
Modular Deep Reinforcement Learning framework in PyTorch.
 |
 |
 |
 |
| BeamRider | Breakout | Enduro | Pong |
 |
 |
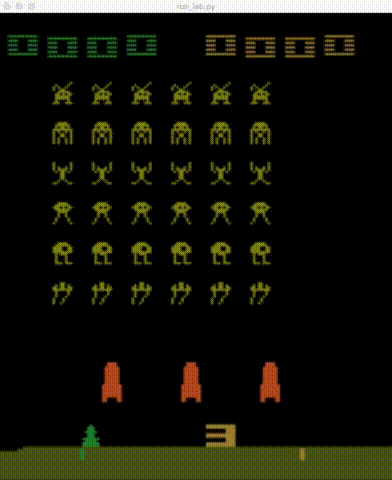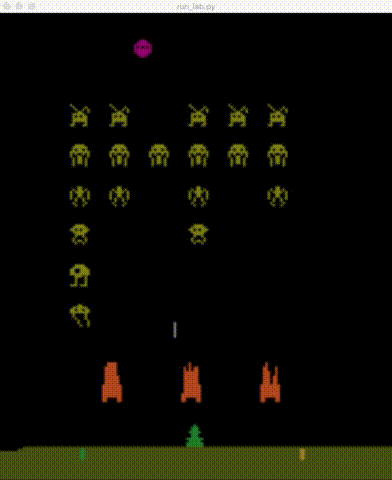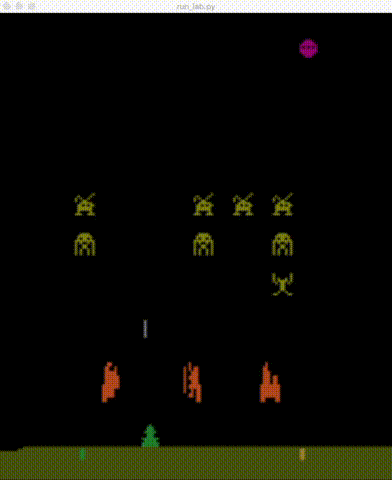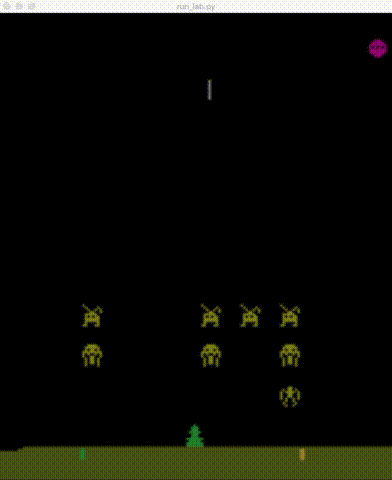 |
|
| Qbert | Seaquest | SpaceInvaders |
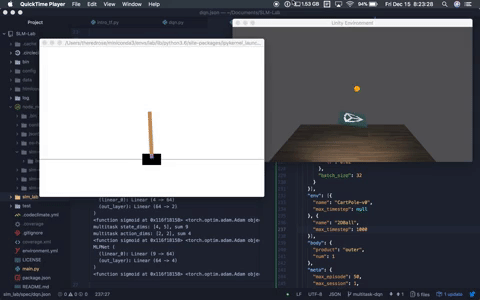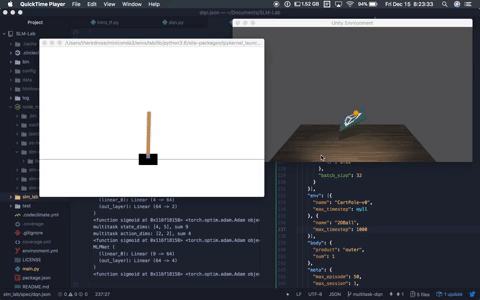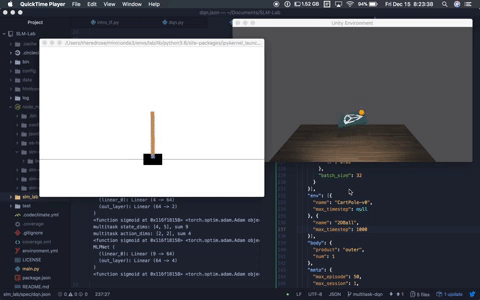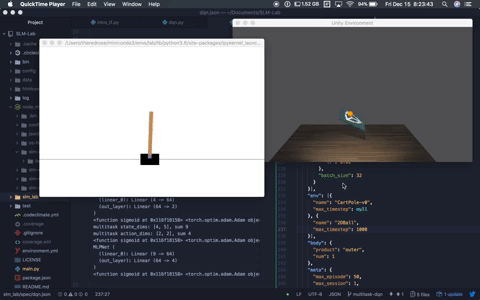 Multitask DQN solving OpenAI Cartpole-v0 and Unity Ball2D. Multitask DQN solving OpenAI Cartpole-v0 and Unity Ball2D. |
 DQN Atari Pong solution in SLM Lab. DQN Atari Pong solution in SLM Lab. |
 DDQN Lunar solution in SLM Lab. DDQN Lunar solution in SLM Lab. |
| References | |
|---|---|
| Github | Github repository |
| Installation | How to install SLM Lab |
| Documentation | Usage documentation |
| Benchmark | Benchmark results |
| Tutorials | Tutorial resources |
| Contributing | How to contribute |
| Roadmap | Research and engineering roadmap |
| Gitter | SLM Lab user chatroom |
SLM Lab is created for deep reinforcement learning research and applications. The design was guided by four principles
- modularity
- simplicity
- analytical clarity
- reproducibility
- makes research easier and more accessible: reuse well-tested components and only focus on the relevant work
- makes learning deep RL easier: the algorithms are complex; SLM Lab breaks them down into more manageable, digestible components
- components get reused maximally, which means less code, more tests, and fewer bugs
- the components are designed to closely correspond to the way papers or books discuss RL
- modular libraries are not necessarily simple. Simplicity balances modularity to prevent overly complex abstractions that are difficult to understand and use
- hyperparameter search results are automatically analyzed and presented hierarchically in increasingly granular detail
- it should take less than 1 minute to understand if an experiment yielded a successful result using the experiment graph
- it should take less than 5 minutes to find and review the top 3 parameter settings using the trial and session graphs
- only the spec file and a git SHA are needed to fully reproduce an experiment
- all the results are recorded in BENCHMARK.md
- experiment reproduction instructions are submitted to the Lab via
resultPull Requests - the full experiment datas contributed are public on Dropbox
- numerous canonical algorithms (listed below)
- reusable and well-tested modular components: algorithm, network, memory, policy
- simple and easy to use for building new algorithms
- supports multiple environments:
- OpenAI gym
- VizDoom (credit: joelouismarino)
- Unity environments with prebuilt binaries
- contributions welcome!
- supports multi-agents, multi-environments
- API for adding custom environments
- scalable hyperparameter search using ray
- analytical clarity with auto-generated results and graphs at session, trial, experiment levels
- fitness metric as a richer measurement of an algorithm's performance
SLM Lab implements most of the recent canonical algorithms and various extensions. These are used as the base of research. All the implementations follow this design:
-
Agent: the base class containing all the components. It has the API methods to interface with the environment.Algorithm: the main class containing the implementation details of a specific algorithm. It contains components that are reusable.Net: the neural network for the algorithm. An algorithm can have multiple networks, e.g. Actor-Critic, DDQN.
Body: connects the agent-env, and stores the proper agent-env data, such as entropy/log_prob. Multitask agent will have multiple bodies, each handling a specific environment. Conversely, a multiagent environment will accept multiple bodies from different agents. Essentially, each body keeps track of an agent-env pair.Memory: stores the numpy/plain type data produced from the agent-env interactions used for training.
-
BaseEnv: the environment wrapper class. It has the API methods to interface with the agent. Currently, the Lab contains:OpenAIEnvfor OpenAI gymUnityEnvfor Unity ML-Agents
code: slm_lab/agent/algorithm
Various algorithms are in fact extensions of some simpler ones, and they are implemented as such. This allows for concise and safer code.
Policy Gradient:
- REINFORCE
- AC (Vanilla Actor-Critic)
- shared or separate actor critic networks
- plain TD
- entropy term control
- A2C (Advantage Actor-Critic)
- extension of AC with with advantage function
- N-step returns as advantage
- GAE (Generalized Advantage Estimate) as advantage
- PPO (Proximal Policy Optimization)
- extension of A2C with PPO loss function
- SIL (Self-Imitation Learning)
- extension of A2C with off-policy training on custom loss
- PPOSIL
- SIL with PPO instead of A2C
Using the lab's unified API, all the algorithms can be distributed hogwild-style. Session takes the role of workers under a Trial. Some of the distributed algorithms have their own name:
- A3C (Asynchronous A2C / distributed A2C)
- DPPO (Distributed PPO)
Value-based:
- SARSA
- DQN (Deep Q Learning)
- boltzmann or epsilon-greedy policy
- DRQN (DQN + Recurrent Network)
- Dueling DQN
- DDQN (Double DQN)
- DDRQN
- Dueling DDQN
- Hydra DQN (multi-environment DQN)
As mentioned above, all these algorithms can be turned into distributed algorithms too, although we do not have special names for them.
Below are the modular building blocks for the algorithms. They are designed to be general, and are reused extensively.
code: slm_lab/agent/memory
Memory is a numpy/plain type storage of data which gets reused for more efficient computations (without having to call tensor.detach() repeatedly). For storing graph tensor with the gradient, use agent.body.
Note that some particular types of algorithm/network need particular types of Memory, e.g. RecurrentNet needs any of the SeqReplay. See the class definition for more.
For on-policy algorithms (policy gradient):
- OnPolicyReplay
- OnPolicySeqReplay
- OnPolicyBatchReplay
- OnPolicySeqBatchReplay
- OnPolicyConcatReplay
- OnPolicyAtariReplay
- OnPolicyImageReplay (credit: joelouismarino)
For off-policy algorithms (value-based)
- Replay
- SeqReplay
- SILReplay (special Replay for SIL)
- SILSeqReplay (special SeqReplay for SIL)
- ConcatReplay
- AtariReplay
- ImageReplay
- PrioritizedReplay
- AtariPrioritizedReplay
code: slm_lab/agent/net
These networks are usable for all algorithms, and the lab takes care of the proper initialization with proper input/output sizing. One can swap out the network for any algorithm with just a spec change, e.g. make DQN into DRQN by substituting the net spec "type": "MLPNet" with "type": "RecurrentNet".
- MLPNet (Multi Layer Perceptron, with multi-heads, multi-tails)
- RecurrentNet (with multi-tails support)
- ConvNet (with multi-tails support)
These networks are usable for Q-learning algorithms. For more details see this paper.
- DuelingMLPNet
- DuelingConvNet
code: slm_lab/agent/algorithm/policy_util.py
The policy module takes the network output pdparam, constructs a probability distribution, and samples for it to produce actions. To use a different distribution, just specify it in the algorithm spec "action_pdtype".
- different probability distributions for sampling actions
- default policy
- Boltzmann policy
- Epsilon-greedy policy
- numerous rate decay methods
Deep Reinforcement Learning is highly empirical. The lab enables rapid and massive experimentations, hence it needs a way to quickly analyze data from many trials. The experiment and analytics framework is the scientific method of the lab.

Experiment graph summarizing the trials in hyperparameter search.

Trial graph showing average envelope of repeated sessions.

Session graph showing total rewards, exploration variable and loss for the episodes.
-
Clone the SLM-Lab repo:
git clone https://github.com/kengz/SLM-Lab.git
-
Install dependencies (or inspect
bin/setup_*first):cd SLM-Lab/ bin/setup yarn install conda activate lab
Alternatively, run the content of
bin/setup_macOSorbin/setup_ubuntuon your terminal manually. Docker image and Dockerfile with instructions are also available
Useful reference: Debugging
To update SLM Lab, pull the latest git commits and run update:
git pull
conda env update -f environment.yml; yarn install;Alternatively, use the shorthand command
yarn updateto replace the last line
Run the demo to quickly see the lab in action (and to test your installation).

It is DQN in CartPole-v0:
-
See
slm_lab/spec/demo.jsonfor example spec:"dqn_cartpole": { "agent": [{ "name": "DQN", "algorithm": { "name": "DQN", "action_pdtype": "Argmax", "action_policy": "epsilon_greedy", ... } }] }
-
Launch terminal in the repo directory, run the lab with the demo spec in
devlab mode:conda activate lab yarn start demo.json dqn_cartpole dev
To run any lab commands, conda environment must be activated first. See Installation for more.
yarn startis a shorthand forpython run_lab.py -
This demo will run a single trial using the default parameters, and render the environment. After completion, check the output for data
data/dqn_cartpole_2018_06_16_214527/(timestamp will differ). You should see some healthy graphs.Trial graph showing average envelope of repeated sessions.
Session graph showing total rewards, exploration variable and loss for the episodes.
-
Enjoy mode - when a session ends, a model file will automatically save. You can find the session
prepaththat ends in its trial and session numbers. The example above is trial 1 session 0, and you can see a pytorch model saved atdata/dqn_cartpole_2018_06_16_214527/dqn_cartpole_t1_s0_model_net.pth. Use the following command to run from the saved folder indata/:yarn start data/dqn_cartpole_2018_06_16_214527/dqn_cartpole_spec.json dqn_cartpole enjoy@dqn_cartpole_t1_s0
Enjoy mode will automatically disable learning and exploration. Graphs will still save.
To run the best model, use the best saved checkpoint
enjoy@dqn_cartpole_t1_s0_ckptbest -
The above was in
devmode. To run in proper training mode, which is faster without rendering, change thedevlab mode totrain, and the same data is produced.yarn start demo.json dqn_cartpole train
-
Next, perform a hyperparameter search using the lab mode
search. This runs experiments of multiple trials with hyperparameter search, defined at the bottom section of the demo spec.yarn start demo.json dqn_cartpole search
When it ends, refer to
{prepath}_experiment_graph.pngand{prepath}_experiment_df.csvto find the best trials.
If the demo fails, consult Debugging.
Now the lab is ready for usage.
Read on: Github | Documentation
If you use SLM-Lab in your research, please cite below:
@misc{kenggraesser2017slmlab,
author = {Wah Loon Keng, Laura Graesser},
title = {SLM-Lab},
year = {2017},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/kengz/SLM-Lab}},
}
SLM Lab is an MIT-licensed open source project. Contributions are very much welcome, no matter if it's a quick bug-fix or new feature addition. Please see CONTRIBUTING.md for more info.
If you have an idea for a new algorithm, environment support, analytics, benchmarking, or new experiment design, let us know.
If you're interested in using the lab for research, teaching or applications, please contact the authors.