-
Notifications
You must be signed in to change notification settings - Fork 193
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* blog post sources * spelling
- Loading branch information
Showing
1 changed file
with
57 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,57 @@ | ||
| --- | ||
| slug: code-vs-buy | ||
| title: Coding data pipelines is faster than renting connector catalogs | ||
| image: https://storage.googleapis.com/dlt-blog-images/source-lib-1.png | ||
| authors: | ||
| name: Matthaus Krzykowski | ||
| title: Co-Founder & CEO at dltHub | ||
| url: https://twitter.com/matthausk | ||
| image_url: https://pbs.twimg.com/profile_images/642282396751130624/9ixo0Opj_400x400.jpg | ||
| tags: [dlthub, source libraries, dlt] | ||
| --- | ||
|
|
||
| ## **Celebrating over 500 ad hoc custom sources written by the** `dlt` **community in February** | ||
|
|
||
| Today it is easier to pip install dlt and write a custom source than to setup and configure a traditional ETL platform. | ||
|
|
||
| The wider community is increasingly noticing these benefits. In February the community wrote over 500 `dlt` custom sources. Last week we crossed 2000 `dlt` total custom sources created since we launched dlt last summer. | ||
|
|
||
| 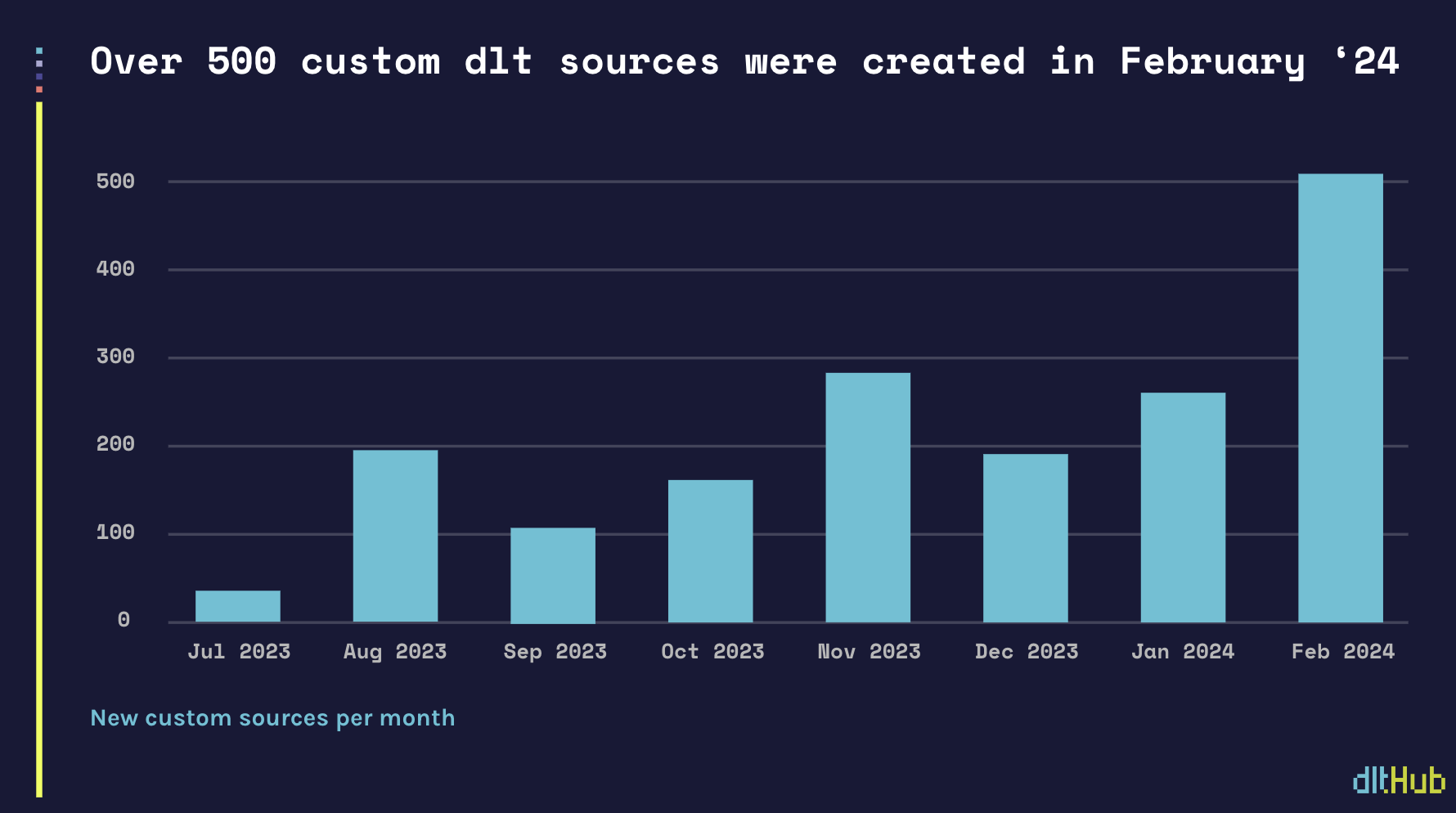 | ||
|
|
||
| A custom `dlt` source is something new for our industry. With `dlt` we automated the majority of the work data engineers tasks that are usually done in traditional ETL platforms. Hence, creating an ad hoc `[dlt` pipeline and source](https://dlthub.com/docs/walkthroughs/create-a-pipeline) is a [dramatically simpler.](https://dlthub.com/docs/build-a-pipeline-tutorial#the-simplest-pipeline-1-liner-to-load-data-with-schema-evolution) Maintaining a custom `dlt` source in production is relatively easy as most of the common [pipeline maintenance issues are handled.](https://dlthub.com/docs/build-a-pipeline-tutorial#governance-support-in-dlt-pipelines) | ||
|
|
||
| Today `[dlt` users](https://dlthub.com/docs/blog/dlthub-who-we-serve) pick dlt because it is the fastest way to create a dataset. As we frequently hear it from all of you “dlt is pip install and go”. This is in line with our [mission to make this next generation of Python users autonomous when they create and use data in their organizations](https://dlthub.com/docs/blog/dlthub-mission). | ||
|
|
||
| ## How to get to 50,000 sources: let’s remove the dependency on source catalogs and move forward to ad hoc code | ||
|
|
||
| We think that “Pip install ETLs” or “EL as code” tools such as dlt are ushering a new era of ad hoc code. ad hoc code allows for automation and customization of very specific tasks. | ||
|
|
||
| Most of the market today is educated by Saas ETLs on the value of “source”/”connector” catalogs. The core is a short-tail catalog market of +-20 sources (product database replication, some popular CRMs and ads APIs) with the highest profit margins and intense competition among vendors. The long-tail source catalog market, depending on the vendor, is usually up to 400 sources, with much smaller support. | ||
|
|
||
| We think that source catalogs will become more and more irrelevant in the era of LLMs and ad hoc code. “EL as code” allows users to work with source catalog. From the beginning the dlt community has been writing [wrappers for taps/connectors from other vendors](https://github.com/z3z1ma/alto/blob/main/example_proj/asana_pipeline.py), usually to migrate to a dlt pipeline at some point, as we documented in the [customer story how Harness adopted dlt](https://dlthub.com/success-stories/harness/). | ||
|
|
||
|  | ||
|
|
||
| Even for short-tail, high quality catalog sources “EL as code” allows for fixes of hidden gotchas and customisation that makes data pipelines production-ready. | ||
|
|
||
| We also believe that these are all early steps in “EL as code”. [Huggingface hosts over 116k datasets](https://huggingface.co/datasets) as of March ‘24. We at dltHub think that the ‘real’ Pythonic ETL market is a market of 100k of APIs and millions of datasets. | ||
|
|
||
| ## dlt has been built for humans and LLMs from the get go and this will make coding data pipelines even faster | ||
|
|
||
| Since the inception of dlt, we have believed that the adoption `dlt`among the next generation of Python users will depend on its compatibility with code generation tools, including Codex, ChatGPT, and any new tools that emerge on the market.. | ||
|
|
||
| We have not only been building `dlt` for humans, but also LLMs. | ||
|
|
||
| Back in March ‘23 we released [dlt init](https://dlthub.com/docs/getting-started) as the simplest way to add a pipeline/initialize a project in `dlt`. We rebuilt the `dlt` library in such a way that it performs well with LLMs. At the end of May ‘23 we opened up our `dltHub` Slack to the broader community. | ||
|
|
||
| [Back in June ‘23 we released a proof of concept](https://dlthub.com/docs/blog/open-api-spec-for-dlt-init) of the `[dlt init](https://dlthub.com/docs/walkthroughs/create-a-pipeline)` extension that can [generate `dlt` pipelines from an OpenAPI specification.](https://github.com/dlt-hub/dlt-init-openapi) As we said at that time, if you build APIs, for example with [FastAPI](https://fastapi.tiangolo.com/), you can, thanks to the [OpenAPI spec,](https://spec.openapis.org/oas/v3.1.0) automatically generate a [Python client](https://pypi.org/project/openapi-python-client/0.6.0a4/) and give it to your users. If you have 3min time watch how a demo Marcin generates such a pipeline from the OpenAPI spec using the [Pokemon API](https://pokeapi.co/) in [this Loom](https://www.loom.com/share/2806b873ba1c4e0ea382eb3b4fbaf808?sid=501add8b-90a0-4734-9620-c6184d840995). This demo took things a step further and enables users to generate advanced `dlt` pipelines that, in essence, convert your API into a live dataset. | ||
|
|
||
| However, it takes a long time to go from a LLM PoC to production-grade code. We know much of our user base is already using ChatPGT and comparable tools to generate sources. We hear our community's excitement about the promise of LLMs for this task. The automation promise is in both in building and configuring pipelines. Anything seems possible, but if any of you have played around this task with ChatPGT - usually the results are janky. Along these lines in the last couple of months we have been dog fooding the PoC that can generate `dlt` pipelines from an OpenAPI specification. | ||
|
|
||
|  | ||
|
|
||
| https://twitter.com/xatkit/status/1763973816798138370 | ||
|
|
||
| You can read a case study [on how our solution engineer Violetta used an iterated version of the PoC to generate a production-grade Chargebee `dlt` within hours instead of 2,3 days here](https://dlthub.com/docs/blog/openapi-generation-chargebee). | ||
|
|
||
| We think that at this stage we are a few weeks away from releasing our next product that makes coding data pipelines faster than renting connector catalog: a `dlt` code generation tool that allows `dlt` users create datasets from the REST API in the coming weeks. |