This project is an implementation and optimization of the forward pass of a convolution layer using CUDA. Convolutional layers are the primary building blocks of convolutional neural networks (CNNs), which are used for tasks like image classification, object detection, natural language processing and recommendation systems. This implementation achieves 0.886 (88.6%) classification accuracy.
The forward pass is implemented for a modified version of the LeNet5 architecture shown below:
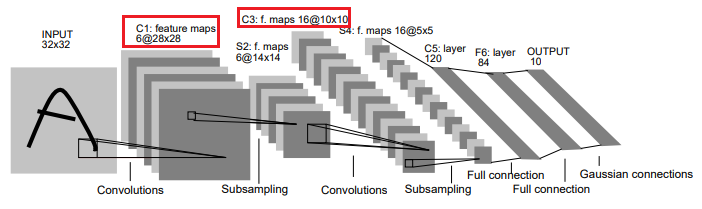
Source: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
The CUDA implementation of the convolutional layer will be used to perform inference for layers C1 and C3 (shown in red) in the figure above. This leverages the mini-dnn-cpp (Mini-DNN) framework for implementing the modified LeNet-5.
Readme Contents:
- What is the forward pass of a convolution layer?
- CPU Implementation
- GPU (Parallelized) Implementation
- Optimized GPU (Parallelized) Implementation
- Instructions on how to compile and test code
The forward pass of a convolutional layer in a convolutional neural network (CNN) involves applying convolutional filters (also known as kernels) to the input data to produce feature maps. Each filter in the convolutional layer learns to detect different features or patterns in the input data, such as edges, textures, or more complex features, depending on the depth of the layer and the number of filters used. The combination of multiple filters allows the network to learn hierarchical representations of the input data, making CNNs particularly effective for image and spatial data analysis.
In summary, we perform the following operation:
for b = 0 .. B // for each image in the batch
for m = 0 .. M // for each output feature maps
for h = 0 .. H_out // for each output element
for w = 0 .. W_out
{
y[b][m][h][w] = 0;
for c = 0 .. C // sum over all input feature maps
for p = 0 .. K // KxK filter
for q = 0 .. K
y[b][m][h][w] += x[b][c][h + p][w + q] * k[m][c][p][q]
}
This animation can help visualize this process better:
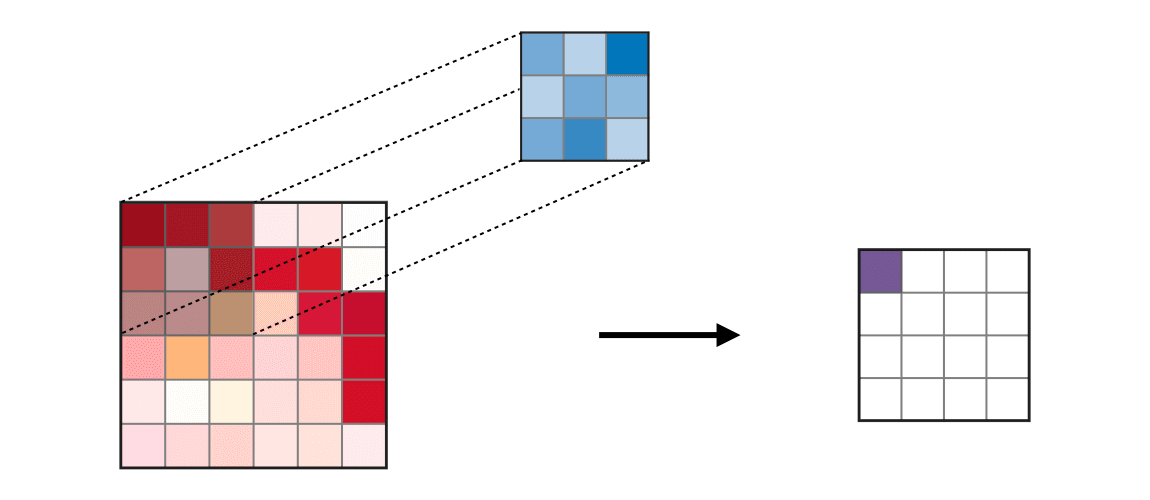
Source: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks#layer
The network is tested on the Fashion MNIST dataset which contains 10,000 single channel images each of dimensions 86x86 but we will only use 1000 of these at a time. The output layer consists of 10 nodes, where each node represents the likelihood of the input belonging to one of the 10 classes (T-shirt, dress, sneaker, boot, etc).
File: src/layer/custom/cpu-new-forward.cc
Classification Accuracy: 0.886
- Direct translation of pseudocode in "What is the forward pass of a convolution layer?" Readme section
File: src/layer/custom/gpu-new-forward-basic.cu
Classification Accuracy: 0.886
Tested on NVIDIA 1080ti GPU
Runtime:
File: src/layer/custom/gpu-new-forward-basic.cu
Classification Accuracy: 0.886
Tested on NVIDIA 1080ti GPU
Runtime:
Optimizations:
- Shared Memory convolution
- Weight matrix (kernel values) in constant memory
- Tuning with restrict and loop unrolling (considered as one optimization only if you do both)
- Sweeping various parameters to find best values (block sizes, amount of thread coarsening)
- Exploiting parallelism in input images, input channels, and output channels.
- Multiple kernel implementations for different layer sizes
Implementation uses tiling, shared memory, and constant memory.
CUDA File
- Included is a Makefile which compiles the file and links it with the libgputk CUDA library automatically. (NOTE: By default, the filepath in the Makefile is
src/layer/custom/new-forward.cu. To run the above CUDA files, edit to the corresponding GPU implementation file path specified above.) The file can be run by typingmake m2from the LeNet5_CNN folder (i.e., Repo folder). It generates am2output executable.
C++ File
- The makefile can be found here. The file can be run by typing
make m1from the LeNet5_CNN folder (i.e., Repo folder). It generates am1output executable.
Use the make run command to test the program, which will run your program on a batch size of 1000 images. This will automatically compile your source (equivalent to executing make m2 and then running ./m2 1000, or executing make m1 and then running ./m1 1000).
The project was completed from Feb 2023 - Mar 2023 while taking UCSD's Introduction to Parallel Computing course. This project is originally from UIUC ECE408 and builds off a number of open source projects including the Fashion MNIST dataset, mini-dnn-cpp, and the Eigen project.