



A toolset for cleaning, standardizing and combining multiple power plant databases.
This package provides ready-to-use power plant data for the European power system. Starting from openly available power plant datasets, the package cleans, standardizes and merges the input data to create a new combining dataset, which includes all the important information. The package allows to easily update the combined data as soon as new input datasets are released.
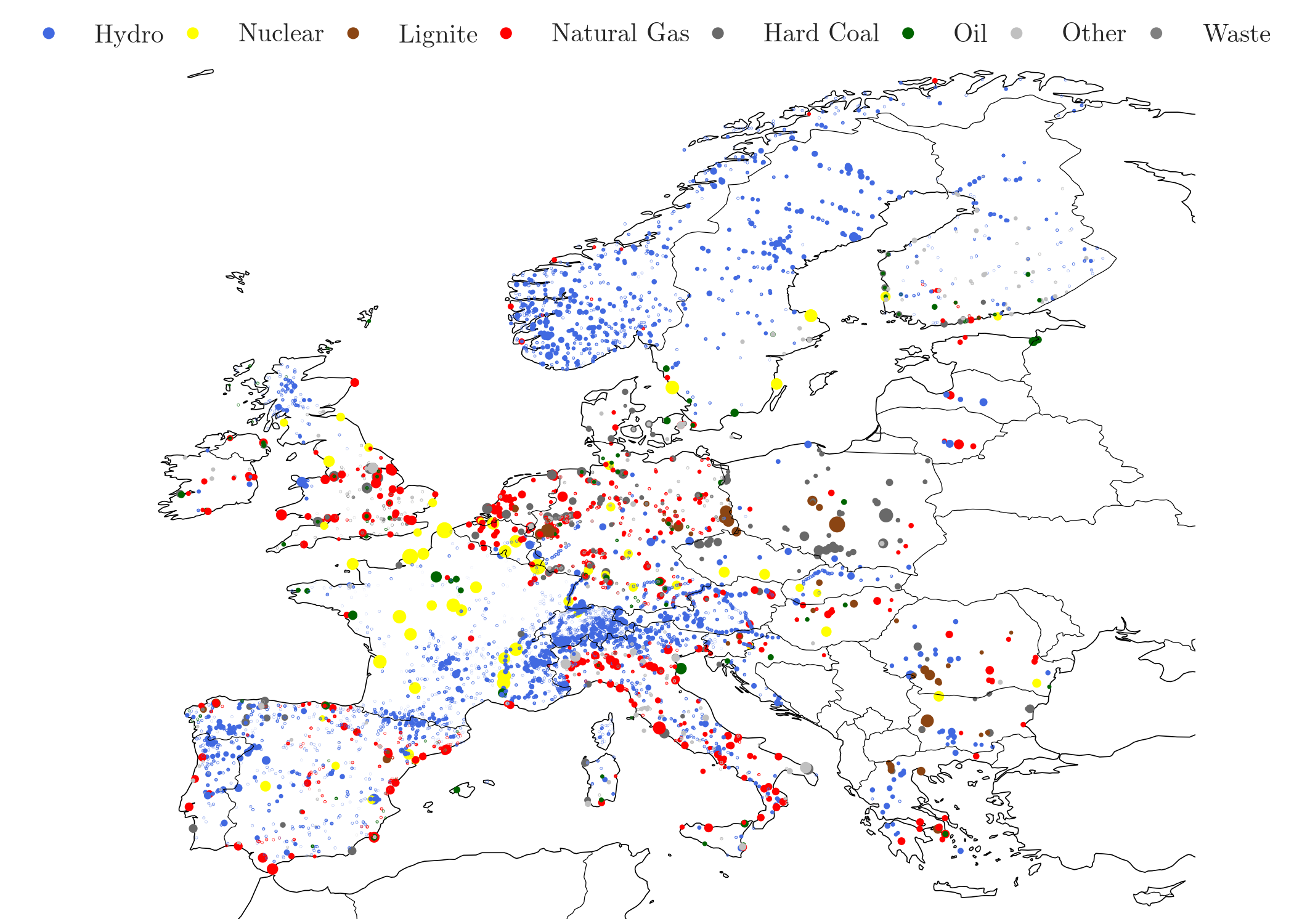
powerplantmatching was initially developed by the Renewable Energy Group at FIAS to build power plant data inputs to PyPSA-based models for carrying out simulations for the CoNDyNet project, financed by the German Federal Ministry for Education and Research (BMBF) as part of the Stromnetze Research Initiative.
- clean and standardize power plant data sets
- aggregate power plants units which belong to the same plant
- compare and combine different data sets
- create lookups and give statistical insight to power plant goodness
- provide cleaned data from different sources
- choose between gros/net capacity
- provide an already merged data set of six different data-sources
- scale the power plant capacities in order to match country specific statistics about total power plant capacities
- visualize the data
- export your powerplant data to a PyPSA or TIMES model
Using pip
pip install powerplantmatchingor conda (as long as the package is not yet in the conda-forge channel)
pip install powerplantmatching entsoe-py --no-deps
conda install pandas networkx pycountry xlrd seaborn pyyaml requests matplotlib geopy beautifulsoup4 cartopy
In order to directly load the already build data into a pandas dataframe just call
import powerplantmatching as pm
pm.powerplants(from_url=True)which will parse and store the actual dataset of powerplants of this repository. Setting from_url=False (default) will load all the necessary data files and combine them. Note that this might take some minutes.
The resulting dataset compared with the capacity statistics provided by the ENTSOE SO&AF:

The dataset combines the data of all the data sources listed in Data-Sources and provides the following information:
- Power plant name - claim of each database
- Fueltype - {Bioenergy, Geothermal, Hard Coal, Hydro, Lignite, Nuclear, Natural Gas, Oil, Solar, Wind, Other}
- Technology - {CCGT, OCGT, Steam Turbine, Combustion Engine, Run-Of-River, Pumped Storage, Reservoir}
- Set - {Power Plant (PP), Combined Heat and Power (CHP), Storages (Stores)}
- Capacity - [MW]
- Duration - Maximum state of charge capacity in terms of hours at full output capacity
- Dam Information - Dam volume [Mm^3] and Dam Height [m]
- Geo-position - Latitude, Longitude
- Country - EU-27 + CH + NO (+ UK) minus Cyprus and Malta
- YearCommissioned - Commmisioning year of the powerplant
- RetroFit - Year of last retrofit
- projectID - Immutable identifier of the power plant
All data files of the package will be stored in the folder given by pm.core.package_config['data_dir']
You have the option to easily manipulate the resulting data modifying the global configuration. Just save the config.yaml file as ~/.powerplantmatching_config.yaml manually or for linux users
wget -O ~/.powerplantmatching_config.yaml https://raw.githubusercontent.com/FRESNA/powerplantmatching/master/powerplantmatching/package_data/config.yamland change the .powerplantmaching_config.yaml file according to your wishes. Thereby you can
-
determine the global set of countries and fueltypes
-
determine which data sources to combine and which data sources should completely be contained in the final dataset
-
individually filter data sources via pandas.DataFrame.query statements set as an argument of data source name. See the default config.yaml file as an example
Optionally you can:
-
add your ENTSOE security token to the .powerplantmaching_config.yaml file. To enable updating the ENTSOE data by yourself. The token can be obtained by following section 2 of the RESTful API documentation of the ENTSOE-E Transparency platform.
-
add your Google API key to the config.yaml file to enable geoparsing. The key can be obtained by following the instructions.
- OPSD - Open Power System Data publish their data under a free license
- GEO - Global Energy Observatory, the data is not directly available on the website, but can be obtained from an sqlite scraper
- GPD - Global Power Plant Database provide their data under a free license
- CARMA - Carbon Monitoring for Action
- ENTSOe - European Network of Transmission System Operators for Electricity, annually provides statistics about aggregated power plant capacities. Their data can be used as a validation reference. We further use their annual energy generation report from 2010 as an input for the hydro power plant classification. The power plant dataset on the ENTSO-E transparency website is downloaded using the ENTSO-E Transparency API.
- JRC - Joint Research Centre Hydro-power plants database
- IRENA - International Renewable Energy Agency open available statistics on power plant capacities.
- BNETZA - Bundesnetzagentur open available data source for Germany's power plants
- UBA (Umwelt Bundesamt Datenbank "Kraftwerke in Deutschland)
- IWPDCY (International Water Power & Dam Country Yearbook)
- WEPP (Platts, World Elecrtric Power Plants Database)
The merged dataset is available in two versions: The bigger dataset, obtained by
pm.powerplants(reduced=False)links the entries of the matched power plants and lists all the related properties given by the different data-sources. The smaller, reduced dataset, given by
pm.powerplants()claims only the value of the most reliable data source being matched in the individual power plant data entry. The considered reliability scores are:
| Dataset | Reliabilty score |
|---|---|
| JRC | 6 |
| ESE | 6 |
| UBA | 5 |
| OPSD | 5 |
| OPSD_EU | 5 |
| OPSD_DE | 5 |
| WEPP | 4 |
| ENTSOE | 4 |
| IWPDCY | 3 |
| GPD | 3 |
| GEO | 3 |
| BNETZA | 3 |
| CARMA | 1 |
Let's say you have a new dataset "FOO.csv" which you want to combine with the other data bases. Follow these steps to properly integrate it. Please, before starting, make sure that you've installed powerplantmatching from your downloaded local repository (link).
-
Look where powerplantmatching stores all data files
import powerplantmatching as pm pm.core.package_config['data_dir']
-
Store FOO.csv in this directory under the subfolder
data/in. So on Linux machines the total path under which you store your data file would be:/home/<user>/.local/share/powerplantmatching/data/in/FOO.csv -
Look where powerplantmatching looks for a custom configuration file
pm.core.package_config['custom_config']
If this file does not yet exist on your machine, download the standard configuration and store it under the given path as
.powerplantmatching_config.yaml. -
Open the yaml file and add a new entry under the section
#data config. The new entry should look like thisFOO: reliability_score: 4 fn: FOO.csv
The
reliability_scoreindicates the reliability of your data, choose a number between 1 (low quality data) and 7 (high quality data). If the data is openly available, you can add anurlargument linking directly to the .csv file, which will enable automatic downloading.Add the name of the new entry to the
matching_sourcesin your yaml file like shown below#matching config matching_sources: ... - OPSD - FOO
-
Add a function
FOO()to the data.py in the powerplantmatching source code. You find the file in your local repository underpowerplantmatching/data.py. The function should be structured like this:def FOO(raw=False, config=None): """ Importer for the FOO database. Parameters ---------- raw : Boolean, default False Whether to return the original dataset config : dict, default None Add custom specific configuration, e.g. powerplantmatching.config.get_config(target_countries='Italy'), defaults to powerplantmatching.config.get_config() """ config = get_config() if config is None else config df = parse_if_not_stored('FOO', config=config) if raw: return foo df = (df .rename(columns){'Latitude': 'lat', 'Longitude': 'lon'}) .loc[lambda df: df.Country.isin(config['target_countries'])] .pipe(set_column_name, 'FOO') ) return df
Note that the code given after
df =is just a placeholder for anything necessary to turn the raw data into the standardized format. You should ensure that the data gets the appropriate column names and that any attributes are in the correct format (all of the standard labels can be found in the yaml or bypm.get_config()['target_x']when replacing x bycolumns, countries, fueltypes, sets or technologies. -
Make sure the FOO entry is given in the configuration
pm.get_config()
and load the file
pm.data.FOO()
-
If everything works fine, you can run the whole matching process with
pm.powerplants(update_all=True)
A small presentation of the tool is given in the jupyter notebook
Whereas single databases as the CARMA, GEO or the OPSD database provide non standardized and incomplete information, the datasets can complement each other and improve their reliability. In a first step, powerplantmatching converts all powerplant dataset into a standardized format with a defined set of columns and values. The second part consists of aggregating power plant blocks together into units. Since some of the datasources provide their powerplant records on unit level, without detailed information about lower-level blocks, comparing with other sources is only possible on unit level. In the third and name-giving step the tool combines (or matches)different, standardized and aggregated input sources keeping only powerplants units which appear in more than one source. The matched data afterwards is complemented by data entries of reliable sources which have not matched.
The aggregation and matching process heavily relies on DUKE, a java application specialized for deduplicating and linking data. It provides many built-in comparators such as numerical, string or geoposition comparators. The engine does a detailed comparison for each single argument (power plant name, fuel-type etc.) using adjusted comparators and weights. From the individual scores for each column it computes a compound score for the likeliness that the two powerplant records refer to the same powerplant. If the score exceeds a given threshold, the two records of the power plant are linked and merged into one data set.
Let's make that a bit more concrete by giving a quick example. Consider the following two data sets
| Name | Fueltype | Classification | Country | Capacity | lat | lon | File | |
|---|---|---|---|---|---|---|---|---|
| 0 | Aarberg | Hydro | nan | Switzerland | 14.609 | 47.0444 | 7.27578 | nan |
| 1 | Abbey mills pumping | Oil | nan | United Kingdom | 6.4 | 51.687 | -0.0042057 | nan |
| 2 | Abertay | Other | nan | United Kingdom | 8 | 57.1785 | -2.18679 | nan |
| 3 | Aberthaw | Coal | nan | United Kingdom | 1552.5 | 51.3875 | -3.40675 | nan |
| 4 | Ablass | Wind | nan | Germany | 18 | 51.2333 | 12.95 | nan |
| 5 | Abono | Coal | nan | Spain | 921.7 | 43.5588 | -5.72287 | nan |
and
| Name | Fueltype | Classification | Country | Capacity | lat | lon | File | |
|---|---|---|---|---|---|---|---|---|
| 0 | Aarberg | Hydro | nan | Switzerland | 15.5 | 47.0378 | 7.272 | nan |
| 1 | Aberthaw | Coal | Thermal | United Kingdom | 1500 | 51.3873 | -3.4049 | nan |
| 2 | Abono | Coal | Thermal | Spain | 921.7 | 43.5528 | -5.7231 | nan |
| 3 | Abwinden asten | Hydro | nan | Austria | 168 | 48.248 | 14.4305 | nan |
| 4 | Aceca | Oil | CHP | Spain | 629 | 39.941 | -3.8569 | nan |
| 5 | Aceca fenosa | Natural Gas | CCGT | Spain | 400 | 39.9427 | -3.8548 | nan |
where Dataset 2 has the higher reliability score. Apparently entries 0, 3 and 5 of Dataset 1 relate to the same power plants as the entries 0,1 and 2 of Dataset 2. The toolset detects those similarities and combines them into the following set, but prioritising the values of Dataset 2:
| Name | Country | Fueltype | Classification | Capacity | lat | lon | File | |
|---|---|---|---|---|---|---|---|---|
| 0 | Aarberg | Switzerland | Hydro | nan | 15.5 | 47.0378 | 7.272 | nan |
| 1 | Aberthaw | United Kingdom | Coal | Thermal | 1500 | 51.3873 | -3.4049 | nan |
| 2 | Abono | Spain | Coal | Thermal | 921.7 | 43.5528 | -5.7231 | nan |
If you want to cite powerplantmatching, use the following paper
- F. Gotzens, H. Heinrichs, J. Hörsch, and F. Hofmann, Performing energy modelling exercises in a transparent way - The issue of data quality in power plant databases, Energy Strategy Reviews, vol. 23, pp. 1–12, Jan. 2019.
with bibtex
@article{gotzens_performing_2019,
title = {Performing energy modelling exercises in a transparent way - {The} issue of data quality in power plant databases},
volume = {23},
issn = {2211467X},
url = {https://linkinghub.elsevier.com/retrieve/pii/S2211467X18301056},
doi = {10.1016/j.esr.2018.11.004},
language = {en},
urldate = {2018-12-03},
journal = {Energy Strategy Reviews},
author = {Gotzens, Fabian and Heinrichs, Heidi and Hörsch, Jonas and Hofmann, Fabian},
month = jan,
year = {2019},
pages = {1--12}
}
and/or the current release stored on Zenodo with a release-specific DOI:
The development of powerplantmatching was helped considerably by in-depth discussions and exchanges of ideas and code with
- Tom Brown from Karlsruhe Institute for Technology
- Chris Davis from University of Groningen and
- Johannes Friedrich, Roman Hennig and Colin McCormick of the World Resources Institute
Copyright 2018-2020 Fabian Gotzens (FZ Jülich), Jonas Hörsch (KIT), Fabian Hofmann (FIAS)
powerplantmatching is released as free software under the GPLv3, see LICENSE for further information.