Resource Classes #1481
Open
Resource Classes #1481
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
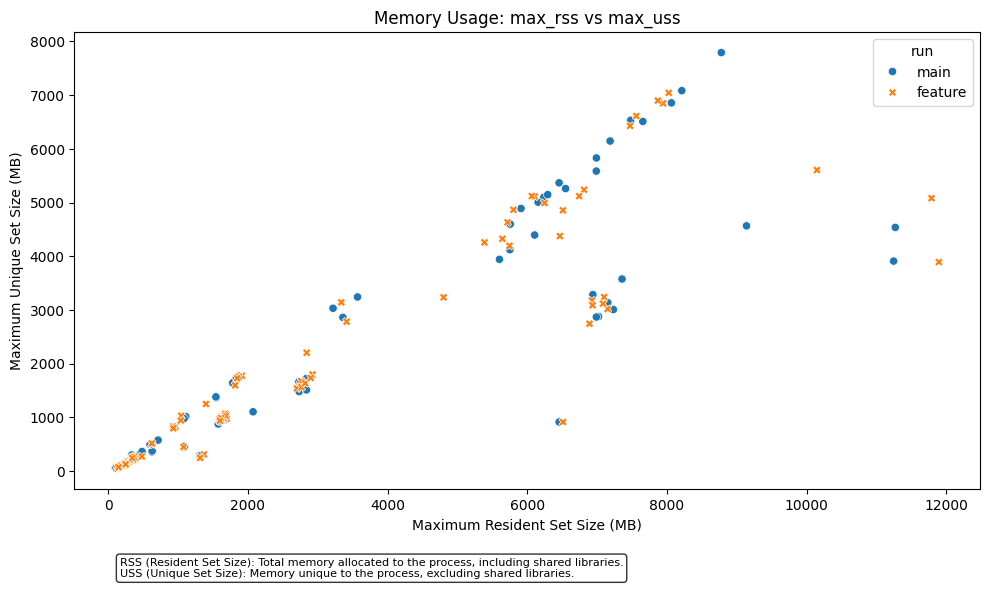
Validator ReportI am the Validator. Download all artifacts here. General Plots comparison
Files comparison
NRMSE: Normalized (combined-min-max) Root Mean Square Error Model Metrics Benchmarks

Comparing |












for more information, see https://pre-commit.ci
for more information, see https://pre-commit.ci
fc34742 to
454f473
Compare
for more information, see https://pre-commit.ci
for more information, see https://pre-commit.ci
for more information, see https://pre-commit.ci
8e04539 to
bab427d
Compare
for more information, see https://pre-commit.ci
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Closes #713.
Closes #290.
Changes proposed in this Pull Request
This PR adds the option to split renewable potentials and time series into a configurable number of resource classes per carrier and clustered region. The binning is done based on the average capacity factors.
With the above setting, each region would get 4 onshore wind generators, each with different
p_max_puandp_nom_max. This allows more accurate renewable time series even when the spatial resolution might be highly aggregated (e.g. one region per country).The default number of resource classes is kept at one per cluster, which is recommended for scenarios with high spatial resolution.
The feature replaces the pre-clustering workaround that used to be in
simplify_networkto have multiple renewable generators of one carrier inside a single cluster.The main magic happens in
build_renewable_profiles. Mainly, a new dimension "bin" is added to the outputxarray.Datasetand a new.geojsonof clustered regions split by resource classes is exported, which later helps with assigning existing wind and solar capacities not only to the buses but also to the correct resource class. The resource classes are numbered from 0 (lowest capacity factor segment) to N (highest).Here's an example clustered region ("BE0 0") with the average onshore wind capacity factors of the cutout grid cells involved:
If the number of resource classes is 2, each cutout grid cell of the clustered region would be allocated to one of the two resource classes. In this simple case, the corresponding bins would be defined by the borders
cf.min(),cf.min() + (cf.max() - cf.min()) / 2andcf.max()- i.e. simple linear spacing. Note that the bins are specific to the clustered region! Different regions have different splits!Based on this, we can now also split the shapefile of the clustered region (e.g. to allocate existing RES capacities to the right resource class). Note that these splits do not have to be contiguous! You could have resource class 0 in the North and South and resource class 1 in the middle!
Since the resource class indicator matrix is multiplied by the availability matrix, the potentials / land eligibility are also geographically split. Of course, the overlaps of involved grid cells into other clustered regions are also taken care of! The potentials (
p_nom_max) now have coordinates (bus, bin):The output of
build_renewable_profilesnow looks like this (which is then handled in the subsequent rules and scripts):Another feature added as an aside is the use of Global Energy Monitor (GEM) renewable capacity data, which now replaces the less complete OPSD VRE data in
add_electricity. As a note for a future PR, this should also be used foradd_existing_baseyearvery soon, but I intentionally left it out here to reduce complexity.Furthermore, a small functionality reduction is included in this PR. The technology mapping from
powerplantmatchingtopypsanow has to be 1:1 rather than 1:n. I.e. existing offshore wind has to be-dcor-ac. Since it aligns with how it is done inadd_existing_baseyear, in my view, this is a negligible drawback.TODO
Checklist
envs/environment.yaml.config/config.default.yaml.doc/configtables/*.csv.doc/data_sources.rst.doc/release_notes.rstis added.