-
Notifications
You must be signed in to change notification settings - Fork 25
Supervise Mode
Another useful feature that FISS adds to FireCloud interaction is supervise mode, which provides a high level means of orchestrating the execution of interdependent FireCloud method configurations, checkpointing the state of their execution, and fostering error recovery. This feature is named to connote that FISS supervises FireCloud, by taking over the decision of when to launch a task. Here's an example of how supervise mode is used in the Broad GDAC to manage analysis runs:
fissfc supervise --workspace analyses__2018_07_13 Analyses.dot
The last argument here, Analyses.dot, specifies the relationships between the configured GDAC methods (which for convenience we'll refer to here as tasks), in the form of a directed acyclic graph (or DAG) in the DOT file language introduced in GraphViz. For example, consider the task Aggregate_Molecular_Subtype_Clusters, shown here in the legacy version of the GDAC DAG: notice that it has more than 10 inputs, specified as incoming arcs from other nodes in the DAG. Given that some of these inputs are required and some are optional, how can we decide the best moment to launch this task during an analysis run?
Should it be launched merely when all of its required inputs are available, which is the single criterion used by Cromwell (internally to FireCloud) when launching workflows? Or might it be beneficial to hold the task in pause until one or more optional inputs are also available? And if we wait until optional inputs are available, how many should we wait for? That is, how long should the task wait before being launched? Supervise mode was created to solve this problem! What it does is enlarge to 2 the set of constraints used to evaluate when a task should be launched, holding them in pause until two criteria are met:
- All of its required inputs are available
- No more of its optional inputs will ever become available
To satisfy constraint (2) the supervisor looks recursively backward on the DAG, and delays launching a downstream task until it determines that there are zero remaining optional upstream tasks that can possibly be launched or executed to successful completion. To understand why constraint (2) is valuable it’s helpful to examine (a) the structure of the data upon which the GDAC workflow operates, and (b) how that data is generally made available over time.
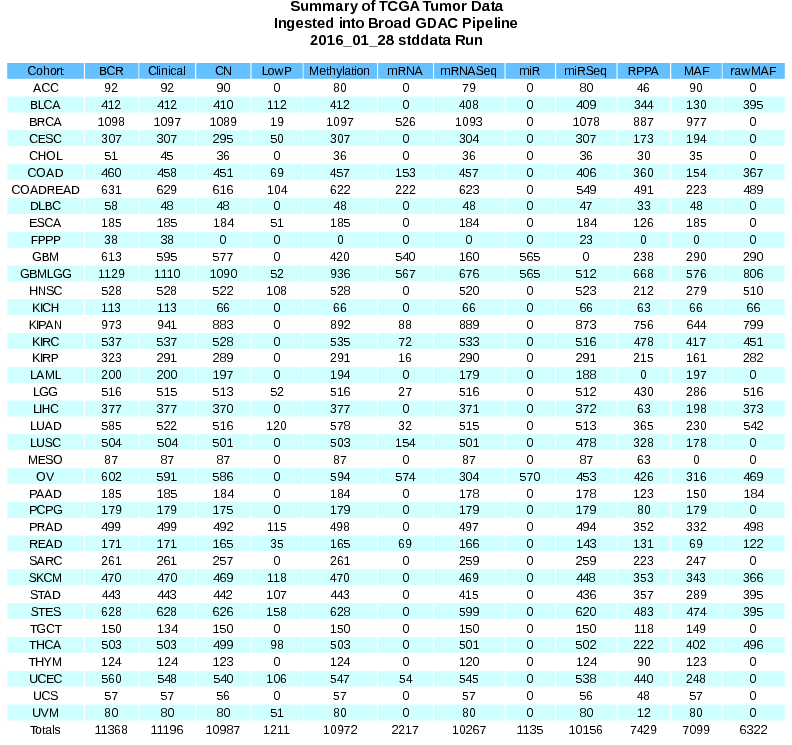
We use Legacy TCGA to make things concrete, but a similar pattern holds for the operational phase of many data-intensive scientific projects. First, the entire analysis DAG is executed for 38 independent disease cohorts (sets of patient samples); and each sample within a cohort may be characterized in as many as 10 different ways (yielding up to 10 distinct kinds of data, or data types, for each patient sample). This data table shows both the disease cohorts (rows) and data types (columns) in the corpus of TCGA data.
{kind=link}
Notice the heterogeneity in this data, in both the sizes of disease cohorts as well as the data types each of them offer. What the table doesn’t show, because the TCGA is done collecting data, is that at any given moment during the TCGA project many of the cells in this table were empty; so that, in general, when executing our analysis DAG on any given cohort some of the input arcs to the Aggregate task might execute (because data aliquots of that type are available for that cohort) and some wouldn’t; and that the size of the data grows incrementally but unpredictably over time; in January there might be 0 expression aliquots for breast cancer (BRCA), so none of the expression analysis tasks would execute (which is why they are optional to the Aggregate task).
Then in March 100 expression aliquots might appear in the BRCA cohort, so that upstream expression analysis tasks would now be runnable, and the supervisor would delay the Aggregate task until they either complete or fail; whereas before March we know those tasks could not be run for lack of data, and therefore we would not postpone launching of the Aggregate task for them. If no more expression aliquots are added to BRCA until August, then from April until August whenever we attempt to execute the Analyses DAG we would expect all upstream expression analyses tasks to not be executed upon BRCA, aka they are "job avoided," because their results were found in the call cache (as long as the software versions of those tasks also remained the same, in addition to the input data).
Note that job avoiding upstream tasks does not mandate that Aggregate would also avoid, because other arcs on the DAG might have become populated with data in the meantime (e.g. 231 copy number aliquots might have appeared, causing the copy number analysis tasks to be executed, et cetera). We hope it is now clear that the processes described here would be labor intensive and error prone to manage in a manual fashion, and thus why job avoidance and recursive lookback optionality have been valuable features for the automation of high-throughput GDAC analysis. In addition to enhancing our analyses and saving time, they also save money, since they result in less consumption of storage and compute on the cloud. We expect this to continue as new projects emerge in the Genome Data Analysis Network (GDAN, begun in the fall of 2016), which collectively will be significantly larger than TCGA, more diverse in their goals, and more heterogenous in their data types and availability.