

![]()

Built on top of SpatialData, Sopa enables processing and analyses of spatial omics data with single-cell resolution (spatial transcriptomics or multiplex imaging data) using a standard data structure and output. We currently support the following technologies: Xenium, Visium HD, MERSCOPE, CosMX, PhenoCycler, MACSima, Hyperion. Sopa was designed for generability and low memory consumption on large images (scales to 1TB+ images).
🎉 sopa==2.0.0 is out! It introduces many new API features; check our migration guide to smoothly update your code base.
Check Sopa's documentation to get started. It contains installation explanations, CLI/API details, and tutorials.
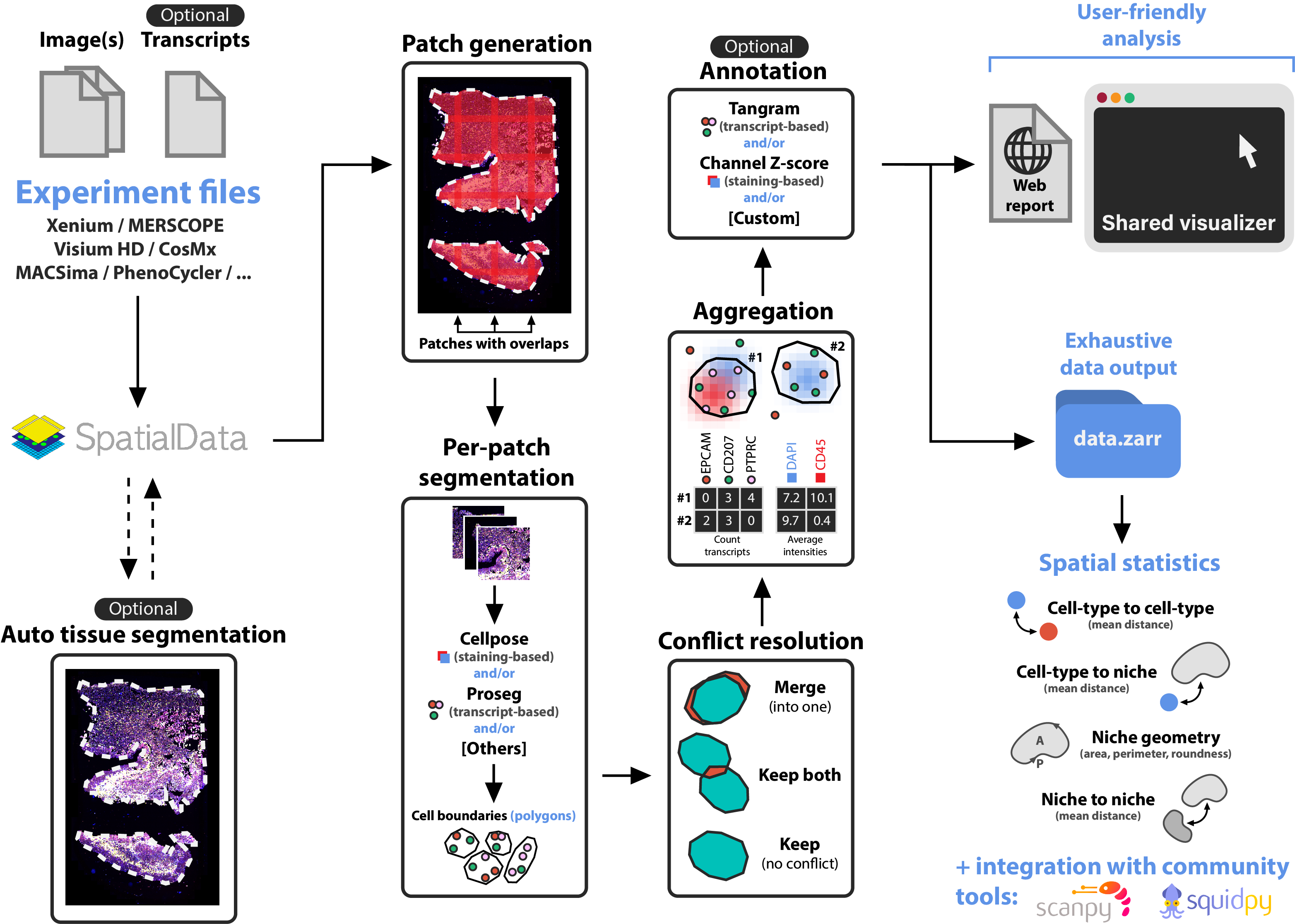
The following illustration describes the main steps of sopa:
Xenium Explorer is a registered trademark of 10x Genomics. The Xenium Explorer is licensed for usage on Xenium data (more details here).
Sopa can be installed via PyPI on all operating systems, with the only requirement being Python (>=3.10 and <=3.12). On a new environment, run the following command:
pip install sopaTo install extras (for example, if you want to use cellpose/baysor), please run:
# choose any valid extra among cellpose/baysor/tangram/wsi
pip install 'sopa[cellpose,baysor]'Important: even though pip install 'sopa[baysor]' will install some dependencies related to baysor, you still have to install the baysor command line (see the official repository) if you want to use it.
You can clone the repository and run one of these command lines at the root of sopa:
pip install -e . # dev mode installation
poetry install # poetry installationSopa comes in three different flavours, each corresponding to a different use case:
API: use directlysopaas a Python package for complete flexibility and customizationSnakemake pipeline: choose a config, and run our pipeline on your spatial data in a couple of minutesCLI: use our command-line-interface for prototyping quickly your own pipeline
Below is an example of a minimal API usage. For a complete API description, please refer to the documentation.
import sopa
sdata = sopa.io.xenium("path/to/data") # reading Xenium data
sopa.make_image_patches(sdata) # creating overlapping patches
sopa.segmentation.cellpose(sdata, "DAPI", diameter=30) # running cellpose segmentation
sopa.aggregate(sdata) # counting the transcripts inside the cellsClone our repository, choose a config here (or create your own), and execute our pipeline locally or on a high-performance cluster:
git clone https://github.com/gustaveroussy/sopa.git
cd sopa/workflow
snakemake --configfile=/path/to/yaml_config --config data_path=/path/to/data_directory --cores 1 --use-condaFor more details on snakemake configuration and how to properly setup your environments, please refer to the documentation.
Below are examples of commands that can be run with the sopa CLI. For a complete description of the CLI, please refer to the documentation.
> sopa --help # show command names and arguments
> sopa convert merscope_directory --technology merscope # read some data
> sopa patchify image merscope_directory.zarr # make patches for low-memory segmentation
> sopa segmentation cellpose merscope_directory.zarr --diameter 60 --channels DAPI # segmentation
> sopa resolve cellpose merscope_directory.zarr # resolve segmentation conflicts at boundaries
> sopa aggregate merscope_directory.zarr --average-intensities # transcripts/channels aggregation
> sopa explorer write merscope_directory.zarr # convert for interactive vizualisationOur article is published in Nature Communications. You can cite our paper as below:
@article{blampey_sopa_2024,
title = {Sopa: a technology-invariant pipeline for analyses of image-based spatial omics},
volume = {15},
url = {https://www.nature.com/articles/s41467-024-48981-z},
doi = {10.1038/s41467-024-48981-z},
journal = {Nature Communications},
author = {Blampey, Quentin and Mulder, Kevin and Gardet, Margaux and Christodoulidis, Stergios and Dutertre, Charles-Antoine and André, Fabrice and Ginhoux, Florent and Cournède, Paul-Henry},
year = {2024},
note = {Publisher: Nature Publishing Group},
pages = {4981},
}