Mingrui Zhu 1 Xuan Wang 2 Jue Wang 2 Nannan Wang 1
SIGGRAPH Asia 2022 Conference Track

We present VideoReTalking, a new system to edit the faces of a real-world talking head video according to input audio, producing a high-quality and lip-syncing output video even with a different emotion. Our system disentangles this objective into three sequential tasks:
(1) face video generation with a canonical expression
(2) audio-driven lip-sync and
(3) face enhancement for improving photo-realism.
Given a talking-head video, we first modify the expression of each frame according to the same expression template using the expression editing network, resulting in a video with the canonical expression. This video, together with the given audio, is then fed into the lip-sync network to generate a lip-syncing video. Finally, we improve the photo-realism of the synthesized faces through an identity-aware face enhancement network and post-processing. We use learning-based approaches for all three steps and all our modules can be tackled in a sequential pipeline without any user intervention.
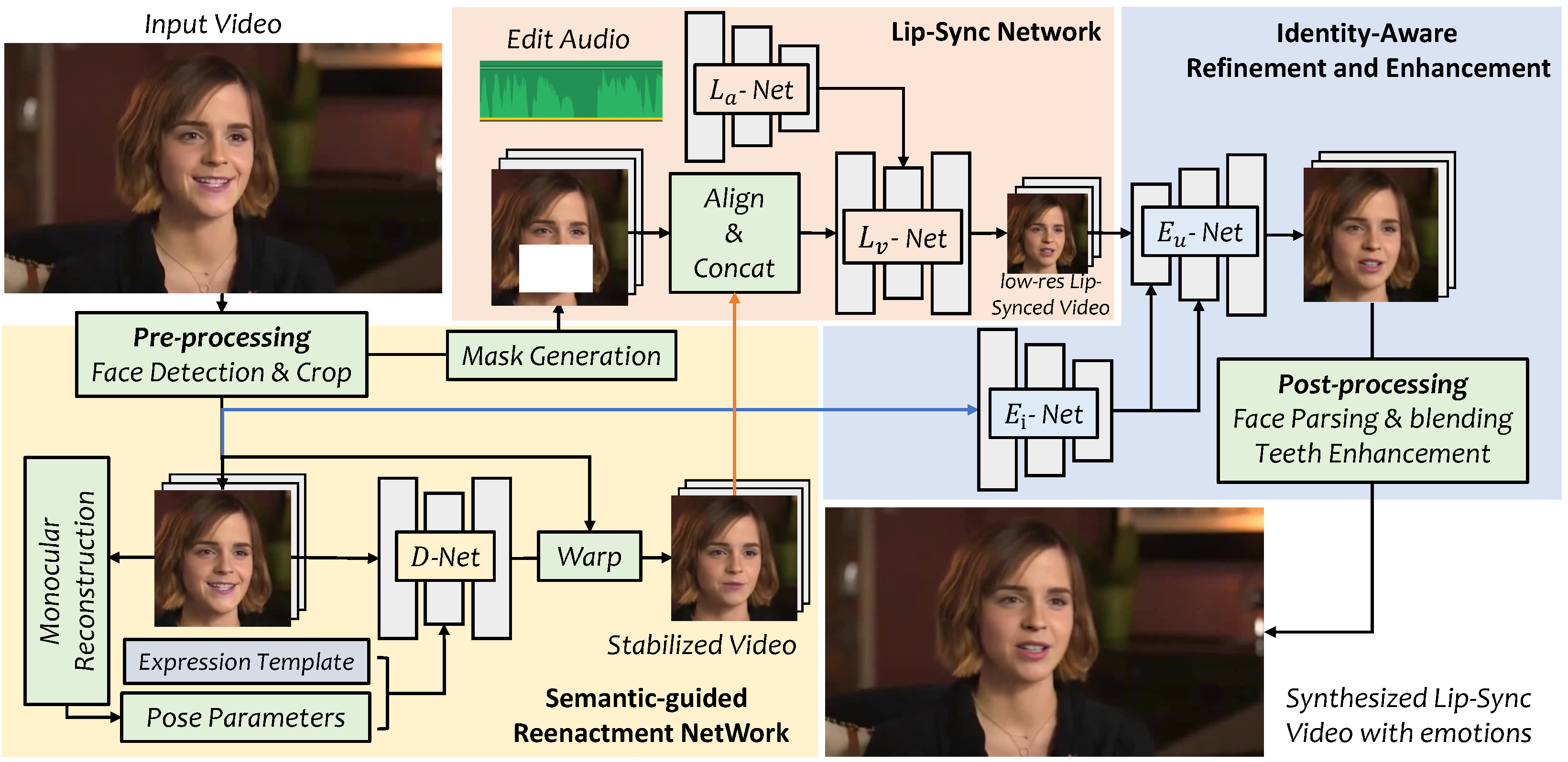
Pipeline
Results_in_the_wild.mp4
git clone https://github.com/vinthony/video-retalking.git
cd video-retalking
conda create -n video_retalking python=3.8
conda activate video_retalking
conda install ffmpeg
# Please follow the instructions from https://pytorch.org/get-started/previous-versions/
# This installation command only works on CUDA 11.1
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
Please download our pre-trained models and put them in ./checkpoints.
python3 inference.py \
--face examples/face/1.mp4 \
--audio examples/audio/1.wav \
--outfile results/1_1.mp4
This script includes data preprocessing steps. You can test any talking face videos without manual alignment. But it is worth noting that DNet cannot handle extreme poses.
You can also control the expression by adding the following parameters:
--exp_img: Pre-defined expression template. The default is "neutral". You can choose "smile" or an image path.
--up_face: You can choose "surprise" or "angry" to modify the expression of upper face with GANimation.
If you find our work useful in your research, please consider citing:
@misc{cheng2022videoretalking,
title={VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild},
author={Kun Cheng and Xiaodong Cun and Yong Zhang and Menghan Xia and Fei Yin and Mingrui Zhu and Xuan Wang and Jue Wang and Nannan Wang},
year={2022},
eprint={2211.14758},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Thanks to Wav2Lip, PIRenderer, GFP-GAN, GPEN, ganimation_replicate, STIT for sharing their code.
- StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN (ECCV 2022)
- CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior (CVPR 2023)
- SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation (CVPR 2023)
- DPE: Disentanglement of Pose and Expression for General Video Portrait Editing (CVPR 2023)
- 3D GAN Inversion with Facial Symmetry Prior (CVPR 2023)
- T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations (CVPR 2023)
This is not an official product of Tencent.
1. Please carefully read and comply with the open-source license applicable to this code before using it.
2. Please carefully read and comply with the intellectual property declaration applicable to this code before using it.
3. This open-source code runs completely offline and does not collect any personal information or other data. If you use this code to provide services to end-users and collect related data, please take necessary compliance measures according to applicable laws and regulations (such as publishing privacy policies, adopting necessary data security strategies, etc.). If the collected data involves personal information, user consent must be obtained (if applicable). Any legal liabilities arising from this are unrelated to Tencent.
4. Without Tencent's written permission, you are not authorized to use the names or logos legally owned by Tencent, such as "Tencent." Otherwise, you may be liable for your legal responsibilities.
5. This open-source code does not have the ability to directly provide services to end-users. If you need to use this code for further model training or demos, as part of your product to provide services to end-users, or for similar use, please comply with applicable laws and regulations for your product or service. Any legal liabilities arising from this are unrelated to Tencent.
6. It is prohibited to use this open-source code for activities that harm the legitimate rights and interests of others (including but not limited to fraud, deception, infringement of others' portrait rights, reputation rights, etc.), or other behaviors that violate applicable laws and regulations or go against social ethics and good customs (including providing incorrect or false information, spreading pornographic, terrorist, and violent information, etc.). Otherwise, you may be liable for your legal responsibilities.