This repository contains the source code for the first and the second task of DeftEval 2020 competition, used by the University Politehnica of Bucharest (UPB) team to train and evaluate the models.
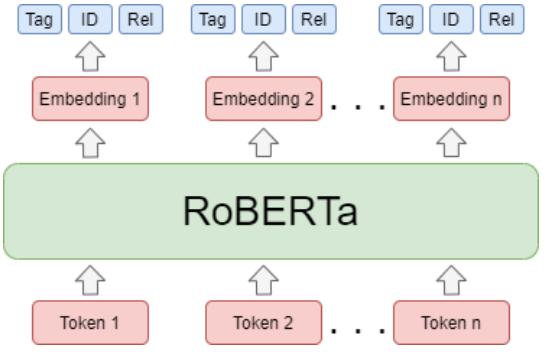
We fined-tuned frozen and non-frozen Transformer-based language models using the HuggingFace framework, together with a multi-task model that jointly predicts the outputs for the second and the third task.
The code for each task, with additional details on how to use it, can be found in task1 and task2 directories.
Make sure you have Python3 and PyTorch installed.
pip install -r requirements.txt
| Model | Valid-Prec | Valid-Rec | Valid-F1c | Test-Prec | Test-Rec | Test-F1 |
|---|---|---|---|---|---|---|
| Frozen-BERT | 76.0 | 75.1 | 75.5 | - | - | - |
| Frozen RoBERTa | 74.1 | 74.4 | 74.3 | - | - | - |
| Frozen SciBERT | 71.7 | 80.6 | 75.9 | - | - | - |
| Frozen XLNet | 66.8 | 70.8 | 68.7 | - | - | - |
| Frozen ALBERT | 77.2 | 69.3 | 73.0 | - | - | - |
| Fine-tuned BERT | 78.4 | 84.1 | 81.2 | - | - | - |
| Fine-tuned RoBERTa | 78.2 | 84.5 | 81.3 | 75.0 | 80.6 | 77.7 |
| Fine-tuned SciBERT | 79.4 | 79.7 | 79.6 | - | - | - |
| Fine-tuned XLNet | 75.5 | 85.2 | 80.1 | - | - | - |
| Fine-tuned ALBERT | 69.5 | 85.9 | 76.8 | - | - | - |
| Model | Valid-Prec | Valid-Rec | Valid-F1c | Test-Prec | Test-Rec | Test-F1 |
|---|---|---|---|---|---|---|
| Frozen BERT+CRF | 27.1 | 39.8 | 26.1 | - | - | - |
| Frozen RoBERTa+CRF | 32.7 | 27.7 | 22.6 | - | - | - |
| Frozen SciBERT+CRF | 29.0 | 37.5 | 26.2 | - | - | - |
| Frozen XLNet+CRF | 29.6 | 33.4 | 26.8 | - | - | - |
| Frozen Multi-task | 4.0 | 8.9 | 8.0 | - | - | - |
| Fine-tuned BERT+CRF | 47.9 | 51.7 | 45.6 | - | - | - |
| Fine-tuned RoBERTa+CRF | 41.4 | 66.4 | 46.0 | 39.4 | 55.6 | 43.9 |
| Fine-tuned SciBERT+CRF | 46.7 | 46.6 | 41.7 | - | - | - |
| Fine-tuned XLNet+CRF | 33.0 | 58.5 | 39.2 | - | - | - |
| Fine-tuned Multi-task | 25.7 | 25.2 | 25.5 | - | - | - |
If you are using this repository, please consider citing the following paper as a thank you to the authors:
@inproceedings{avram-etal-2020-upb,
title = "{UPB} at {S}em{E}val-2020 Task 6: Pretrained Language Models for Definition Extraction",
author = "Avram, Andrei-Marius and
Cercel, Dumitru-Clementin and
Chiru, Costin",
booktitle = "Proceedings of the Fourteenth Workshop on Semantic Evaluation",
month = dec,
year = "2020",
address = "Barcelona (online)",
publisher = "International Committee for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.semeval-1.97",
pages = "737--745",
abstract = "This work presents our contribution in the context of the 6th task of SemEval-2020: Extracting Definitions from Free Text in Textbooks (DeftEval). This competition consists of three subtasks with different levels of granularity: (1) classification of sentences as definitional or non-definitional, (2) labeling of definitional sentences, and (3) relation classification. We use various pretrained language models (i.e., BERT, XLNet, RoBERTa, SciBERT, and ALBERT) to solve each of the three subtasks of the competition. Specifically, for each language model variant, we experiment by both freezing its weights and fine-tuning them. We also explore a multi-task architecture that was trained to jointly predict the outputs for the second and the third subtasks. Our best performing model evaluated on the DeftEval dataset obtains the 32nd place for the first subtask and the 37th place for the second subtask. The code is available for further research at: \url{https://github.com/avramandrei/DeftEval}",
}