Este repositório fornece meios, através do docker, para facilitar o uso dos dados do Cadastro Nacional da Pessoa Jurídica (CNPJ) oriundos da Receita Federal (RF). Com ele é possível criar o banco PostgreSQL com todos os pacotes necessários para o funcionamento da aplicação, como dependências e bibliotecas.
Os serviços deste módulo utilizam docker para configuração do ambiente e execução do script. Instale o docker, docker-compose e tenha certeza que você também tem o Make instalado.
Agora, será preciso configurar as variáveis necessárias para os serviços executarem:
- Crie uma cópia do arquivo .env.sample no diretório raiz desse repositório e renomeie para .env (deve também estar no diretório raiz desse repositório)
- Preencha as variáveis contidas no .env.sample também para o .env. Altere os valores conforme sua necessidade. Atente que se você está usando o banco local, o valor da variável POSTGRES_HOST deve ser postgres-receita, que é o nome do serviço que será levantado pelo docker-compose.
- O formato dos dados que foi disponibilizado pela Receita Federal exige um certo nível de trabalho antes do consumo dos dados. Por sorte, o turicas e o georgevbsantiago já baixaram, converteram e disponibilizaram esses arquivos da RF em formatos de fácil acesso. Sendo assim, baixe os dados em formato .csv disponibilizados em georgevbsantiago e descompacte o arquivo .zip.
Para realizar a alimentação do banco, realize os seguintes passos:
- Faça o build do docker com sudo make build;
- Execute o comando sudo make up para iniciar o container docker;
- Faça o create das tabelas necessárias com sudo make feed-create;
- Faça o import das tabelas necessárias com sudo make feed-import e vá tomar um cafézinho (o import costuma demorar alguns minutos);
- Opicional: Para consultas otimizadas, crie índices com o comando sudo make feed-index (hora de outro café);
- Para interromper parar a execução do container basta usar sudo make stop.
Para ver todos os comandos make disponíveis: sudo make help.
Os dados da Receita são disponibilizados trimestralmente. Os dados mais atuais foram disponibilziados em 05/09/2020. Os passos para atualizar o banco são expostos a seguir:
- Baixe os novos dados na extensão .csv disponibilizados em georgevbsantiago e descompacte o arquivo .zip.
- Caso o caminho tenha sido alterado, adicione no docker-compose.yml o local onde os arquivos com a extensão .csv foram descompactados;
- Faça um drop das tabelas existentes sudo make feed-clean;
- Crie as tabelas necessárias com sudo make feed-create;
- Faça o import das tabelas necessárias com sudo make feed-import (o import costuma demorar alguns minutos);
- Opicional: Para consultas otimizadas, crie índices com o comando sudo make feed-index (hora de outro café).
Para uma visualização geral de como os dados estão estruturados, georgevbsantiago disponibilizou o Modelo Lógico das tabelas.
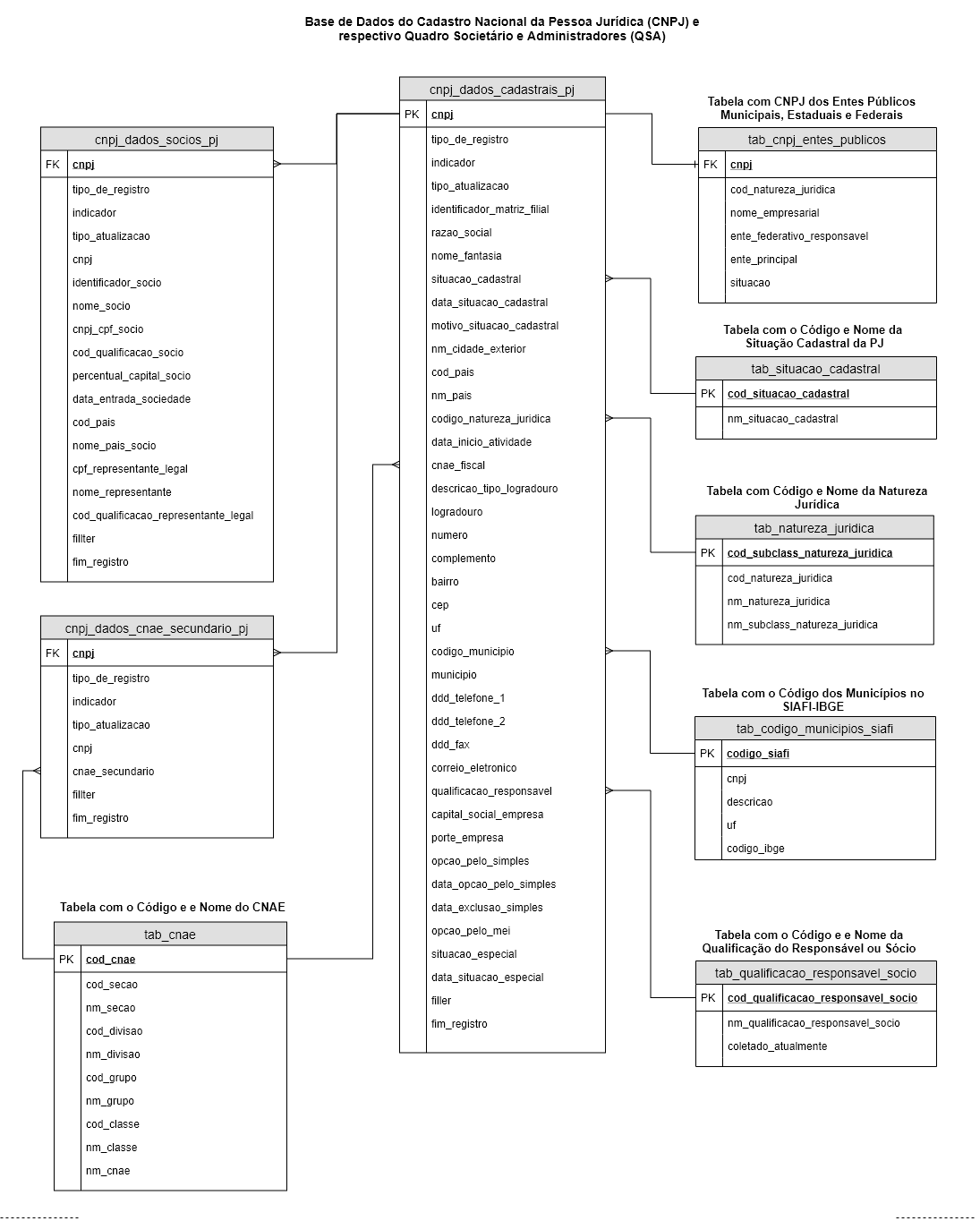{kind=link}
Exemplo em R:
library(dplyr)
# ajuste as credenciais abaixo de acordo com as
# configurações que você definiu
POSTGRES_HOST="localhost"
POSTGRES_DB="rf_fb"
POSTGRES_USER="postgres"
POSTGRES_PASSWORD="secret"
POSTGRES_PORT=7657
db_con <- NULL
db_con <- DBI::dbConnect(RPostgres::Postgres(),
dbname = POSTGRES_DB,
host = POSTGRES_HOST,
port = POSTGRES_PORT,
user = POSTGRES_USER,
password = POSTGRES_PASSWORD)
empresas_paraiba <- tibble::tibble()
template <- ('SELECT * FROM cnpj_dados_cadastrais_pj where uf=\'PB\'')
query <- template %>%
dplyr::sql()
empresas_paraiba <- dplyr::tbl(db_con, query) %>% dplyr::collect(n = Inf)
- Melhorar o processo de atualização dos dados (não utilizar o drop, por exemplo).
- Atualização automática dos dados;
GNU AFFERO GENERAL PUBLIC Version 3, 19 November 2007