最近需要在2019年版本的nano SDK上部署模型, 目前只找到了直接推理的方法。
| item | 版本 |
|---|---|
| CUDA | 10.0.0 |
| tensorrt | 5.1.6.1 |
| jetpack | 4.2.2 |
| opencv | 3.3.1 |
| pytorch | 1.2.0 |
pytorch在这里下载whl文件:
https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-10-now-available/72048
data.zip数据集是yolo格式:
之后clone 这个repo 里面有所有用得到的code
git clone https://github.com/Promethe-us/Yolov3-tinyDeployOnNano然后按照Yolov3-tinyDeployOnNano/yolov3-tiny.ipynb教程进行训练,得到backup80.pt
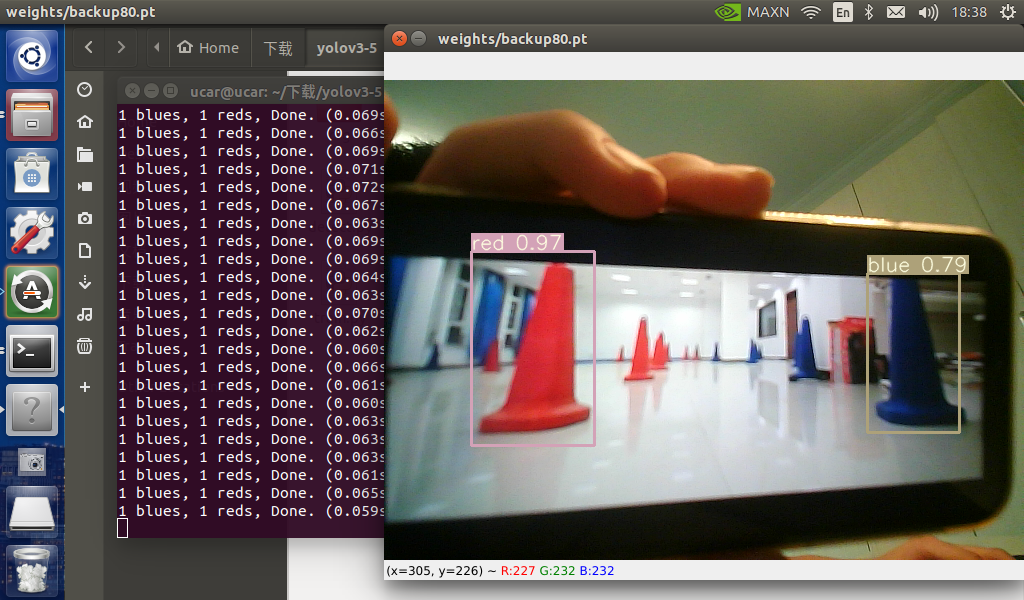
我是直接进行推理的,但是 yolov3-tiny (input:320×320)的帧率为20FPS,感觉还凑活
-
将 backup80.pt 放到目录yolov3/下
-
将 datasets.cfg 放到yolov3/下
-
将 labels.names 放在yolov3/data/下
-
修改detect,py中的
def detect( . . . save_images=False, web_cam=True )
(你所克隆的仓库都是改好的,只需要把backup80.pt放到yolov3/下即可)
!python detect.py --img-size 320 --weights weights/backup80.pt --cfg model.cfg --data-cfg datasets.data
推理结果: