



Welcome to the official GitHub for SynthLabs.ai 👋
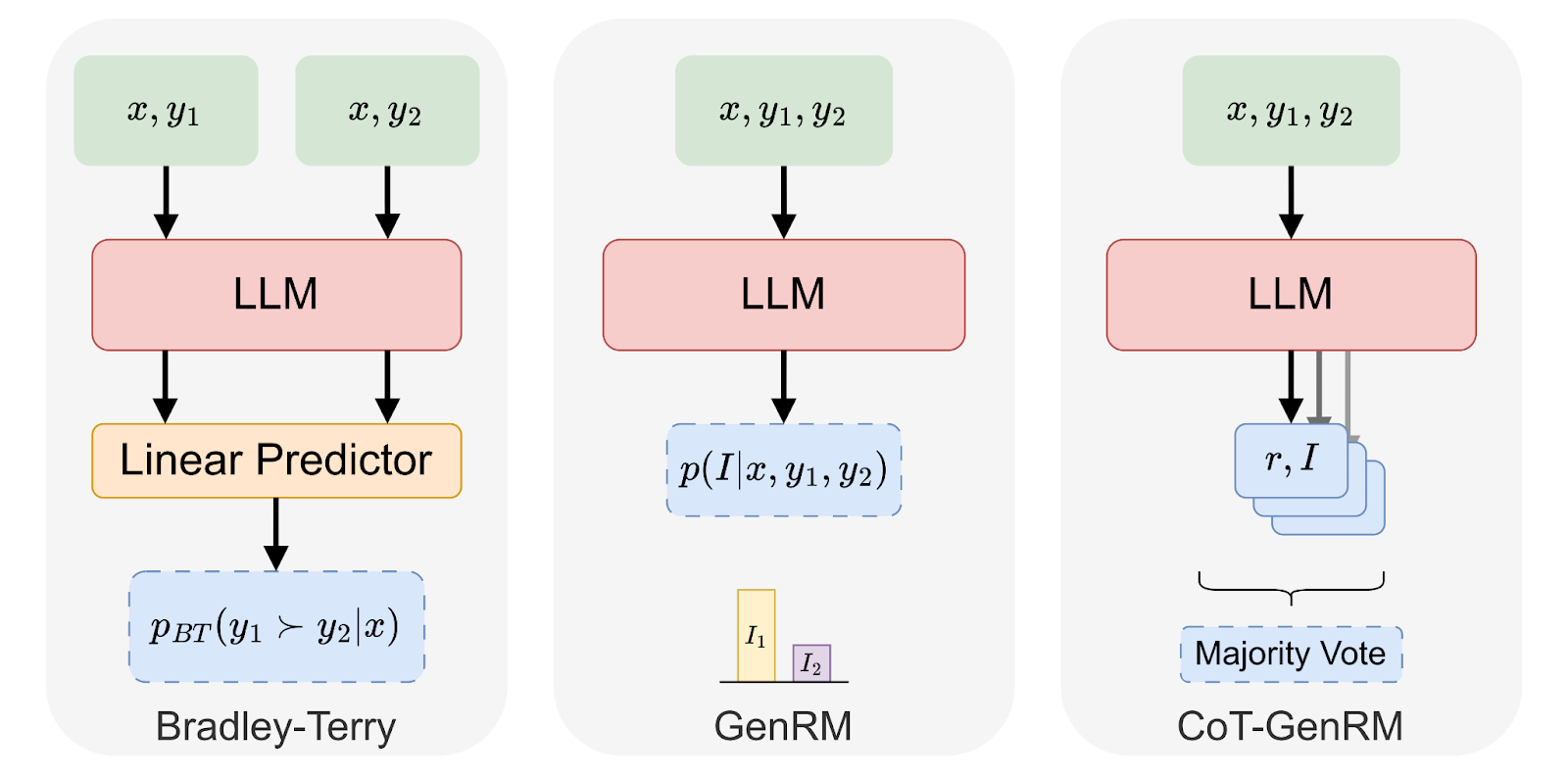
Our latest work introduces Generative Reward Models (GenRM) and Chain-of-Thought GenRM (CoT-GenRM), a framework for preference learning that unifies RLHF and RLAIF approaches. We demonstrate that by combining iterative preference learning algorithms (STaR-DPO) with CoT-GenRM, we can train models that achieve comparable performance on in-domain data to Bradley-Terry Reward Models (currently best-in-class method), while vastly outperforming them on out-of-domain data (up to 45% improvement). All while providing rationales for the model's predicted preference. The GenRM framework unifies language models and reward models under a single next-token prediction framing, reducing the infrastructure overhead required. The development of CoT-GenRM and STaR-DPO opens up new possibilities for AI alignment:
- More Robust AI Systems: Create AI systems that better generalize to new situations and maintain alignment with human values.
- Efficient Scaling: Allow for more rapid iteration and refinement of AI behavior.
- Potential for Personalization: Address the challenge of aligning AI with diverse and potentially conflicting human views.
- Improved Reasoning Capabilities: Pave the way for AI systems that can continually improve their own reasoning and decision-making processes.
Contributions from Dakota Mahan*, Duy Van Phung*, Rafael Rafailov*, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak*.
Learn more:
This work introduces PERSONA, a framework for evaluating the ability of language models to align with a diverse set of user values, using 1,586 synthetic personas, 3,868 prompts, and 317,200 preference pairs. We focus on pluralistic alignment because we want langauge models that can reflect a diverse set of values, not just the majority opinion, and we don't prescribe to a one-size-fits-all approach. PERSONA is synthetically constructed from U.S. census data, allowing us to generate a large, diverse dataset while ensuring privacy and reproducibility. The dataset and evaluation framework can be used for a variety of purposes, inlcluding: (1) a test bed, (2) a development environment, (3) a reproducible evaluation for pluralistic alignment approaches, (4) the personalization of language models, (5) and for preference elicitation.
Contributions from Louis Castricato*, Nathan Lile*, Rafael Rafailov, Jan-Philipp Fränken, and Chelsea Finn.
Learn more:

This work represents a significant advancement in the field of controllable language models. This research addresses the 'Pink Elephant Problem' - instructing language models to avoid certain topics ("Pink Elephants") and focus on preferred ones ("Grey Elephants"). Key highlights:
-
Controllable Generation: Dynamically adjust language models at inference time for diverse needs across multiple contexts
-
Direct Principle Feedback (DPF): We introduce a novel simplification of Constitutional AI, Direct Principle Feedback, which directly applies principles to critiques and revisions without the need for ranking responses.
-
Significant Performance Improvements: After fine-tuning with DPF on our synthetic Pink Elephants dataset, our 13B fine-tuned LLaMA 2 model outperformed existing models and matched the performance of GPT-4 on our curated test set for the Pink Elephant Problem.
Contributions from Louis Castricato, Nathan Lile, Suraj Anand, Hailey Schoelkopf, Siddharth Verma, and Stella Biderman.
Learn more:
- Interviewing Louis Castricato on RLHF, Synth Labs, and the Future of Alignment
- New Microsoft-Backed Startup Wants to Make AI Work As Intended
We're always looking for talented individuals to join our team. If you're passionate about AI and want to work on cutting-edge research, check out our career opportunities.


Join us in shaping an aligned and impactful AI future! 🤝