This repository contains project data, notes and scripts for artificial neural network based predicting of REN using factors that significantly affecting REN in water well.
The REN performance criterion equals the amount of the water injected in water well that is recoverable via the same well during a specified exatraction period.
The dataset used to train and verify the ANN derive from 5,000 MODFLOW-MT3DMS simulations. Inputs (independent variables) for these simulations differ for seven hydrogeological and operational factors that potentially impact REN. These factors are: background gradient, hydraulic conductivity, injection rate and duration, extraction rate and duration, storage duration, aquifer thickness, porosity, and longitudinal dispersivity. In MODFLOW-MT3DMS simulations extraction begins after storing the injected water in well for 12 months.
Data has been recieved from the author.
https://www.sciencedirect.com/science/article/pii/S0022169418304645?via%3Dihub
data folder consist of the data were used in this project
- Python 2.7
- tensorflow 2.0
- sklearn
- statsmodels
- pandas
- matplotlib
Herein, we describe the use of Python packages for this project.
Packages import:
import numpy as np
import tensorflow as tf
import os
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
from sklearn.base import BaseEstimator, TransformerMixin
import statsmodels.api as sm
import pandas as pd
import matplotlib.pyplot as plt
import picklePreprocessing of data
reading raw data
raw_csv_data = pd.read_csv("data/Data.out",delim_whitespace=True)Create a "ratio" column by diviving the values of "Ext" and "Inj" columns
raw_csv_data["ratio"]=raw_csv_data["Ext"]/raw_csv_data["Inj"]Standrizing data using sklearn preprocessing
scaled_data = preprocessing.scale(raw_csv_data)The results of preprocessing are as list type, We converted them to DataFrame with previous column names for them
Scaled_DF=pd.DataFrame(scaled_data,columns=raw_csv_data.columns)Now we can define dependent(y) and independents(x) columns
y=Scaled_DF['REN_3_2']
x1=Scaled_DF[['K', 'Inj', 'Por', 'b', 'CHD', 'ratio', 'DSP']]We can use statsmodel to see the OLS Regression Results summary
x = sm.add_constant(x1)
results = sm.OLS(y,x).fit()
print(results.summary())Using p values from the results of summary we relized "DSP" does not have significant effect on y values, so we do not need this column values for prediction. We drop the "DSP" column
Scaled_DF=raw_csv_data.drop(["DSP"],axis=1)Define the Inputs and Target columns for our model
scaled_inputs=Scaled_DF.iloc[:,0:6]
targets_all=Scaled_DF.iloc[:,6:]Changing the type of target_all to mumpy array
targets_all=targets_all.valuesShuffle the data
shuffled_indices = np.arange(scaled_inputs.shape[0])
np.random.shuffle(shuffled_indices)Use the shuffled indices to shuffle the inputs and targets.
shuffled_inputs = scaled_inputs[shuffled_indices]
shuffled_targets = targets_all[shuffled_indices]Count the total number of samples
samples_count = shuffled_inputs.shape[0]Split the dataset into train, validation, and test.
Count the samples in each subset, assuming we want 80-10-10 distribution of training, validation, and test. Naturally, the numbers are integers
train_samples_count = int(0.8 * samples_count)
validation_samples_count = int(0.1 * samples_count)The 'test' dataset contains all remaining data.
test_samples_count = samples_count - train_samples_count - validation_samples_countCreate variables that record the inputs and targets for training.
In our shuffled dataset, they are the first "train_samples_count" observations.
train_inputs = shuffled_inputs[:train_samples_count]
train_targets = shuffled_targets[:train_samples_count]Create variables that record the inputs and targets for validation.
They are the next "validation_samples_count" observations, folllowing the "train_samples_count" we already assigned.
validation_inputs = shuffled_inputs[train_samples_count:train_samples_count+validation_samples_count]
validation_targets = shuffled_targets[train_samples_count:train_samples_count+validation_samples_count]Create variables that record the inputs and targets for test. They are everything that is remaining.
test_inputs = shuffled_inputs[train_samples_count+validation_samples_count:]
test_targets = shuffled_targets[train_samples_count+validation_samples_count:]Save train, validation and test data as npz file
np.savez(os.path.join(Dir,'data_train'), inputs=train_inputs, targets=train_targets)
np.savez(os.path.join(Dir,'data_validation'), inputs=validation_inputs, targets=validation_targets)
np.savez(os.path.join(Dir,'data_test'), inputs=test_inputs, targets=test_targets)Building blocks of machine learning algotithm
let's create a temporary variable npz, where we will store each of the three Audiobooks datasets
npz = np.load(os.path.join(Dir,'data_train.npz'))to ensure that they are all floats, let's also take care of that
train_inputs = npz['inputs'].astype(np.float)
train_targets = npz['targets'].astype(np.float)we load the validation data in the temporary variable
npz = np.load(os.path.join(Dir,'data_validation.npz'))we can load the inputs and the targets in the same line
validation_inputs, validation_targets = npz['inputs'].astype(np.float), npz['targets'].astype(np.float)we load the test data in the temporary variable
npz = np.load(os.path.join(Dir,'data_test.npz'))we create 2 variables that will contain the test inputs and the test targets
test_inputs, test_targets = npz['inputs'].astype(np.float), npz['targets'].astype(np.float)Model
Set the input and output sizes
input_size = 6
output_size = 8Use same hidden layer size for all hidden layers. Not a necessity.
hidden_layer_size =200define how the model will look like
model = tf.keras.Sequential([
tf.keras.layers.Dense(hidden_layer_size, activation='sigmoid'),
tf.keras.layers.Dense(hidden_layer_size, activation='sigmoid'),
tf.keras.layers.Dense(hidden_layer_size, activation='sigmoid'),
tf.keras.layers.Dense(hidden_layer_size, activation='sigmoid'),
tf.keras.layers.Dense(hidden_layer_size, activation='sigmoid'),
tf.keras.layers.Dense(output_size, activation='linear')])Choose the optimizer and the loss function
model.compile(optimizer='adam', loss='mean_squared_error', metrics=['accuracy'])Training set the batch size
batch_size = 100set a maximum number of training epochs
max_epochs = 100set an early stopping mechanism.
early_stopping = tf.keras.callbacks.EarlyStopping(patience=1)Fit the model
model.fit(train_inputs,
train_targets,
batch_size=batch_size,
epochs=max_epochs,
callbacks=[early_stopping],
validation_data=(validation_inputs, validation_targets),
verbose = 2 )
test_loss, test_accuracy = model.evaluate(test_inputs, test_targets)
print('\nTest loss: {0:.2f}. Test accuracy: {1:.2f}%'.format(test_loss, test_accuracy*100.))Test result
Test loss: 0.02. Test accuracy: 98.20%
The Test result of Test accuarcy are good.
plot
Plot the model prediction vs measured data for one of the outputs test data.
predictions = model.predict(test_inputs)
plt.scatter(test_targets[:,6]*100,predictions[:,6]*100,color="blue")
plt.plot([0,100],[0,100],color="red")
plt.xlabel("Measured")
plt.ylabel("Predicted")
plt.tight_layout()
plt.show()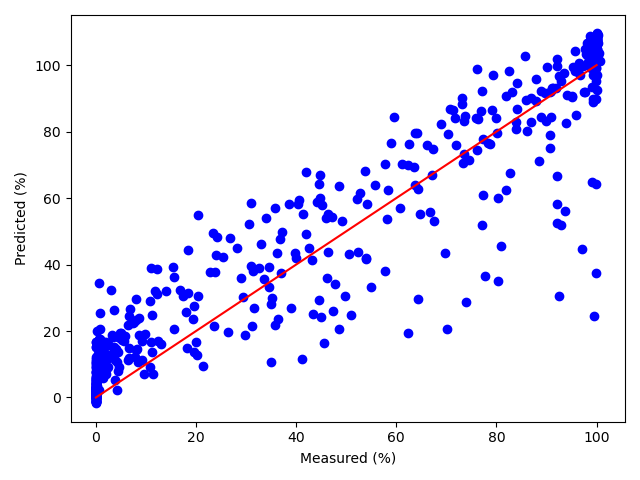
now that the plot looks good we can save the model for future uses.
Save the model
model.save("../Results/model.h5")