This repository has been archived by the owner on Oct 25, 2024. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
145 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,145 @@ | ||
| ### ICCV 2023: SVDiff: Compact Parameter Space for Diffusion Fine-Tuning | ||
|
|
||
| ### 1. 论文信息 | ||
|  | ||
|
|
||
| ### 2. 引言 | ||
|  | ||
| 本论文致力于研究如何有效地微调大规模文本到图像的扩散模型,以实现模型的个性化和定制化。作者在研究背景部分提到,近年来基于扩散的文本到图像生成模型得到了广泛的关注和快速发展。这些模型能够根据文本提示生成具有令人印象深刻的真实性和多样性的高质量图像。同时,也有许多研究在探索如何更好地利用这些模型的能力进行图像编辑,以及如何释放这些模型在特定任务或根据个人用户偏好的更大潜力。 | ||
|
|
||
| 然而,尽管现有的方法取得了一些成果,但仍然面临着一些挑战和问题。特别是在微调这些模型时,由于模型参数空间庞大,可能会导致过拟合,使模型失去原有的泛化能力。此外,当需要模型学习多个相似或相关的个性化概念时,现有方法也显得比较困难和不够有效。 | ||
|
|
||
| 为了解决这些问题,本论文提出了一种新颖的方法。首先,作者引入了“spectral shift”这一概念,通过仅微调模型权重矩阵的奇异值来实现一个更紧凑和高效的参数空间。这种方法的灵感来自之前在 GAN 领域的一些研究,旨在减少过拟合的风险,并保持模型的泛化能力。其次,为了帮助模型更好地学习和区分多个个性化概念,论文还提出了一种名为“Cut-Mix-Unmix”的数据增强技术,通过丰富训练数据的多样性,增强模型在多个相似类别之间进行区分的能力。 | ||
|
|
||
| 综合运用这两种策略,本论文提出的方法不仅能够有效地缓解过拟合和泛化能力下降的问题,还能够提高模型在学习和适应多个相似个性化概念方面的能力。这为大规模文本到图像扩散模型的微调提供了一种新的、更加高效和实用的解决方案,为未来在此方向的进一步研究和探索提供了有价值的参考。 | ||
|
|
||
| ### 3. 方法 | ||
| 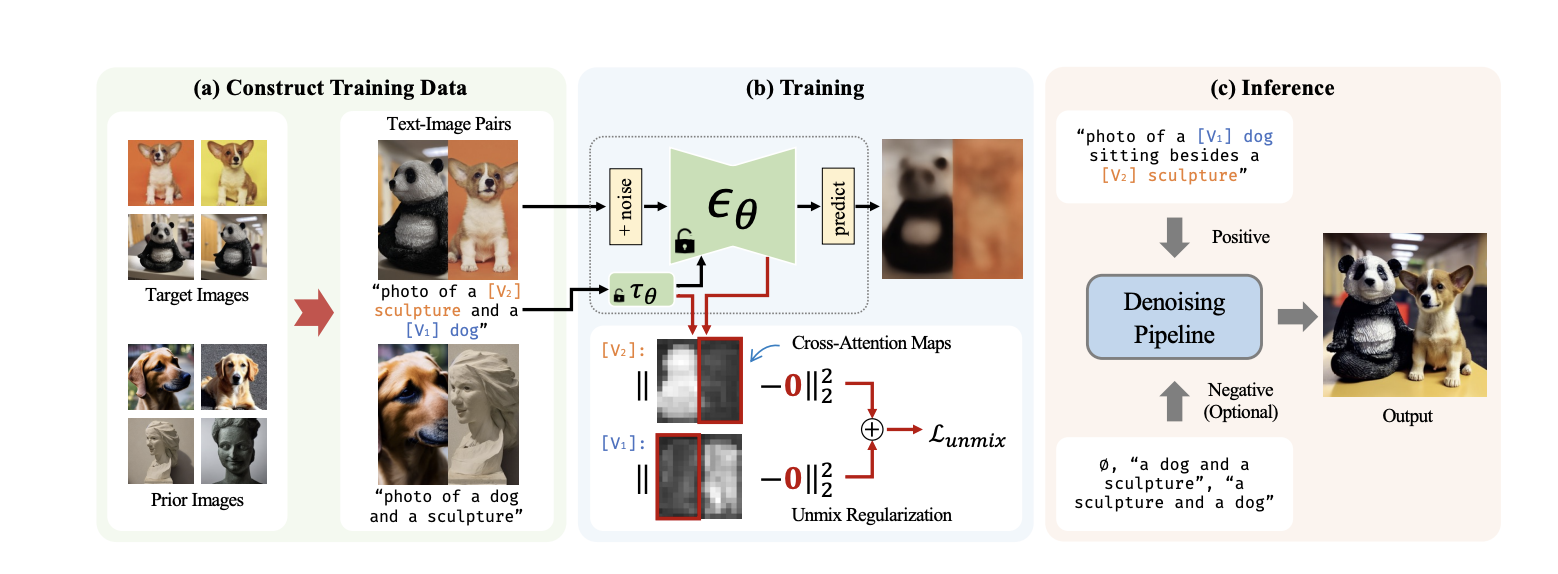 | ||
| ##### 3.1 Preliminary | ||
| 在这一部分,论文主要介绍了两个基础概念:扩散模型(Diffusion models)和 GANs 的紧凑参数空间中的少样本适应(Few-shot adaptation in compact parameter space of GANs)。 | ||
|
|
||
| 1. **扩散模型(Diffusion models)** | ||
|
|
||
| 本文实验中使用的StableDiffusion模型是潜在扩散模型(LDMs)的一个变体。LDMs 通过编码器 $\mathcal{E}$ 将输入图像 $x$ 转换成潜在代码 $z$,其中 $z = \mathcal{E}(x)$,并在潜在空间 $\mathcal{Z}$ 中执行去噪过程。LDM $ \hat{\epsilon}_\theta$ 是通过去噪目标进行训练的,具体来说,其目标函数如所示: | ||
| $$ | ||
| \mathbb{E}_{z,c,\epsilon,t} \{ \| \hat{\epsilon}_\theta(z_t | c, t | - \epsilon \|_2^2 \} | ||
| $$ | ||
| 在这里,$(z, c)$ 是数据-条件对(图像潜在特征和文本嵌入),$\epsilon \sim \mathcal{N}(0, I)$,$t \sim \text{Uniform}(1, T)$,且 $\theta$ 代表模型参数。 | ||
|
|
||
|  | ||
| 2. **GANs 的紧凑参数空间中的少样本适应** | ||
|
|
||
| 本部分介绍了一种基于奇异值分解(SVD)技术的方法(FSGAN),用于在少样本情况下适应 GANs。具体来说,FSGAN 首先将 GAN 的卷积核重新整形为2-D矩阵,并在这些重新整形的权重矩阵上执行 SVD。然后,FSGAN 利用 SVD 学习 GAN 参数空间中的紧凑更新,用于新领域的适应。此方法的目的是利用 SVD 在有限的样本中更有效地进行领域适应。 | ||
|
|
||
| 通过这两个基础概念,我们可以更好地理解作者如何在紧凑的参数空间中利用奇异值分解(SVD)技术对扩散模型进行微调和优化。 | ||
|
|
||
| ##### 3.2 Compact Parameter Space for Diffusion Fine-tuning | ||
|
|
||
| 该部分主要介绍了如何在扩散模型的参数空间中引入“spectral shifts”的概念,进行模型的微调(Fine-tuning)。 | ||
|
|
||
| 1. **Spectral Shifts** | ||
|
|
||
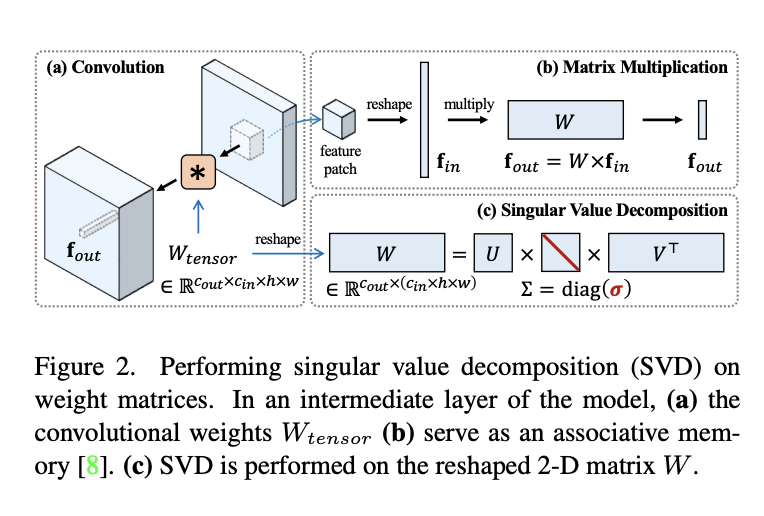
| 本方法的核心思想是将FSGAN中的“spectral shifts”概念应用于扩散模型的参数空间。首先,对预训练扩散模型的权重矩阵执行奇异值分解(SVD)。权重矩阵 $W$ 的 SVD 表示为 $W = U\Sigma V^\top\$,其中 $\Sigma$ 是对角矩阵,包含降序排列的奇异值 $\sigma = [\sigma_1, \sigma_2, ...]$。执行SVD是一次性计算,可以被缓存。这种思路是受到将卷积核视为线性关联记忆的启发。补丁级卷积可以表示为矩阵乘法,形如 $f_{out} = W_{f_{in}}$,其中 $f_{in}$ 是平坦化的补丁特征, $f_{out}$ 是对应于给定补丁的输出预激活特征。 | ||
|
|
||
| 在微调过程中,不是调整完整的权重矩阵,而是仅通过优化“spectral shift”,$\delta$,来更新权重矩阵。$\delta$ 被定义为更新的权重矩阵和原始权重矩阵的奇异值之间的差异。更新的权重矩阵可以通过以下方式重新组合: | ||
|
|
||
| $$ | ||
| W_{\delta} = U \Sigma_{\delta} V^\top \text{ where } \Sigma_{\delta} = \text{diag}(\text{ReLU}(\sigma + \delta)) | ||
| $$ | ||
|
|
||
| 2. **Training Loss** | ||
|
|
||
|
|
||
| 微调使用与训练扩散模型相同的损失函数进行,附加了一个加权的先验保留损失(weighted prior-preservation loss): | ||
|
|
||
| $$ | ||
| \mathcal{L}(\delta) = \mathbb{E}_{z^*,c^*,\epsilon,t}{\|\hat{\epsilon}_{\theta_\delta}(z_t^* | c^*) - \epsilon\|^2_2} + \lambda \mathcal{L}_{pr}(\delta) | ||
| $$ | ||
|
|
||
|
|
||
| ##### 3.3 Conditional Diffusion for C2-GAN | ||
|
|
||
| 本部分介绍了如何将条件扩散模型与GAN结合,形成一个新的生成模型(C2-GAN)。具体来说,作者首先根据样本从目标分布生成条件样本。然后,生成的条件样本被用作先验信息,驱动扩散过程生成样本。 | ||
|
|
||
| 1. **生成条件样本** | ||
|
|
||
|
|
||
| C2-GAN的条件模型是由一个扩散编码器 $\mathcal{E}$ 和一个GAN解码器 $D$ 组合而成的。扩散编码器 $\mathcal{E}$ 是预训练的,并且对目标数据进行微调。解码器 $D$ 是一个标准的GAN生成器。 | ||
|
|
||
| 2. **驱动扩散过程** | ||
|
|
||
| 利用条件样本 $(z, c)$ 和噪声 $\epsilon$ 驱动扩散过程。扩散过程的目标是最小化以下损失函数: | ||
| $$ | ||
| \mathcal{L}_{cd} = \mathbb{E}_{z,c,\epsilon,t}{\|\hat{\epsilon}_{\theta}(z_t | c) - \epsilon\|_2^2} | ||
| $$ | ||
| 其中,$z_t$ 是由条件样本和噪声驱动的扩散过程中的中间潜在代码。 | ||
|
|
||
|
|
||
|
|
||
| ### 4. 实验 | ||
| 实验对 SVDiff在各种任务如单主题/多主题生成、单图像编辑和消融等方面进行了评估。在单主题生成部分,SVDiff与 DreamBooth(对完整模型权重进行微调)产生了相似的结果,尽管其参数空间较小。然而,与 Custom Diffusion 相比,SVDiff有更好的性能,后者在训练图像方面表现出欠拟合的倾向。 | ||
|  | ||
| 在多主题生成部分,实验展示了提出的 "Cut-Mix-Unmix" 数据增强技术的优势。用户研究的结果显示,使用 SVD 的 "Cut-Mix-Unmix" 方法生成的图像在视觉质量上得到了更多的青睐,被选为更好图像的频率为60.9%。 | ||
|  | ||
| 在单图像编辑部分,实验结果表明,SVDiff通过使用频谱移位参数空间有效地缓解了语言漂移问题。与完整模型权重微调相比,即便在不使用 DDIM 反演时,SVDiff也能实现所需的编辑,如删除图片中的对象、调整对象的姿态和缩放视图等。综合而言,SVDiff在各种任务中都表现出了良好的性能和强大的编辑能力。 | ||
|  | ||
| 该研究在分析和消融研究部分探讨了参数子集、权重组合、插值和风格混合的影响。 | ||
|
|
||
| 1. **参数子集:** | ||
| - 研究探讨了在UNet中微调光谱偏移的子参数集。他们发现优化交叉注意力(CA)层通常能更好地保持主题的身份识别,相较于仅优化关键和值投影。 | ||
| - 独立优化UNet的上、下或中间块不足以保持身份,但上块显示了更好的身份保持。 | ||
|
|
||
| 2. **权重组合:** | ||
| - 他们分析了权重组合的效果,研究发现合并模型在两种情况下都能保持个体主题的独特特点,但在相似的概念上可能会混合他们的风格。 | ||
| - 对于不同的概念,模型仍然能产生每个主题的单独表示。 | ||
|
|
||
| 3. **风格转移和混合:** | ||
| - 研究展示了使用所提出的方法进行风格转移的能力。他们还显示了通过求和两组光谱偏移,他们的风格可以被混合。 | ||
| - 通过进一步的实验,他们发现我们的光谱偏移参数空间允许我们实现类似于StyleGAN的解耦风格混合效果。 | ||
|
|
||
| 4. **插值:** | ||
| - 研究展示了光谱偏移和全权重插值的结果。他们发现,光谱偏移和全权重插值都能够在两个原始类别之间生成中间概念。 | ||
|
|
||
| 5. **与LoRA的比较:** | ||
| - 在与LoRA的比较中,他们发现,相比于LoRA,SVDiff在保持真实性和保真度之间提供了更好的平衡,并且结果在delta检查点大小上显著较小。 | ||
|
|
||
|
|
||
| ### 5. 讨论 | ||
| 该论文提出的方法主要基于光谱偏移(Spectral Offsetting),用于微调扩散模型。以下是对该方法的一些讨论: | ||
|
|
||
| **优点:** | ||
|
|
||
| - **紧凑性:** 提出的参数空间相对紧凑,与完整的模型相比,它只需要微调一小部分参数。这有助于保持模型的泛化能力,同时减少过度拟合的风险。 | ||
|
|
||
| - **灵活性:** 由于只微调部分参数,该方法在微调过程中提供了一定的灵活性。例如,可以选择微调不同的参数子集,以达到不同的微调效果。 | ||
|
|
||
| - **效果:** 该方法在多个实验中显示出良好的效果。它不仅能保持生成图像的真实性和保真度,还能在多主题生成中实现与其他基线相当或更好的性能。 | ||
|
|
||
| **缺点:** | ||
|
|
||
| - **限制性:** 该方法也有其限制性。例如,在增加更多主题时,Cut-Mix-Unmix的性能会下降。此外,在单图像编辑中,背景保持的不太理想。 | ||
|
|
||
| - **泛化能力:** 尽管参数空间相对紧凑,但如何选择要微调的参数子集以及如何控制微调的程度,都可能会影响模型的泛化能力。 | ||
|
|
||
| **可扩展性:** | ||
|
|
||
| - **与其他方法的融合:** 该方法可能可以与其他微调方法(如LoRA)相结合,以取得更好的效果。 | ||
|
|
||
| - **应用范围:** 该方法主要用于图像生成任务,但未来可能会探讨其在其他类型的生成任务(如文本生成)中的应用。 | ||
|
|
||
| **创新性:** | ||
|
|
||
| - **方法原创性:** 通过引入光谱偏移的概念,该方法提出了一种新颖的微调策略,这在之前的研究中较少见。 | ||
|
|
||
| **未来展望:** | ||
|
|
||
| - **进一步优化:** 对于该方法的限制和缺点,未来的研究可以考虑进一步优化,例如探索更有效的参数子集选择策略。 | ||
|
|
||
| - **更多应用场景:** 未来还可以探索该方法在更多应用场景中的效果,例如在更复杂、多样化的生成任务中的表现。 | ||
|
|
||
| 总结,该论文提出的光谱偏移方法在参数微调方面展示了一种新颖和有效的策略。虽然还存在一些限制和需要进一步探索的地方,但它为扩散模型的微调提供了有前途的解决方案。 | ||
|
|
||
| ### 6. 结论 | ||
| 本论文通过引入一种基于光谱偏移的新颖方法,对扩散模型进行了有效的微调。作者通过一系列实验验证了该方法的有效性,实验结果表明该方法能在保持生成图像质量的同时,实现对模型的微调。与其他微调方法相比,如LoRA,本方法在多主题生成中展现了相当甚至更优秀的性能,但在单图像编辑方面的表现仍有提升空间。 | ||
|
|
||
| 此方法的引入提供了一种新的思路和可能性,对于探索扩散模型和其他生成模型的微调具有一定的参考价值。然而,该方法的泛化能力、选择微调参数的策略以及在更多应用场景中的表现仍需进一步研究和验证。总体而言,本论文对扩散模型微调方法的研究是成功和有意义的,为未来的研究提供了有益的启示。 |