

Low code data preparation
Currently, you can use DataPrep to:
- Collect data from common data sources (through
dataprep.connector) - Do your exploratory data analysis (through
dataprep.eda) - Clean and standardize data (through
dataprep.clean) - ...more modules are coming
| Repo | Version | Downloads |
|---|---|---|
| PyPI |  |
|
| conda-forge |  |
 |
pip install -U dataprepDataPrep.EDA is the fastest and the easiest EDA (Exploratory Data Analysis) tool in Python. It allows you to understand a Pandas/Dask DataFrame with a few lines of code in seconds.
You can create a beautiful profile report from a Pandas/Dask DataFrame with the create_report function. DataPrep.EDA has the following advantages compared to other tools:
- 10X Faster: DataPrep.EDA can be 10X faster than Pandas-based profiling tools due to its highly optimized Dask-based computing module.
- Interactive Visualization: DataPrep.EDA generates interactive visualizations in a report, which makes the report look more appealing to end users.
- Big Data Support: DataPrep.EDA naturally supports big data stored in a Dask cluster by accepting a Dask dataframe as input.
The following code demonstrates how to use DataPrep.EDA to create a profile report for the titanic dataset.
from dataprep.datasets import load_dataset
from dataprep.eda import create_report
df = load_dataset("titanic")
create_report(df).show_browser()Click here to see the generated report of the above code.
Click here to see the benchmark result.
Try DataPrep.EDA Online: DataPrep.EDA Demo in Colab
DataPrep.EDA is the only task-centric EDA system in Python. It is carefully designed to improve usability.
- Task-Centric API Design: You can declaratively specify a wide range of EDA tasks in different granularity with a single function call. All needed visualizations will be automatically and intelligently generated for you.
- Auto-Insights: DataPrep.EDA automatically detects and highlights the insights (e.g., a column has many outliers) to facilitate pattern discovery about the data.
- How-to Guide: A how-to guide is provided to show the configuration of each plot function. With this feature, you can easily customize the generated visualizations.

Click here to check all the supported tasks.
Check plot, plot_correlation, plot_missing and create_report to see how each function works.
DataPrep.Clean contains about 140+ functions designed for cleaning and validating data in a DataFrame. It provides
- A Convenient GUI: incorporated into Jupyter Notebook, users can clean their own DataFrame without any coding (see the video below).
- A Unified API: each function follows the syntax
clean_{type}(df, 'column name')(see an example below). - Speed: the computations are parallelized using Dask. It can clean 50K rows per second on a dual-core laptop (that means cleaning 1 million rows in only 20 seconds).
- Transparency: a report is generated that summarizes the alterations to the data that occured during cleaning.
The following video shows how to use GUI of Dataprep.Clean

The following example shows how to clean and standardize a column of country names.
from dataprep.clean import clean_country
import pandas as pd
df = pd.DataFrame({'country': ['USA', 'country: Canada', '233', ' tr ', 'NA']})
df2 = clean_country(df, 'country')
df2
country country_clean
0 USA United States
1 country: Canada Canada
2 233 Estonia
3 tr Turkey
4 NA NaNType validation is also supported:
from dataprep.clean import validate_country
series = validate_country(df['country'])
series
0 True
1 False
2 True
3 True
4 False
Name: country, dtype: boolCheck Documentation of Dataprep.Clean to see how each function works.
Connector now supports loading data from both web API and databases.
Connector is an intuitive, open-source API wrapper that speeds up development by standardizing calls to multiple APIs as a simple workflow.
Connector provides a simple wrapper to collect structured data from different Web APIs (e.g., Twitter, Spotify), making web data collection easy and efficient, without requiring advanced programming skills.
Do you want to leverage the growing number of websites that are opening their data through public APIs? Connector is for you!
Let's check out the several benefits that Connector offers:
- A unified API: You can fetch data using one or two lines of code to get data from tens of popular websites.
- Auto Pagination: Do you want to invoke a Web API that could return a large result set and need to handle it through pagination? Connector automatically does the pagination for you! Just specify the desired number of returned results (argument
_count) without getting into unnecessary detail about a specific pagination scheme. - Speed: Do you want to fetch results more quickly by making concurrent requests to Web APIs? Through the
_concurrencyargument, Connector simplifies concurrency, issuing API requests in parallel while respecting the API's rate limit policy.
from dataprep.connector import connect
conn_dblp = connect("dblp", _concurrency = 5)
df = await conn_dblp.query("publication", author = "Andrew Y. Ng", _count = 2000)Here, you can find detailed Examples.
Connector is designed to be easy to extend. If you want to connect with your own web API, you just have to write a simple configuration file to support it. This configuration file describes the API's main attributes like the URL, query parameters, authorization method, pagination properties, etc.
Connector now has adopted connectorx in order to enable loading data from databases (Postgres, Mysql, SQLServer, etc.) into Python dataframes (pandas, dask, modin, arrow, polars) in the fastest and most memory efficient way. [Benchmark]
What you need to do is just install connectorx (pip install -U connectorx) and run one line of code:
from dataprep.connector import read_sql
read_sql("postgresql://username:password@server:port/database", "SELECT * FROM lineitem")Check out here for supported databases and dataframes and more examples usages.
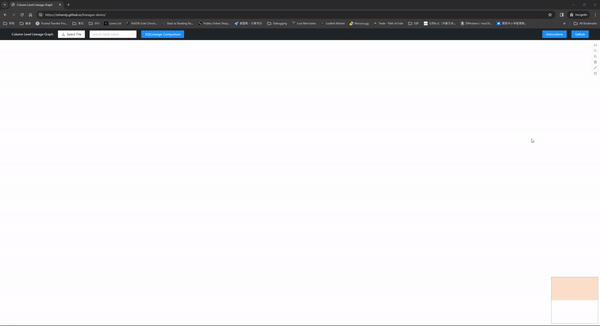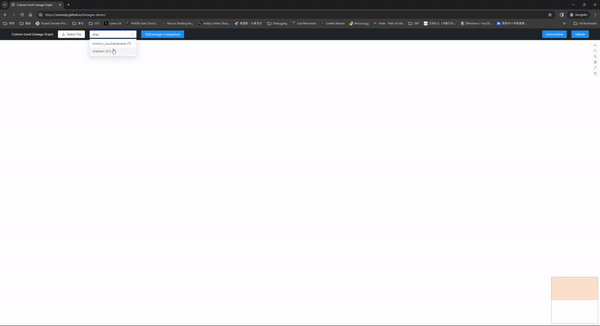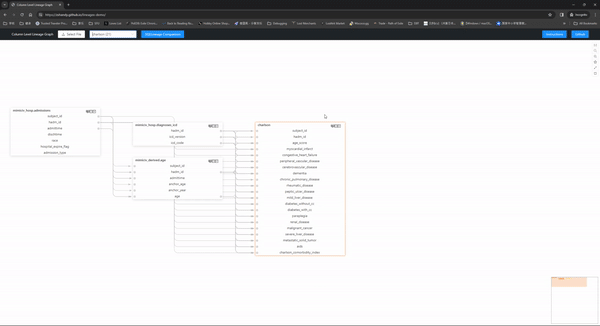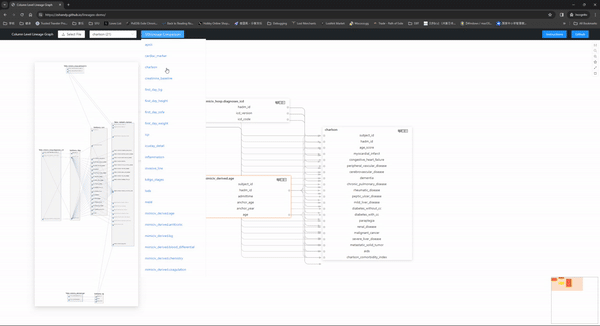
A Column Level Lineage Graph for SQL. This tool is intended to help you by creating an interactive graph on a webpage to explore the column level lineage among them.
A general introduction of the project can be found in this blog post.
- Automatic dependency creation: When there are dependency among the SQL files, and those tables are not yet in the database, the lineage module will automatically tries to find the dependency table and creates it.
- Clean and simple but very interactive user interface: The user interface is very simple to use with minimal clutters on the page while showing all of the necessary information.
- Variety of SQL statements: The lineage module supports a variety of SQL statements, aside from the typical
SELECTstatement, it also supportsCREATE TABLE/VIEW [IF NOT EXISTS]statement as well as theINSERTandDELETEstatement. - dbt support: The lineage module is also implemented in the dbt-LineageX, it is added into a dbt project and by using the dbt library fal, it is able to reuse the Python core and create the similar output from the dbt project.
The interactive graph looks like this:
 Here is a live demo with the mimic-iv concepts_postgres files(navigation instructions) and that is created with one line of code:
Here is a live demo with the mimic-iv concepts_postgres files(navigation instructions) and that is created with one line of code:
from dataprep.lineage import lineagex
lineagex(sql=path/to/sql, target_schema="schema1", conn_string="postgresql://username:password@server:port/database", search_path_schema="schema1, public")Check out more detailed usage and examples here.
The following documentation can give you an impression of what DataPrep can do:
There are many ways to contribute to DataPrep.
- Submit bugs and help us verify fixes as they are checked in.
- Review the source code changes.
- Engage with other DataPrep users and developers on StackOverflow.
- Ask questions & propose new ideas in our Forum.
- Contribute bug fixes.
- Providing use cases and writing down your user experience.

Please take a look at our wiki for development documentations!
Some functionalities of DataPrep are inspired by the following packages.
-
Inspired the report functionality and insights provided in
dataprep.eda. -
Inspired the missing value analysis in
dataprep.eda.
If you use DataPrep, please consider citing the following paper:
Jinglin Peng, Weiyuan Wu, Brandon Lockhart, Song Bian, Jing Nathan Yan, Linghao Xu, Zhixuan Chi, Jeffrey M. Rzeszotarski, and Jiannan Wang. DataPrep.EDA: Task-Centric Exploratory Data Analysis for Statistical Modeling in Python. SIGMOD 2021.
BibTeX entry:
@inproceedings{dataprepeda2021,
author = {Jinglin Peng and Weiyuan Wu and Brandon Lockhart and Song Bian and Jing Nathan Yan and Linghao Xu and Zhixuan Chi and Jeffrey M. Rzeszotarski and Jiannan Wang},
title = {DataPrep.EDA: Task-Centric Exploratory Data Analysis for Statistical Modeling in Python},
booktitle = {Proceedings of the 2021 International Conference on Management of Data (SIGMOD '21), June 20--25, 2021, Virtual Event, China},
year = {2021}
}