





The Framework for AI-driven Data Pipelines
Report bug
·
Request feature
Overview • Status • Getting Started • Examples • Collaboration
Graphbook is a framework for building efficient, interactive DAG-structured AI data pipelines or workflows composed of nodes written in Python. Graphbook provides common ML processing features such as multiprocessing IO and automatic batching for PyTorch tensors, and it features a web-based UI to assemble, monitor, and execute data processing workflows. It can be used to prepare training data for custom ML models, experiment with custom trained or off-the-shelf models, and to build ML-based ETL applications. Custom nodes can be built in Python, and Graphbook will behave like a framework and call lifecycle methods on those nodes.
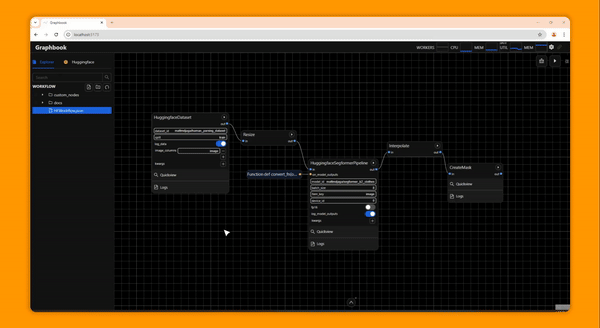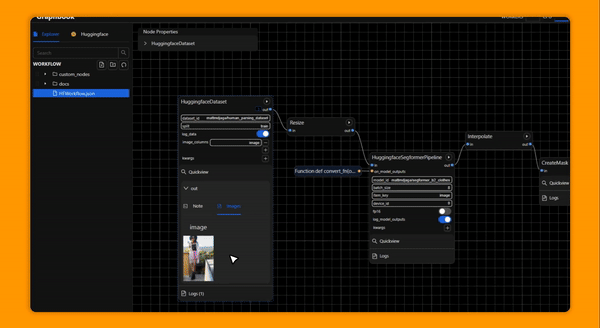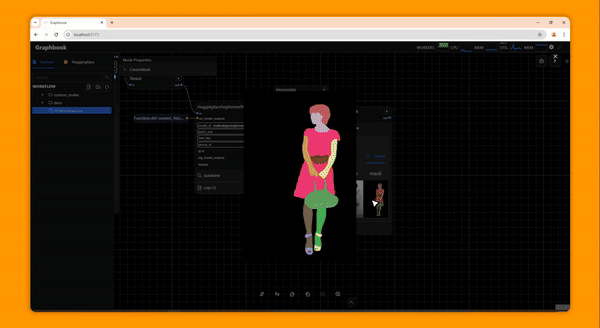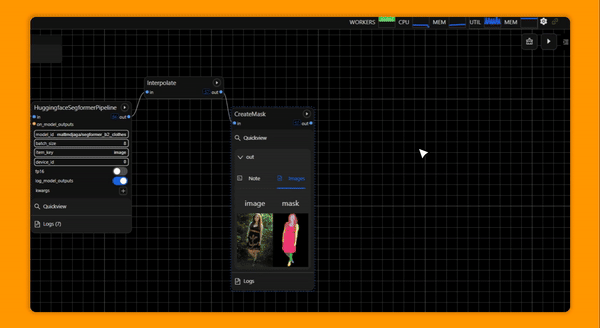
Graphbook is in a very early stage of development, so expect minor bugs and rapid design changes through the coming releases. If you would like to report a bug or request a feature, please feel free to do so. We aim to make Graphbook serve our users in the best way possible.
- Graph-based visual editor to experiment and create complex ML workflows
- Caches outputs and only re-executes parts of the workflow that changes between executions
- UI monitoring components for logs and outputs per node
- Custom buildable nodes with Python via OOP and functional patterns
- Automatic batching for Pytorch tensors
- Multiprocessing I/O to and from disk and network
- Customizable multiprocessing functions
- Ability to execute entire graphs, or individual subgraphs/nodes
- Ability to execute singular batches of data
- Ability to pause graph execution
- Basic nodes for filtering, loading, and saving outputs
- Node grouping and subflows
- Autosaving and shareable serialized workflow files
- Registers node code changes without needing a restart
- Monitorable CPU and GPU resource usage
- Human-in-the-loop prompting for interactivity and manual control during DAG execution
- (BETA) Third Party Plugins *
* We plan on adding documentation for the community to build plugins, but for now, an example can be seen at example_plugin and graphbook-huggingface
- A
graphbook runcommand to execute workflows in a CLI - All-code workflows, so users never have to leave their IDE
- Remote subgraphs for scaling workflows on other Graphbook services
- And many optimizations for large data processing workloads
The following operating systems are supported in order of most to least recommended:
- Linux
- Mac
- Windows (not recommended) *
* There may be issues with running Graphbook on Windows. With limited resources, we can only focus testing and development on Linux.
pip install graphbookgraphbook- Visit http://localhost:8005
- Pull and run the downloaded image
docker run --rm -p 8005:8005 -v $PWD/workflows:/app/workflows rsamf/graphbook:latest - Visit http://localhost:8005
Visit the docs to learn more on how to create custom nodes and workflows with Graphbook.
We continually post examples of workflows and custom nodes in our examples repo.
Graphbook is in active development and very much welcomes contributors. This is a guide on how to run Graphbook in development mode. If you are simply using Graphbook, view the Getting Started section.
You can use any other virtual environment solution, but it is highly adviced to use poetry since our dependencies are specified in poetry's format.
- Clone the repo and
cd graphbook poetry install --with devpoetry shellpython -m graphbook.maincd webdeno installdeno run dev