-
Notifications
You must be signed in to change notification settings - Fork 195
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Adrian
authored and
Adrian
committed
Mar 6, 2024
1 parent
1957384
commit cc870a2
Showing
1 changed file
with
144 additions
and
0 deletions.
There are no files selected for viewing
144 changes: 144 additions & 0 deletions
144
docs/website/blog/2024-03-07-openapi-generation-chargebee.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,144 @@ | ||
| --- | ||
| slug: openapi-generation-chargebee | ||
| title: "Saving 75% of work for a Chargebee Custom Source via pipeline code generation with dlt" | ||
| image: https://storage.googleapis.com/dlt-blog-images/openapi-generation.png | ||
| authors: | ||
| name: Adrian Brudaru & Violetta Mishechkina | ||
| title: Data Engineer & ML Engineer | ||
| url: https://github.com/dlt-hub/dlt | ||
| image_url: https://avatars.githubusercontent.com/u/89419010?s=48&v=4 | ||
| tags: [data observability, data pipeline observability] | ||
| --- | ||
| At dltHub, we're pioneering the future of data pipeline generation, making complex processes simple and scalable. | ||
|
|
||
| Pipeline generation on a simple level is already possible directly in gpt chats - just ask for it. But doing it at scale, correctly, and producing comprehensive, good quality pipelines is a much more complex endeavour. | ||
|
|
||
| # The automated work by our existing PoC | ||
|
|
||
| 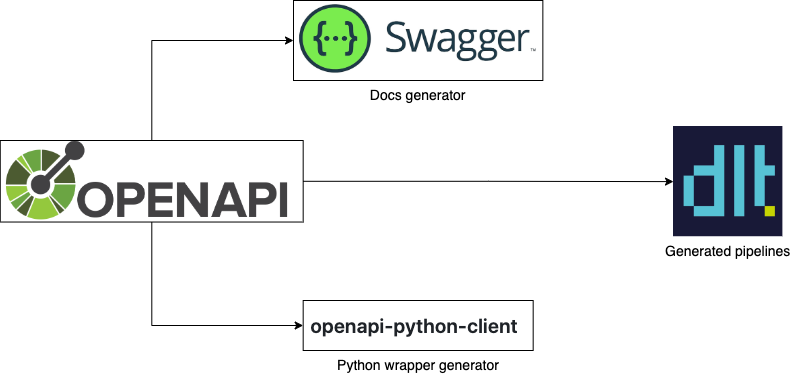 | ||
| *This diagram illustrates how OpenAPI spec is used for software generation.* | ||
|
|
||
| To generate pipelines, what we need is the right knowledge of what should happen. One such source is the OpenApi spec, but it does not contain complete information for generating everything. | ||
|
|
||
| Last year we experimented with extracting this information and generating pipelines, and you can read about it here: https://dlthub.com/docs/blog/open-api-spec-for-dlt-init | ||
|
|
||
| Our PoC leveraged the OpenAPI spec to automate pipeline creation, achieving significant strides in efficiency and accuracy. | ||
|
|
||
|
|
||
| # The manual last mile | ||
|
|
||
| Ideally, we would love to point a tool at an api or doc of the api, and just have the pipeline generated. We can already do that to some extent, and fill in any gaps manually. | ||
|
|
||
| While automation handles the bulk, some customisation remains manual, generating requirements towards our ongoing efforts of full automation. | ||
|
|
||
| # Why now? Community growth requires faster onboarding with code generation | ||
|
|
||
| dlt community has been growing steadily in recent months. In February, we had a 25% growth on slack and even more in usage. | ||
|
|
||
| The new users generated a lot of questions and some of them used our onboarding program, where we speed-run you through any obstacles, learning how to make things smoother along the way. | ||
|
|
||
| Usually users want to create a POC first, so we do our best to help. In this case, one of our users wanted to try dlt with a source we did not list in our public sources - chargebee. | ||
|
|
||
| Since the Chargebee API uses the OpenAPI standard, we used the OpenAPI Proof of Concept pipeline generator that we built last year. | ||
|
|
||
| # Generating a pipeline with dlt - real fast like. | ||
|
|
||
| ### Starting resources | ||
|
|
||
| POC for getting started, human for the last mile. | ||
|
|
||
| - Blog post with a video guide https://dlthub.com/docs/blog/open-api-spec-for-dlt-init | ||
| - OpenAPI Proof of Concept pipeline generator: https://github.com/dlt-hub/dlt-init-openapi | ||
| - Chargebee openapi spec https://github.com/chargebee/openapi | ||
| - Understanding of how to make web requests | ||
| - And 4 hours of time - this was part of our new hire Violetta’s onboarding tasks at dltHub so it was her first time using dlt and the code generator. | ||
|
|
||
| Onward, let’s look at how our new colleague Violetta, ML Engineer, used this PoC to generate PoCs for our users. | ||
|
|
||
| ### Violetta shares her experience: | ||
|
|
||
| So the first thing I found extremely attractive — the code generator actually created a very simple and clean structure to begin with. | ||
|
|
||
| I was able to understand what was happening in each part of the code. What unfortunately differs from one API to another — is the authentication method and pagination. This needed some tuning. Also, there were other minor inconveniences which I needed to handle. | ||
|
|
||
| There was no great challenges. The most ~~difficult~~ tedious probably was to manually change pagination in different sources and rename each table. | ||
|
|
||
| 1) Authentication | ||
| The provided Authentication was a bit off. The generated code assumed the using of a username and password but what was actually required was — an empty username + api_key as a password. So super easy fix was changing | ||
|
|
||
| ```python | ||
| def to_http_params(self) -> CredentialsHttpParams: | ||
| cred = f"{self.api_key}:{self.password}" if self.password else f"{self.username}" | ||
| encoded = b64encode(f"{cred}".encode()).decode() | ||
| return dict(cookies={}, headers={"Authorization": "Basic " + encoded}, params={}) | ||
| ``` | ||
|
|
||
| to | ||
|
|
||
| ```python | ||
| def to_http_params(self) -> CredentialsHttpParams: | ||
| encoded = b64encode(f"{self.api_key}".encode()).decode() | ||
| return dict(cookies={}, headers={"Authorization": "Basic " + encoded}, params={}) | ||
| ``` | ||
|
|
||
| Also I was pleasantly surprised that generator had several different authentication methods built in and I could easily replace `BasicAuth` with `BearerAuth` of `OAuth2` for example. | ||
|
|
||
| 2) Pagination | ||
|
|
||
| For the code generator it’s hard to guess a pagination method by OpenAPI specification, so the generated code has no pagination 😞. So I had to replace a line | ||
|
|
||
| ```python | ||
| yield _build_response(requests.request(**kwargs)) | ||
| ``` | ||
|
|
||
| with yielding form a 6-lines `get_page` function | ||
|
|
||
| ```python | ||
| def get_pages(kwargs: Dict[str, Any], data_json_path): | ||
| has_more = True | ||
| while has_more: | ||
| response = _build_response(requests.request(**kwargs)) | ||
| yield extract_nested_data(response.parsed, data_json_path) | ||
| kwargs["params"]["offset"] = response.parsed.get("next_offset", None) | ||
| has_more = kwargs["params"]["offset"] is not None | ||
| ``` | ||
|
|
||
| The downside — I had to do it for each resource. | ||
|
|
||
| 3) Too many files | ||
|
|
||
| The code wouldn’t run because it wasn’t able to find some models. I found a commented line in generator script | ||
|
|
||
| ```python | ||
| # self._build_models() | ||
| ``` | ||
|
|
||
| I regenerated code with uncommented line and understood why it was commented. Code created 224 `.py` files under the `models` directory. Turned out I needed only two of them. Those were models used in api code. So I just removed other 222 garbage files and forgot about them. | ||
|
|
||
| 4) Namings | ||
|
|
||
| The only problem I was left with — namings. The generated table names were like | ||
| `ListEventsResponse200ListItem` or `ListInvoicesForACustomerResponse200ListItem` . I had to go and change them to something more appropriate like `events` and `invoices` . | ||
|
|
||
| ### The result | ||
|
|
||
| Result: https://github.com/dlt-hub/chargebee-source | ||
|
|
||
| I showed this source to our user, and did a walk-through with him. Some additional context started to appear. Like which endpoints needed to be used with `replace` write disposition, which would require specifying the `merge` keys. So at the end this source would still require some testing to be performed and some fine tuning from the user. | ||
|
|
||
| I think silver lining is here — how to start. I don’t know how much time I would’ve spend on this source if I would start from scratch. Probably, for the first couple of hours I would be trying to decide where should the authentication code go, i’d be going through the docs searching for information on how can I obtain the api key from config. I would need to go through all API endpoints in documentation to be able to find the right one. There are a lot of different things which could be difficult especially if you’re doing it for the first time. | ||
|
|
||
| I think at the end, if I would have done it from scratch, I would’ve got cleaner code but would have spent 2-3 days. With the generator, even with finetuning, I spent about half day. And the structure was already there, so it was overall easier to work with and I didn’t have to consider everything upfront. | ||
|
|
||
| # In conclusion | ||
|
|
||
| Code generation is automation on steroids. | ||
|
|
||
| In this example, we used an algorithmic approach - the code was written by rule-based logic, not by LLMs. This means that the code is reliable in what it does, but it downright misses some pieces because we did not have information to generate them from. | ||
|
|
||
| The missing pieces such as pagination, incremental loading, are not captured in the OpenAPI spec and thus we cannot infer them automatically. However, it would be possible to design a process by which a LLM-assistant will ask or suggest ways to handle it. | ||
|
|
||
| ### We are currently working on making full generation a reality. | ||
|
|
||
| * Stay tuned for more, or | ||
| * [Join our slack community](https://dlthub.com/community) to take part in the conversation. |