TS(T2) > W-TS(A) | ||
| - 事务 T2 同样地可以写入数据对象A,并提交 | ||
| - 但是此时事务 T1 回滚了,那就意味着事务 T2 基于一个错误中间结果做了修改,又不能重启 T1,也没办法回滚 T2 | ||
| - 因此,整个调度序列是不可恢复的。 | ||
|
|
||
| 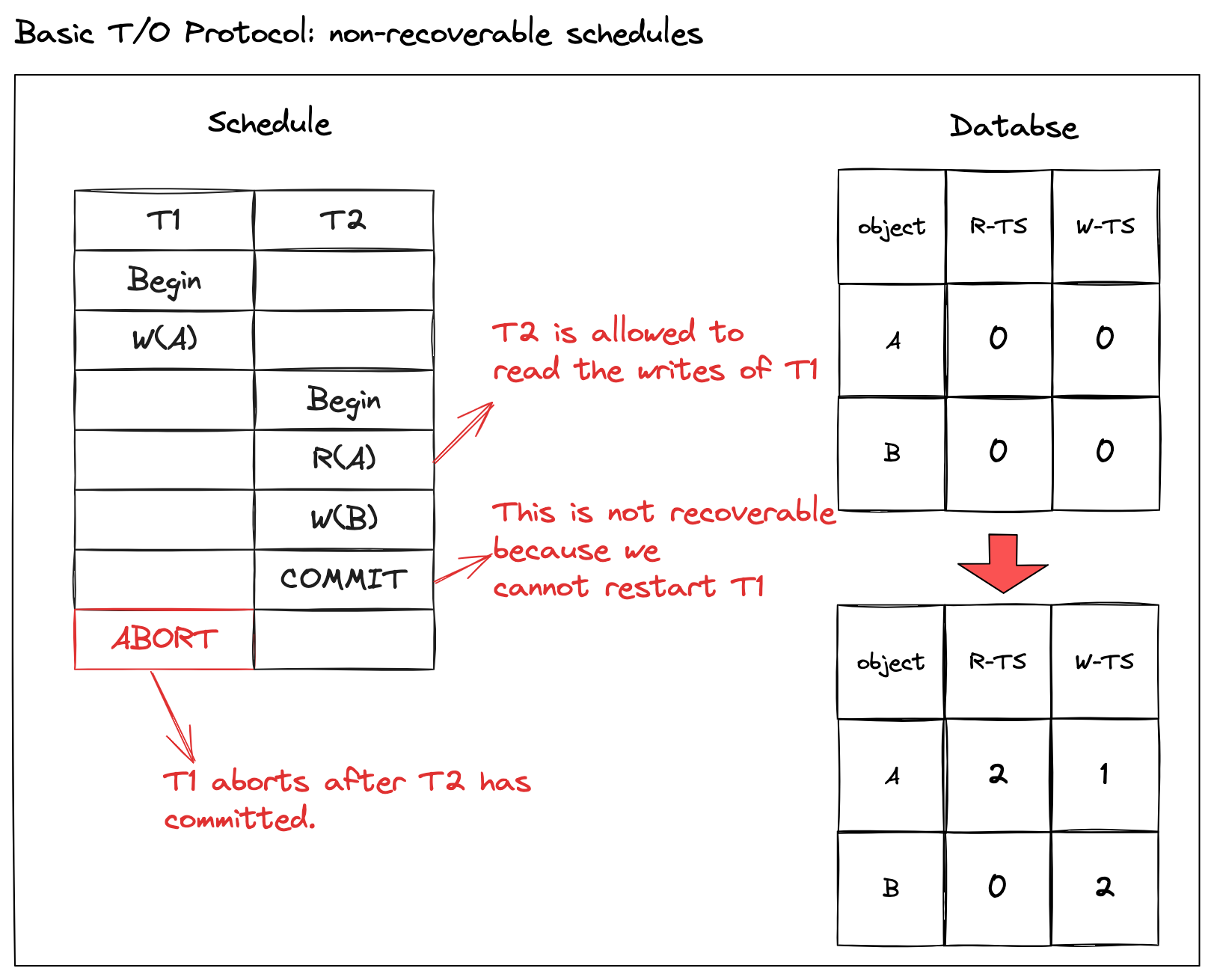 | ||
|
|
||
| 问题的关键:事务 T2 读取了事务 T1 的中间结果,那它就必须在事务 T1 之后提交,这样整个调度序列才能是可恢复的。但是基本时间戳顺序协议允许事务 T2 执行 \\(R_2(A)\\),也不限制它提交,那就导致这一调度序列不可恢复。一旦系统出现故障或者应用层终止,事务 T1 被迫终止。那么哪怕故障恢复,对于已经提交的 T2 来说,也不可能回滚成更改前的状态了。这就是不可恢复的含义。 | ||
|
|
||
| ## 总结 | ||
|
|
||
| 基本时间戳顺序并发控制协议,基于时间戳大小关系已确定事务执行的时序,特别是事务之间冲突操作的执行时序。如果 \\(TS(T_i) \lt TS(T_j)\\),那么该协议确保调度序列冲突等价于串行化调度 \\(T_i \rightarrow T_j\\) 。 | ||
|
|
||
| 具体做法,通过在读写操作的时候,比较时间戳关系,确保总是先到的先执行: | ||
|
|
||
| - 读取操作:要求 \\(TS(T_i) \ge W-TS(X)\\) | ||
| - 写入操作:要求 \\(TS(T_i) \ge R-TS(X)\\) 并且 \\(TS(T_i) \ge W-TS(X)\\) | ||
|
|
||
| 一旦不满足上述关系,就回滚不满足条件的事务(哪怕这个事务的时间戳更小),让其重新执行。 | ||
|
|
||
| 该协议具备以下特性: | ||
| - 所构造出来的调度序列是**冲突可串行化** | ||
| - 不需要处理死锁,因为一旦事务不满足时间戳大小关系,直接回滚重启 | ||
| - 无法避免级联回滚问题 | ||
| - 也不能保证调度序列是可恢复的 | ||
| - 对于长事务来说,会因为短事务不断提交,有概率被饿死 | ||
|
|
||
| ## 参考文献 | ||
|
|
||
| - [CMU 15-445 Fall 2019 18 Timestamp Ordering Concurrency Control](https://www.youtube.com/watch?v=cPxJEt2to2A&list=PLSE8ODhjZXjbohkNBWQs_otTrBTrjyohi&index=18) | ||
| - [Timestamp based Concurrency Control](https://www.geeksforgeeks.org/timestamp-based-concurrency-control/) | ||
| - [Types of Schedules based Recoverability in DBMS](https://www.geeksforgeeks.org/types-of-schedules-based-recoverability-in-dbms/) | ||
| - [Types of Schedules in DBMS](https://www.geeksforgeeks.org/types-of-schedules-in-dbms/) |