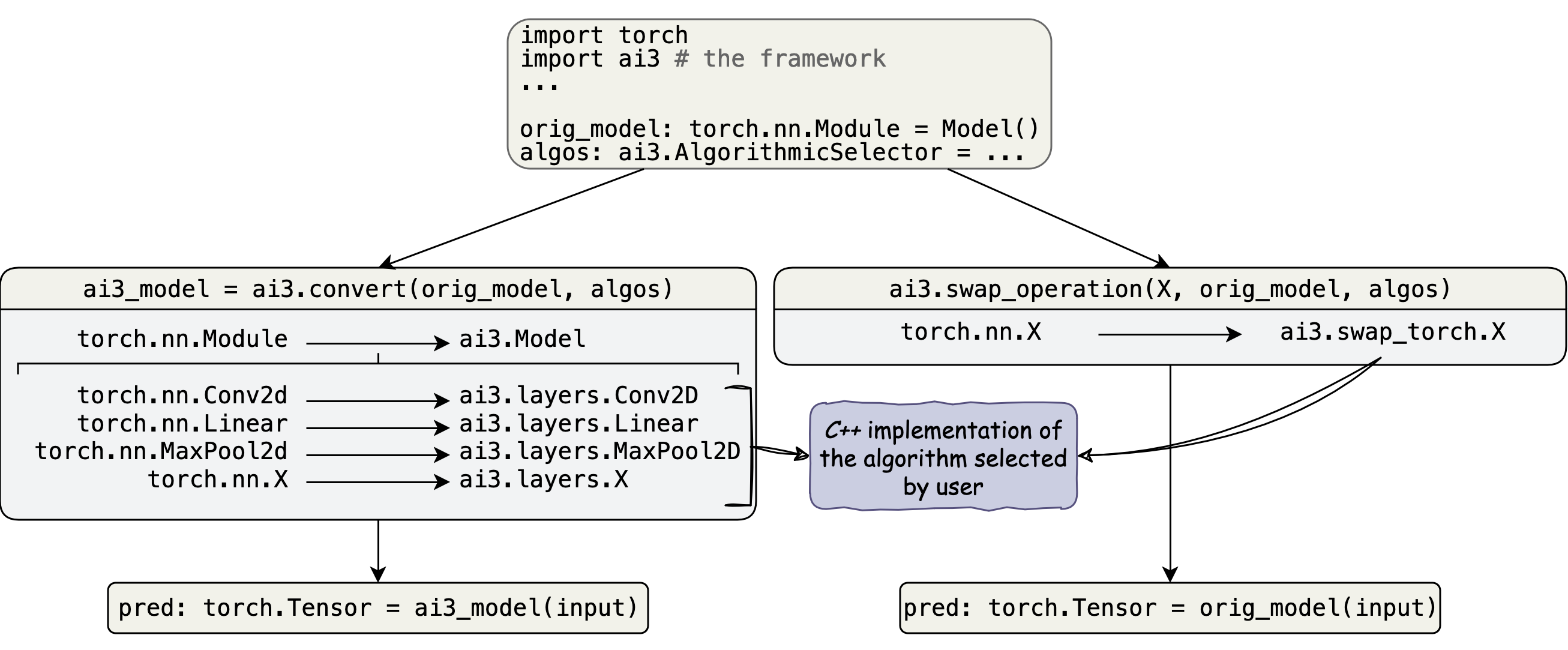
The ai3 (Algorithmic Innovations for Accelerated Implementations of Artificial Intelligence) framework provides easy-to-use fine-grain algorithmic control over an existing DNN. ai3 contains built-in high performance implementations of common deep learning operations and methods by which users can implement their own algorithms in C++. ai3 incurs no additional performance overhead, meaning that performance depends solely on the algorithms chosen by the user.
Framework Overview [1]
- From Distribution
- Wheel: pip install aithree
- Source Distribution (improves library detection): pip install aithree --no-binary :all:
- From Source
- Download the source code
pip install <path to source code>
- With Custom Implementations
- Download the source code
- Create an implementation with the operations defined in custom
- If needed, configure the build process with custom.cmake
pip install <path to source code>
ai3 currently features two methods for algorithmic swapping. convert which converts the entire DNN and swap_operation which swaps specific operations out of the existing DNN.
Swaps operations in-place out of the existing DNN for an implementation of the user specified algorithm. After swapping, the same DNN can still be trained and compiled. If no AlgorithmicSelector is given then the default algorithm decided by the framework are used.
- Example:
Swaps the first conv2d operation for an implementation of direct convolution and the second conv2d operation for an implementation of SMM convolution
>>> input_data = torch.randn(10, 3, 224, 224) >>> orig = ConvNet() >>> orig_out = orig(input_data) >>> ai3.swap_operation(nn.Conv2d, orig, ['direct', 'smm']) >>> so_out = orig(input_data) >>> torch.allclose(orig_out, so_out, atol=1e-6) True
Converts every operation in a DNN to an implementation of the user specified algorithm returning a Model completly managed by ai3.
Algorithmic selection is performed by passing a mapping from strings containing names of the operations to swap to a AlgorithmicSelector. If no AlgorithmicSelector is passed for a given operation then the default algorithm decided by the framework are used.
- Example:
Swaps the first conv2d operation for an implementation of direct convolution and the second conv2d operation for an implementation of SMM convolution
>>> def auto_selector(orig: torch.nn.Conv2d, input_shape) -> str: ... out_channels = orig.weight.shape[0] ... if (out_channels < 50 and ... input_shape[1] < 50 and ... input_shape[2] > 150 and ... input_shape[3] > 150): ... return 'direct' ... return 'smm' ... >>> input_data = torch.randn(1, 3, 224, 224) >>> vgg16 = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.DEFAULT) >>> vgg16 = vgg16.eval() >>> with torch.inference_mode(): ... torch_out = vgg16(input_data) ... model: ai3.Model = ai3.convert(vgg16, {'conv2d': auto_selector, ... 'maxpool2d': 'default'}, ... sample_input_shape=(1, 3, 224, 224)) ... sb_out = model(input_data) ... torch.allclose(torch_out, sb_out, atol=1e-4) True
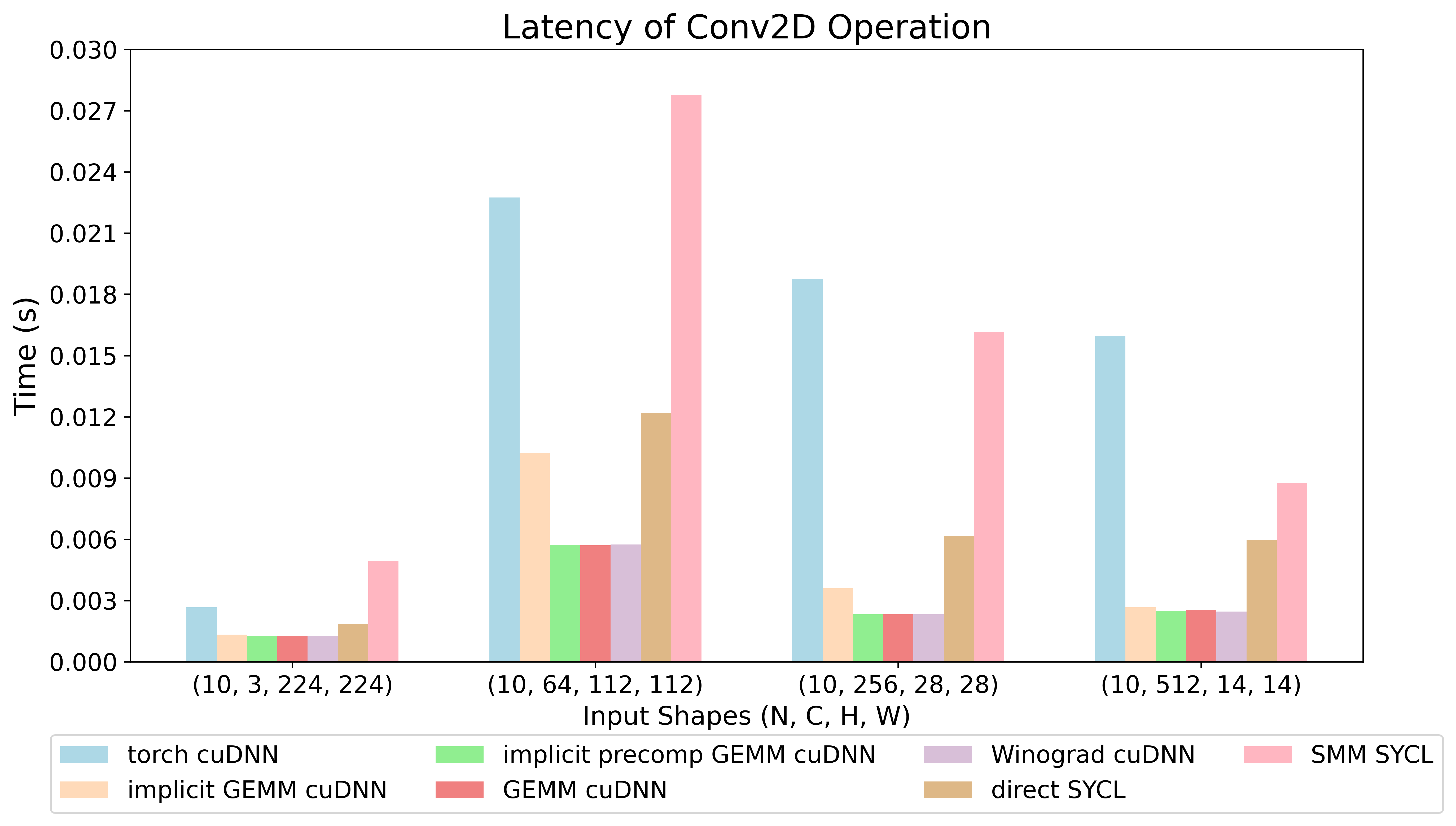
Latency of Convolution (details)
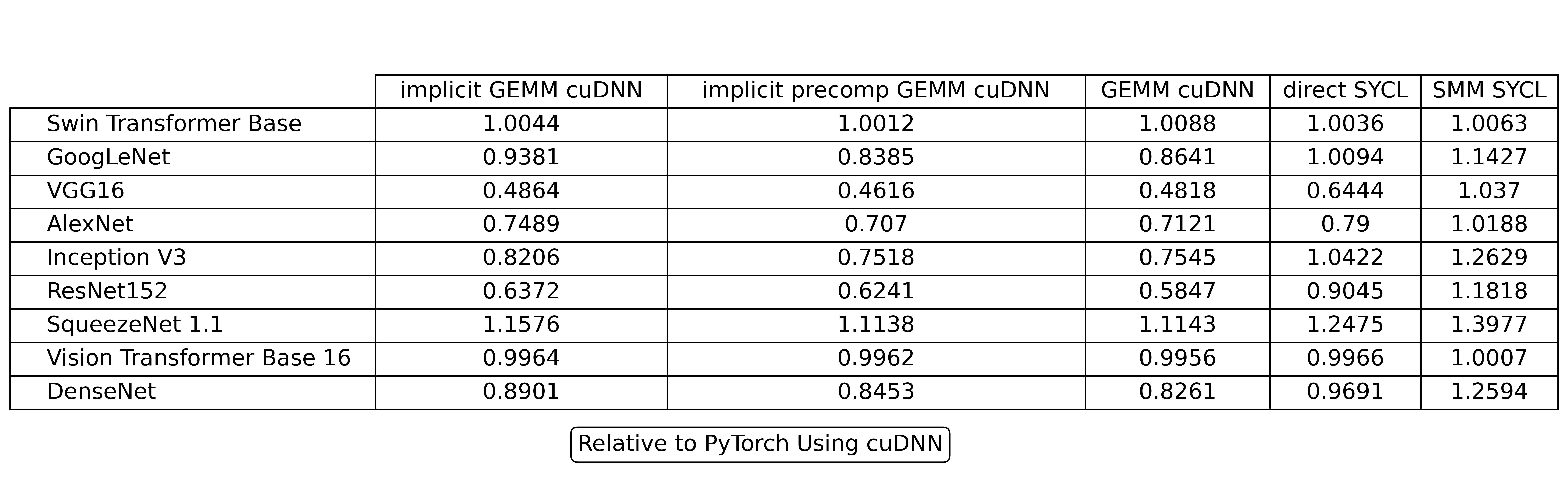
Latency of Model When Using ai3 Relative to PyTorch (details)
The cuDNN and SYCL benchmarks for both ai3 and PyTorch were gathered using an NVIDIA GeForce L40S GPU with 16 gigabytes of memory. The final latencies used are the average over 10 runs after 10 warm up runs. The implementations for the algorithms include select ones provided by cuDNN and implementations from ai3 which leverage SYCL. Benchmarks are gathered using this script.
The guess algorithm uses the algorithm returned by cudnnGetConvolutionForwardAlgorithm_v7.
| Algorithm | direct | smm | gemm | implicit precomp gemm | implicit gemm | winograd | guess | some |
|---|---|---|---|---|---|---|---|---|
| none | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| sycl | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| cudnn | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| cublas | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| mps | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| metal | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Algorithm | gemm |
|---|---|
| none | ✓ |
| sycl | ✓ |
| cudnn | ✗ |
| cublas | ✓ |
| mps | ✗ |
| metal | ✗ |
| Algorithm | direct |
|---|---|
| none | ✓ |
| sycl | ✗ |
| cudnn | ✗ |
| cublas | ✗ |
| mps | ✗ |
| metal | ✗ |
| Algorithm | direct |
|---|---|
| none | ✓ |
| sycl | ✗ |
| cudnn | ✗ |
| cublas | ✗ |
| mps | ✗ |
| metal | ✗ |
| Algorithm | direct |
|---|---|
| none | ✓ |
| sycl | ✗ |
| cudnn | ✗ |
| cublas | ✗ |
| mps | ✗ |
| metal | ✗ |
| Algorithm | direct |
|---|---|
| none | ✓ |
| sycl | ✗ |
| cudnn | ✗ |
| cublas | ✗ |
| mps | ✗ |
| metal | ✗ |
| Algorithm | direct |
|---|---|
| none | ✓ |
| sycl | ✗ |
| cudnn | ✗ |
| cublas | ✗ |
| mps | ✗ |
| metal | ✗ |
| [1] | created with draw.io |