This repository contains the official evaluation code for the U-MATH and
U-MATH provides a set of 1,100 university-level mathematical problems, while µ-MATH complements it with a meta-evaluation framework focusing on solution judgment with 1084 LLM solutions.
- 📊 U-MATH benchmark at Huggingface
- 🔎 μ-MATH benchmark at Huggingface
- 🗞️ Paper
- 👾 Evaluation Code at GitHub
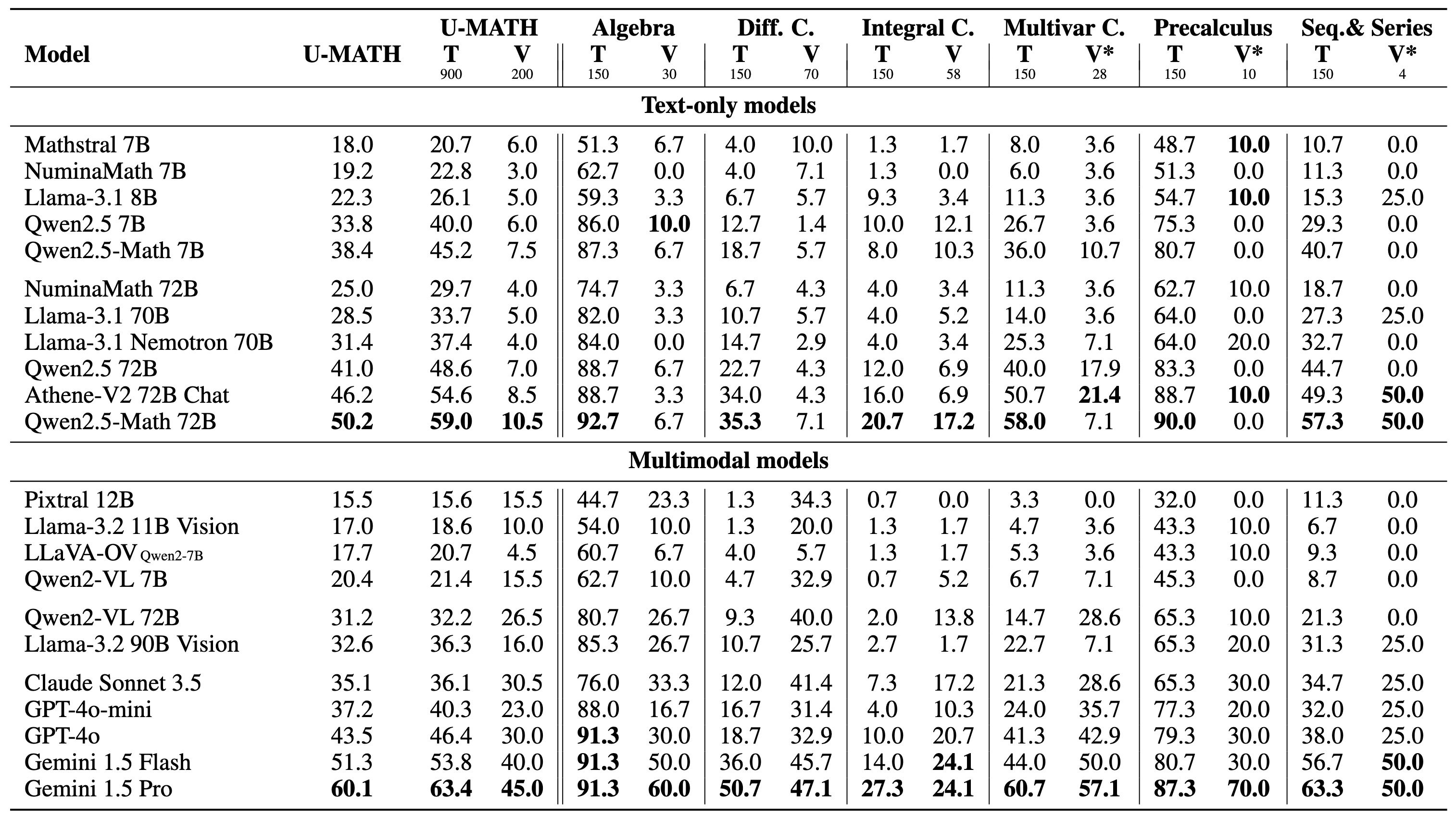
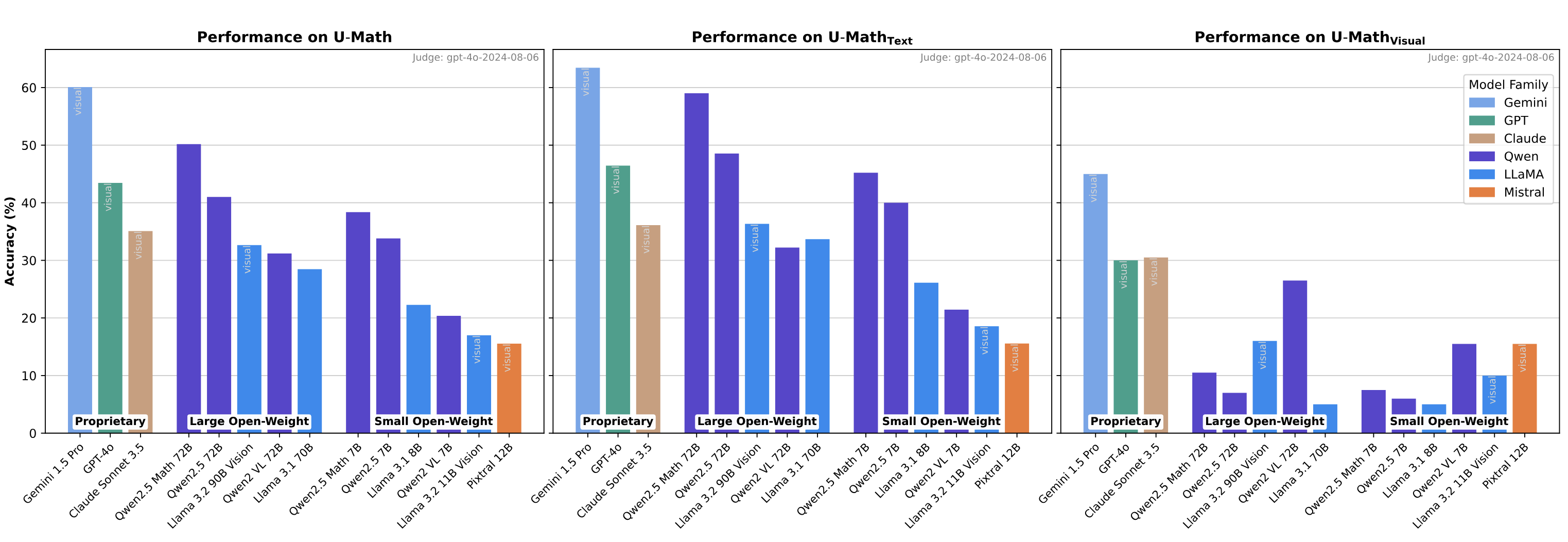


This repository provides scripts for solving and evaluating the U-MATH and μ-MATH datasets.
File Structure
solve_u_math.py: Script to generate solutions for U-MATH problems using an OpenAI-compatible endpoint (e.g. gpt-4o or VLLM).judge_u_math.py: Script to evaluate the correctness of U-MATH solutions.judge_mu_math.py: Script to evaluate the quality of LLM judgments for μ-MATH solutions.README.md: This file.requirements.txt: List of dependencies required for running the scripts.
Download the repository and install the dependencies:
git clone https://github.com/toloka/u-math.git
cd u-math
pip install -r requirements.txtTo generate solutions for U-MATH problems, run the following command:
python solve_u_math.py --base_url <BASE_URL> --api_key <YOUR_API_KEY> --model <MODEL_NAME> --output_file predictions_u_math.jsonTo evaluate the correctness of U-MATH solutions, run the following command:
python judge_u_math.py --base_url <BASE_URL> --api_key <YOUR_API_KEY> --model <MODEL_NAME> --predictions_file predictions_u_math.json --output_file judgments_u_math.jsonTo evaluate the quality of LLM judgments for μ-MATH solutions, run the following command:
python judge_u_math.py --base_url <BASE_URL> --api_key <YOUR_API_KEY> --model <MODEL_NAME> --output_file judgments_mu_math.json- The contents of the μ-MATH's machine-generated
model_outputcolumn are subject to the underlying LLMs' licensing terms. - Contents of all the other dataset U-MATH and μ-MATH fields, as well as the code, are available under the MIT license.
If you use U-MATH or μ-MATH in your research, please cite the paper:
@inproceedings{umath2024,
title={U-MATH: A University-Level Benchmark for Evaluating Mathematical Skills in LLMs},
author={Konstantin Chernyshev, Vitaliy Polshkov, Ekaterina Artemova, Alex Myasnikov, Vlad Stepanov, Alexei Miasnikov and Sergei Tilga},
year={2024}
}For inquiries, please contact [email protected]