Collaging through Space and Time: Computer Vision for Creative Explorations of the Library's Digital Collections
Collaging through Space and Time: Computer Vision for Creative Explorations of the Library's Digital Collections (Collaging through Space and Time) is an interactive collage tool that allows users to "cut" subjects and objects from images and "paste" them unto a series of pre-selected backgrounds. All images in the current iteration of Collaging through Space and Time are taken from the following collections:
- National Photo Company Collection
- Carol M. Highsmith Archive Collection
- Free to Use and Reuse Collection
For more information on our collection development policies and decisions, see Collection Development.
- Overview
- Background
- Collaging through Space and Time: Computer Vision for Creative Explorations of the Library's Digital Collections
Collaging through Space and Time: Computer Vision for Creative Explorations of the Library's Digital Collections (Collaging through Space and Time) is an interactive collage tool that encourages self-directed learning and educational play, allowing students to explore the Washington, D.C. area’s communal history through creative expression.
The target audience of Collaging through Space and Time consists of late-elementary to early middle school students and instructors of this age group.
Collaging through Space and Time is intended to be used primarily for self-directed learning in a controlled and moderated environment. Below are scenarios of this use case:
- A student has completed their class assignment before other students. They are directed by an instructor to create a collage using Collaging through Space and Time and perhaps write a short essay explaining the story behind their collage.
- A student has completed their class assignment before other students. As a reward, they are allowed by an instructor to use Collaging through Space and Time while other students finish up their assignment.
- In an after-school care or before-school care setting, an instructor allows students to create a collage using Collaging through Space and Time while students await their guardian.
Collaging through Space and Time can also be used for instructor-directed or non-instructor-directed group learning. Below are scenarios of this use case:
- After a history or civics lesson, an instructor works with students to create a group collage that reiterates what they have learned from the lesson.
- An instructor creates an assignment in which different groups of students create a collage based on something they have learned from a lesson.
These use cases are specific to Collaging through Space and Time as a final product. However, Collaging through Space and Time was also created as an example of how the Library's digital collections can be used to create community-centered projects. See Background for more information.
As part of the Computing Cultural Heritage in the Cloud (CCHC) project, LC Labs partnered with the Junior Fellows Program to hire three interns who would be responsible for creating a data visualization or otherwise interactive tool that:
- Highlights marginalized histories and/or communities
- Serves as an outreach tool
- Utilizes the Labs’ newly curated data packages
- Experiments with emerging technologies
The Junior Fellows, Ilayda Dogan, Shauna-Kay Harrison, and Aisaiah Pellecer, were strongly drawn to creating a tool for a younger demographic. This decision was made due to a combination of factors. Outside of the Fellows' mutual interest in working with younger demographics and educational tools, the Fellows also considered that the prior LC Labs’ Junior Fellow project was text-based (working primarily with text-mining), and geared towards a more academic audience. This led the Fellows to strongly consider creating a project that steered in a different direction.
A major goal of this project is outreach: making those otherwise isolated from the Library and its resources more connected. The Fellows thought of their own experiences as children in late elementary to early middle school, and realized that they were not aware of the Library and its many collections at that age. If the Library wanted civilians, particularly those of marginalized identities, to be aware of the resources it offers, the Fellows agreed that early exposure would be the best way to achieve this, and sought to create a tool that would aid in this process.
The project that the Fellows chose to pursue was heavily influenced by the Fellows’ own experiences with educational tools, such as Poptropica and the myriad of games that were on websites like Cool Math Games in the late 2000s and 2010s.
An earlier concept for this project involved creating an open-ended adventure and role-playing game that would allow players to go on semi-directed (having a clearly defined narrative and end goal) but open-ended (players can problem-solve and play at their own pace). In this concept, the player would go on a "scavenger hunt," looking for clues and solving puzzles in order to "find" or "unlock" items (which would be drawn from the Library's digital collections). The player would be able to collect aspects of these found items (for example, the hat from an image they found) and store them in some sort of "base" or "backpack" where they could customize their player character. To allow the player to collect aspects of items found in the "scavenger hunt," the Fellows planned to use machine learning to detect and segment objects from the items.
Due to the duration of this project (10 weeks), the Fellows realized they would not have enough time for scripting, design, and user testing. As such, they reconceptualized the project, expanding upon and focusing on the player character customization aspect of the initial idea.
Rather than using object detection and image segmentation for player character customizations, the Fellows opted to use this technology instead for a more casual, gamified experience. The technology that would be used for the early concept was well positioned to be used in the creation of a collage tool. This tool, like the previous idea, was equally open-ended and could be self- or instructor-directed. It also allowed for a contextualized, but creative exploration of the Library's digital assets and the histories that recorded.
This reconceptualized project can be seen as having a primary and secondary deliverable.
The primary deliverable is Collaging through Space and Time, an interactive collage tool intended for late elementary to early middle school students.
The secondary deliverable, is a workflow that shows other developers how to:
- Access the Library's API to retrieve digitial collections
- Perform subject/object detection and segmentation This secondary deliverable encapsulates our hope that Collaging through Space and Time will inspire other developers to consider the Library's collections when creating educational tools or games, further increasing the outreach of the Library. See Understanding the Collaging through Space and Time Project Github and Workflow for more information.
The process to design and develop the user interface for the DC Collage tool initially started with paper and pen sketches. In early sketches and iterations of the idea, the interface was not themed around DC specifically but around cities in general, and there would be a starting screen where the user would select a city to explore. The interface was conceptualized as a more curated, guided experience, with a small number of photos specifically selected for the user to click through for historical fun facts before using the photos in a collage.

We moved away from this approach, opting for a DC-themed, more exploratory and less curated experience, for three reasons:
- Consulting with the Professional Learning and Outreach Initiatives (PLOI) Office helped us realize that a K-12 age group might better appreciate a tool with more creative freedom, allowing for a wider range of use cases.
- Using a large quantity of images would allow for better research into machine learning models and their capabilities for such a task.
- Time constraints of a 10-week internship program.
For the second round of mock-ups, the interface was now envisioned as a specifically DC-themed virtual collage tool, where the user could filter through a large quantity of images using their tags and categories provided by the object detection model, and click on images for a link to the original image, tags, and other metadata. The user could also read documentation on the use of AI in the project, select different backgrounds for their collage, use paint tools to add color, and save and download the collage when finished.
This mock-up was first made in PowerPoint then translated to Figma, where interactivity was added.

At this stage, we consulted with the Digital Accessibility team before beginning work on translating the design to web technologies. From the Accessibility team, we were advised on optimally accessible color palettes and text fonts, on creating an adaptable design to the use of different screens and of different use of keyboards, and on including alternative text.
The final web interface was built using the HTML, CSS, and JavaScript languages. Certain features were prioritized and others dropped for the time frame. For more information on current and future web interface features, see Features.
Below is the current iteration of the web interface.

Collaging through Space and Time, at the time of launch, will have the following features and capabilities:
- Hot button linking to documentation detailing our use of AI, ethical considerations and concerns, and the steps taken to mitigate ethical concerns.
- Hot button linking to a feedback form that allows users to detail concerns they have with the use of AI; issues with subject and object detection, labeling, or segmentation; or general feedback and queries.
- "About this image" pop-up menu that displays image metadata and links back to the original digital item on the Library's website.
- A "Save" button that allows the user to download in different formats (jpeg, png, pdf, etc.) and/or scale their collage (by width and height).
- Undo and redo buttons to allow for incremental changes or corrections.
- A clear/restart button to allow for large-scale correction.
- An "Image Shuffle" button that allows users to shuffle through available images.
- A "Background Shuffle" button that allows users to shuffle through available backgrounds/canvases.
We hope to make Collaging through Space and Time a more dynamic collage tool in the future by adding the following features and capabilities:
- An extended reserve of images to pull from. We are currently pulling from three collections and would like to add more to increase the longevity and enjoyability of the tool.
- Add a paint tool that will make the collage more customizable and more closely resemble the physical practice of collaging.
- A "Filter" feature that will allow users to sort images by subject and object.
- A "Prompt" button that will generate a prompt for users who would like inspiration for their collage.
- An "Order and Arrange" feature (bring to front, send backward, etc.) for further manipulation.
- A title page to enhance the brand identity of the collage tool.
- An assortment of frames that allows users customize the borders of their collage.
- Allowing users to upload their own backgrounds. The goal of this feature is to allow users to combine their own personal experiences with that of history.
For Collaging through Space and Time to be successful, we needed a tool that would allow us to manipulate images at scale. The ability to detect and segments hundreds (and eventually thousands) of images was possible because of machine learning models like Faster R-CNN and EffcientSAM.
However, we were keenly aware of the biases baked into machine learning and the dubiousness of ethical data practices surrounding this technology. As you will see in Object Detection Evaluation: Faster R-CNN, we opted to use the Faster R-CNN object detection model, which utilizes the Microsoft Common Objects in Context (MS COCO) dataset. There are ethical concerns with how this dataset was trained and from where the data was retrieved, but due to the duration of this project (10 weeks), training a model with our own dataset would not be possible.
In the process of choosing an object detection model, we were particularly concerned with if the model would recognize subjects of various skin tones, if the labeling of such subjects were consistently correct (does the model recognize a darker-skinned person as a person?), and if the model's performance would remain consistent regardless of the quality of the image (black and white, sepia-tones, color, etc.).
We took extensive measures to ensure that the machine learning models we incorporated into Collaging through Space and Time would not cause harm to our mostly young demographic or to those of marginalized identities. You can read more about the testing we did to ensure efficacy in this area in Object Detection Evaluation: Faster R-CNN. You can also view our pre-planning worksheets where we evaluated the risks and benefits of using machine learning below:
The process of choosing an object segmentation model was much simpler and is explained in Object Segmentation Evaluation: EfficentSAM.
In Object Detection Model Evaluation, we go through the testing we did with five different object detection models and explain why we chose to work with the Faster R-CNN object detection model.
Note: Because of the public and governmental nature of the Library and given time constraints, we chose to opt for tools that were free to use.
Object Detection Model Evaluation
In Sample Collection Assessment, we assess whether the Faster R-CNN object detection model will work well with the quality of images we were hoping to use in Collaging through Space and Time. These images were often damaged and not in color.
A goal of this project was to use emerging technologies. In alignment with this goal, and in addition to using the Faster R-CNN model, the EfficientSAM model was selected to complete the instance segmentation portion of our workflow. The model was chosen based on its ease of use and popularity within the field of machine learning.
Given the bounding box information from the object detection model, the EfficientSAM model generates a binary mask of an instance (a singular object). To elaborate, the binary mask is a silhouette of the object. While some of the binary masks appeared complete, there were objects whose masks were imperfect, missing features, or contained holes. Before object cutouts could be extracted using the binary masks, morphological image processing techniques, such as closing, were used to refine the output and contribute to a more complete object cutout.
working on this
A major goal of the project is to highlight marginalized histories. We chose to approach this in a more holistic manner, and aimed for Collaging through Space and Time to capture the complexity of local history.
Initially, we wanted to capture two large cities (Washington, D.C. and Chicago, Illinois) and some aspect of rural America. We were drawn to Washington, D.C. because of the diversity within its community and history. Chicago also appealed to us for this very reason. Additionally, the Library's digital collections on these cities were vast and we felt we would have more than enough materials to work with. We felt that some aspect of rural America (we were particularly interested in Appalachia) would be good to add because it is not often explored as an aspect of American life and we wanted to highlight marginalized communities within this already marginalized region.
As with many decisions made in this project, the initial release of this project ended up having one large city. We chose Washington, D.C. for the above reasons, but because it is the location of the Library and felt this fitting for the launch of the project.
Below is a copy of our collection development spreadsheet. Please read the contents of the "Key" sheet thoroughly to understand the contents of the spreadsheet.
Metadata contains more information on our collection development process and the python scripting used to access the data necessary to build Collaging through Space and Time.
Image metadata from the Library’s digital collections played an important role in this project, including visualizations and exploration to help better understand the collection materials, use of metadata for image filtering and downloading at bulk, and selection of relevant metadata to save from the final image collection used in the DC Collage Tool interface.
To obtain an understanding of the contents of the digital collections pertaining to DC, the Free to Use and Reuse collection’s metadata was used -- through the metadata.csv file provided alongside that collection -- and organized into a pandas Data Frame containing only images with a location tag of “D.C.” From there, different categories were visualized, such as the source collection, contributors, and subjects heading, using simple graphs and word clouds. This exploration showed that the Carol M. Highsmith and National Photo Company collections would be best for collecting more DC images, and that the most common types of images would be of national landmarks, events, and festivals.
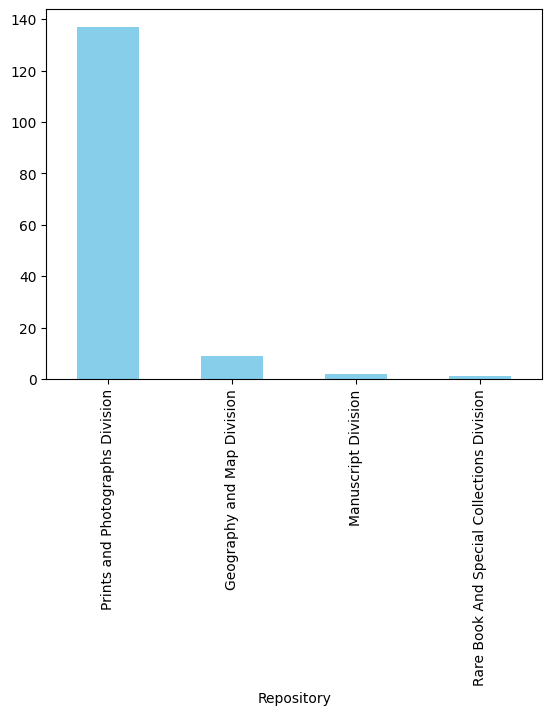


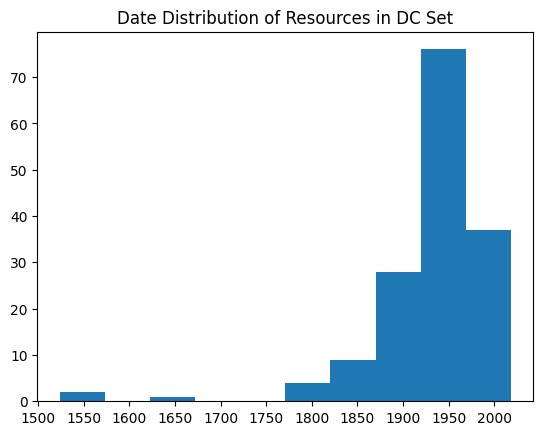
Once it came time to build and download images in bulk to create the DC image set, three collections were in use – the Free to Use and Reuse collection, the Carol M. Highsmith collection, and the National Photo Company collection. Since only the Free to Use and Reuse collection came with a readily pre-organized metadata csv file, we transitioned into using the Library API and JSON get requests instead. Each image’s URL was obtained from the metadata, and used to download that image, with the resource ID of the image as the download name. This was part 1, step 1 of the final project workflow.
Part 1, step 2 of the project workflow included taking the DC images and downloading select categories of their metadata to a newly created, specially organized JSON file. The categories selected to save were: the resource ID, the title, the image URL, the subjects, the date, the contributor names, the description, the alt text (if available), the source collection, and the original format of the image. Python was used for this task, with the help of the JSON and requests packages.