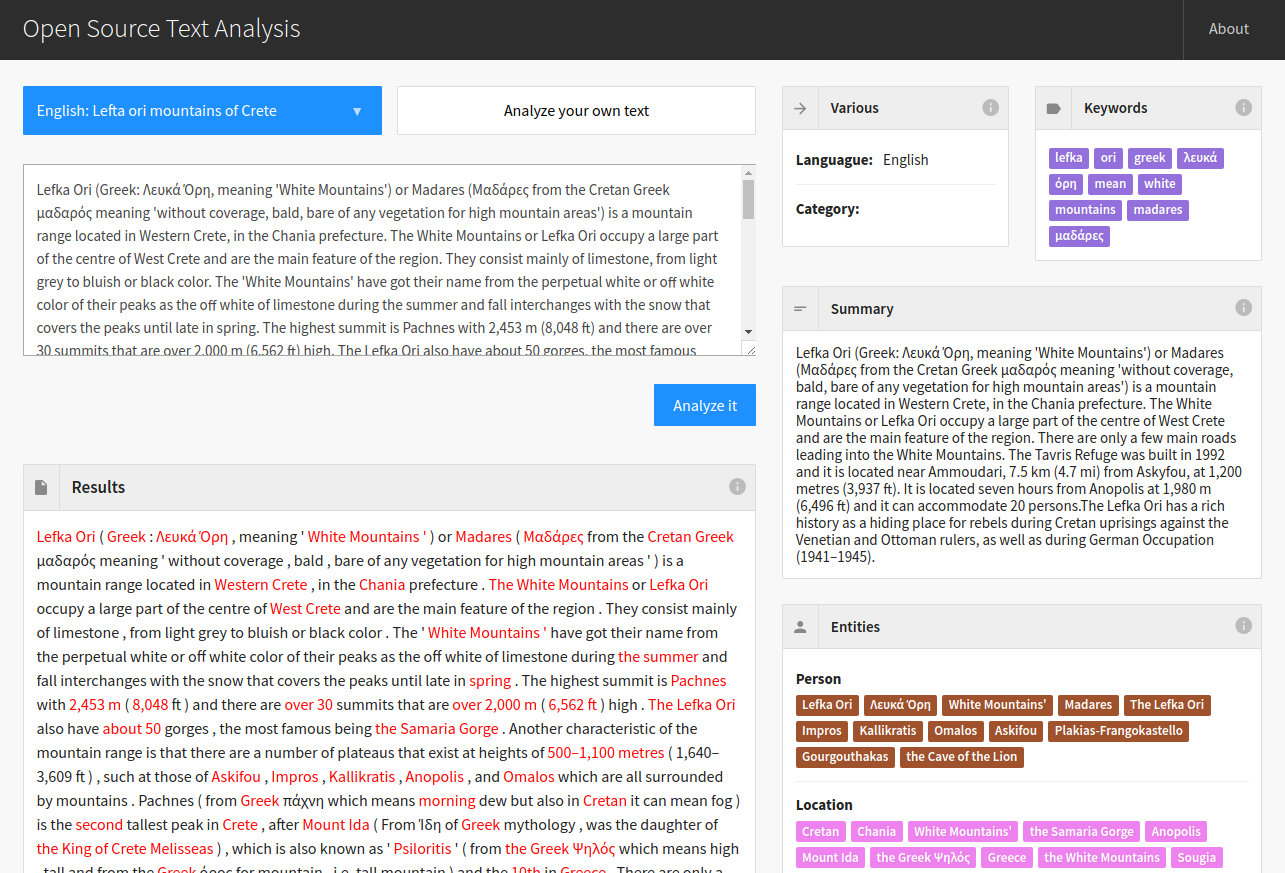
NLPBuddy is a text analysis application for performing common NLP tasks through a web dashboard interface and an API.
It leverages Spacy for the NLP tasks plus Gensim's implementation of the TextRank algorithm for text summarization.
It supports texts in the following languages: Greek, English, German, Spanish, Portoguese, French, Italian and Dutch. Language identification is performed automatically through langid
Tasks include:
- Text tokenization
- Sentence splitting (lemmatized sentences too)
- Part of Speech tags identification (verbs, nouns etc)
- Named Entity Recognition (Location, Person, Organisation etc)
- Text summarization (using TextRank algorithm, implemented by Gensim)
- Keywords extraction
- Language identification
- For the Greek language, Categorization of text
Text can either be provided or imported after specifying a url - we use library python readability for this plus BeautifulSoup4
The Greek classifier is built with FastText and is trained in 20.000 articles labeled in these categories.
A working demo can be found on http://www.nlpbuddy.io/
Enter text and hit 'Analyze it',
https://github.com/eellak/text-analysis/wiki/API-usage
Find development and deployment instructions here: https://github.com/eellak/text-analysis/wiki/Install
The code is provided under the GNU AGPL v3.0 License.