Repo for RIIID Kaggle competition
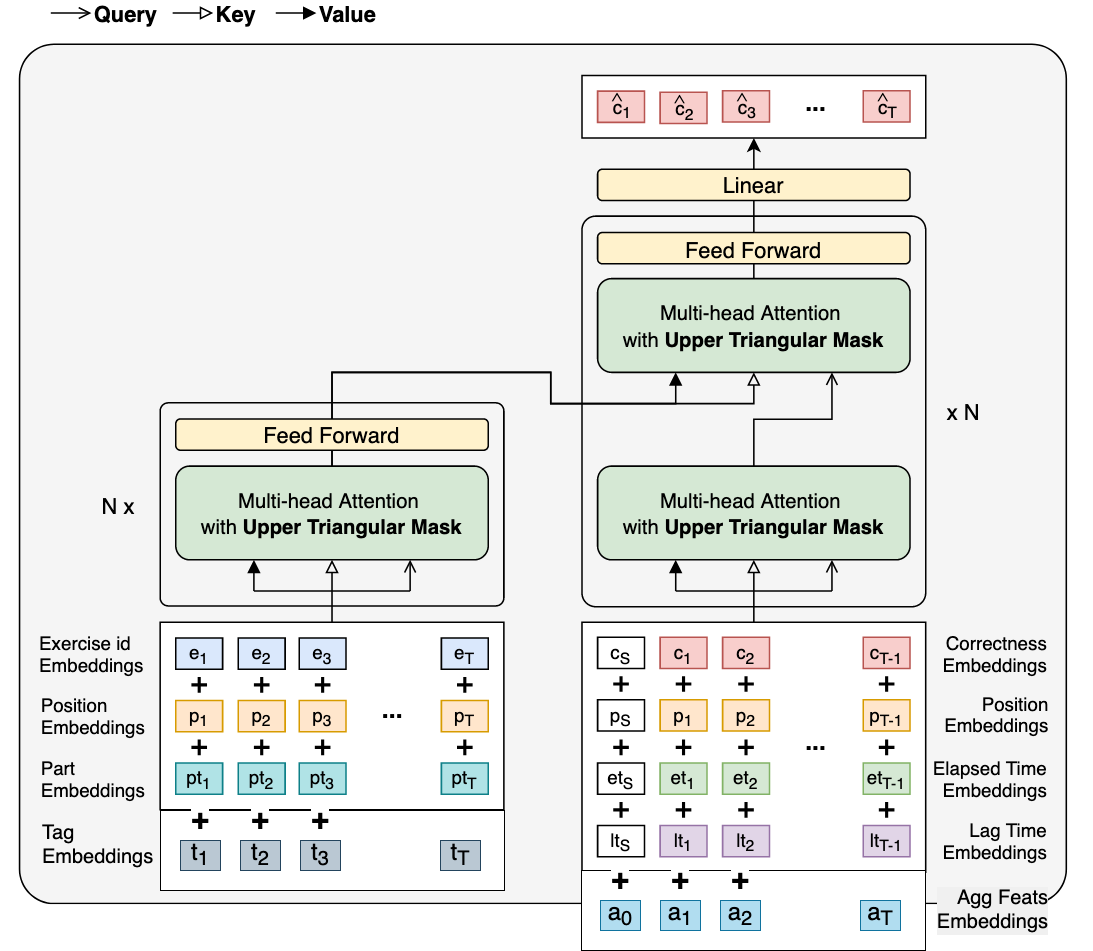
We ran a modified SAINT+ that included lectures, tags and a couple of aggregate features.
All our code is available on github ( https://github.com/gautierdag/riiid ). We used Pytorch/Pytorch Lightning and Hydra.
Our single model public LB was 0.808, and we were able to push that to LB 0.810 (Final LB 0.813) through ensembling.
-
Lectures: lectures were included and had a special trainable embedding vector instead of the answer embedding. The loss was not masked for lecture steps. We tested both with and without, and the difference wasn't crazy. The big benefit they offered was that they made everything much simpler to handle since we did not need to filter anything.
-
Tags: Since questions had a maximum of six tags, we passed sequences of length 6 to a tag embedding layer and summed the output. Therefore our tag embeddings were learned for each tag but then sum across to obtain an embedding for all the tags in a question/lecture. The padding simply returned a 0 vector.
-
Agg Feats: This is what gave us a healthy boost of 0.002 on public LB. By including 12 aggregate features in the decoder we were able to use some of our learnings in previous LGBM implementations.
We used the following aggregate features:
- attempts: number of previous attempts on current question (clamped to 5 and normalized to 1)
- mean_content_mean: average of all the average question accuracy (population wise) seen until this step by the user
- mean_user_mean: average of user's accuracy until this step
- parts_mean: seven dimensional (the average of the user's accuracy on each part)
- m_user_session_mean: the average accuracy in the current user's session
- session_number: the current session number (how many sessions up till now)
Note: session is just a way of dividing up the questions if a difference in time between questions is greater than two hours.
We switched to use a float representation of answers in the last few days. This seemed to have little effect on our LB auc unfortunately, but had an effect locally. The idea was that since we auto-regress on answers we would propagate the uncertainty that the model displayed into future predictions.
All aggs and time features are floats that are ran through a linear layer (without bias). They were all normalized to either [-1,1] or [0, 1].
All other embeddings are categorical.
What made a big difference early on was our sampling methodology. Unlike most approaches in public kernels, we did not take a user-centric approach to sample our training examples. Instead, we simply sampled based on row_id and would load in the previous window_size history for every row.
So for instance if we sampled row 55. Then we would find the user id that row 55 corresponds to, and load in their history up until that row. The size of the window would then be the min(window_size, len(history_until_row_55)).
We used Adam with 0.001 learning rate, early stopping and lr decay based on val_auc during training.
For validation, we kept a holdout set of 2.5mil (like the test set) and generated randomly with a certain proportion guaranteed of new users. We used only 250,000 rows to actually validate on during training.
For every row in validation, we would pick a random number of inference steps between 1 and 10. We would then infer over these steps, not allowing the model to see the true answers and having to use its own.
During inference, when predicting multiple questions for a single user, we fed back the previous prediction of our model as answers in the model. This auto-regression was helpful in propagating uncertainty and helped the auc.
I saw a writeup that said that this was not possible to do because it constrains you to batch size = 1. That is wrong, you can actually do this for a whole batch in parallel and it's a little tricky with indexes but it is doable. You simply have to keep track of each sequence lengths and how many steps you are predicting for each.
Unfortunately since some of our aggs are also based on user answers, these do not get updated until the next batch because they are calculated on CPU and not updated in that inference loop.
We ensemble three models.
First model:
- 64 emb_dim
- 4/6 encoder/decoder layers
- 256 feed foward in Transformer
- 4 Heads
- 100 window size
Second model:
- 64 emb_dim
- 4/6 encoder/decoder layers
- 256 feed foward in Transformer
- 4 Heads
- 200 window size (expanded by finetuning on 200)
Third model:
- 256 emb_dim
- 2/2 encoder/decoder layers
- 512 feed foward in Transformer
- 4 Heads
- 256 window size
We rented three machines but we could have probably gotten farther with using a larger single machine:
- 3 X 1 Tesla V100(16gb VRAM)
- Noam lr schedule (super slow to converge)
- Linear attention / Reformer / Linformer (spent way to much time on this)
- Local Attention
- Additional Aggs in output layer and a myriad of other aggs
- Concatenating Embeds instead of summing
- A lot of different configurations of num_layers / dims / .. etc
- Custom attention based on bundle
- Ensembling with LGBM
- Predicting time taken to answer question as well as answer in Loss
- K Beam decoding (predicting in parallel K possible paths of answers and taking the one that maximized joint probability of sequence)
- Running average of agg features (different windows or averaging over time)
- Causal 1D convolutions before the Transformer
- Increasing window size during training
- ...