This repository has been archived by the owner on Oct 25, 2024. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Create 【RWKV】如何新增一个自定义的Tokenizer和模型到HuggingFace.md
- Loading branch information
Showing
1 changed file
with
261 additions
and
0 deletions.
There are no files selected for viewing
261 changes: 261 additions & 0 deletions
261
docs/academic/算法科普/Transformer/【RWKV】如何新增一个自定义的Tokenizer和模型到HuggingFace.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,261 @@ | ||
|
|
||
|  | ||
|
|
||
| # 0x0. 前言 | ||
| RWKV社区在Huggingface上放了rwkv-4-world和rwkv-5-world相关的一系列模型,见:https://huggingface.co/BlinkDL/rwkv-4-world & https://huggingface.co/BlinkDL/rwkv-5-world ,然而这些模型的格式是以PyTorch的格式进行保存的即*.pt文件,并没有将其转换为标准的Huggingface模型。后来了解到这里还有一个问题是RWKV的世界模型系列的tokenizer是自定义的,在Huggingface里面并没有与之对应的Tokenizer。没有标准的Huggingface模型就没办法使用TGI进行部署,也不利于模型的传播以及和其它模型一起做评测等等。 | ||
|
|
||
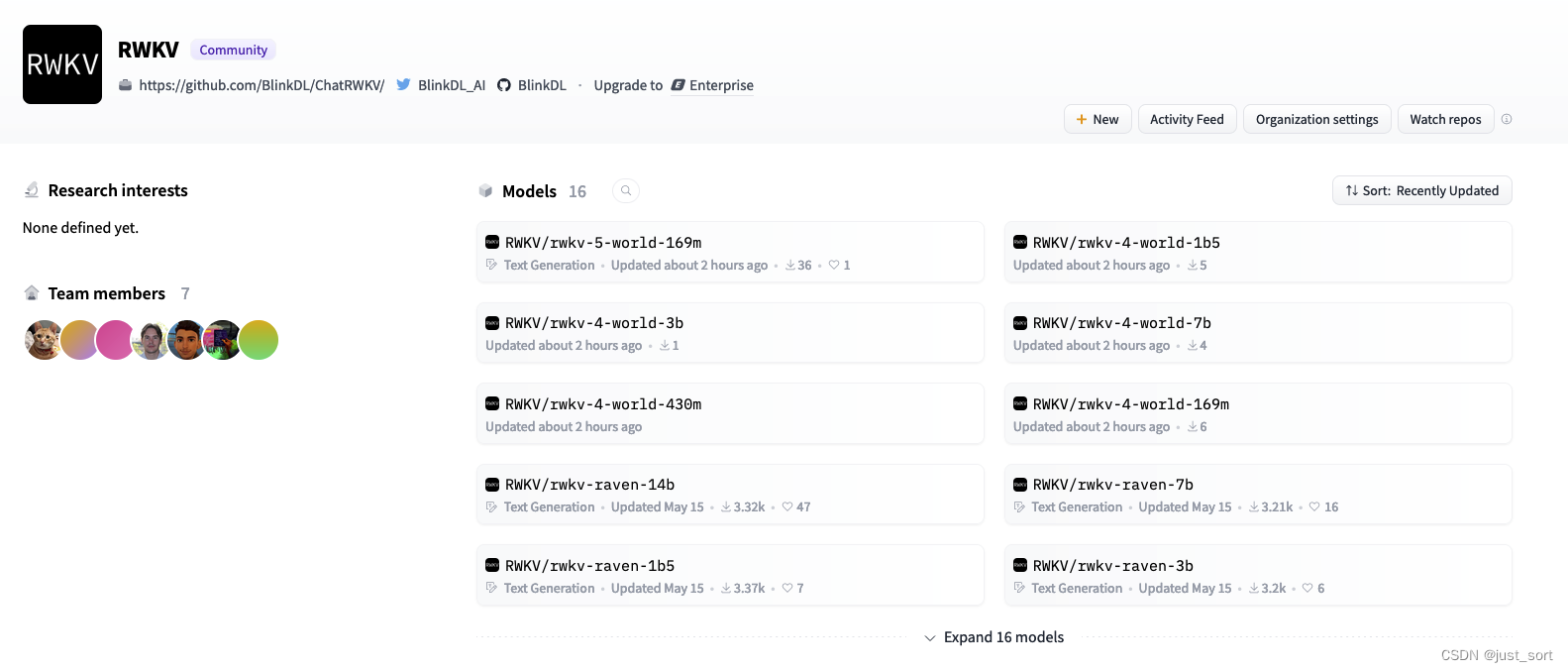
| 让RWKV world系列模型登陆Huggingface社区是必要的,这篇文章介绍了笔者为了达成这个目标所做的一些努力,最后成功让rwkv-4-world和rwkv-5-world系列模型登陆Huggingface。大家可以在 https://huggingface.co/RWKV 这个空间找到目前所有登陆的RWKV模型: | ||
|
|
||
|  | ||
|
|
||
| 本系列的工作都整理开源在 https://github.com/BBuf/RWKV-World-HF-Tokenizer ,包含将 RWKV world tokenizer 实现为 Huggingface 版本,实现 RWKV 5.0 的模型,提供模型转换脚本,Lambda数据集ppl正确性检查工具 等等。 | ||
|
|
||
| # 0x1. 效果 | ||
| 以 RWKV/rwkv-4-world-3b 为例,下面分别展示一下CPU后端和CUDA后端的执行代码和效果。 | ||
|
|
||
| ## CPU | ||
|
|
||
| ```python | ||
| from transformers import AutoModelForCausalLM, AutoTokenizer | ||
|
|
||
| model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-world-3b") | ||
| tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-world-3b", trust_remote_code=True) | ||
|
|
||
| text = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese." | ||
| prompt = f'Question: {text.strip()}\n\nAnswer:' | ||
|
|
||
| inputs = tokenizer(prompt, return_tensors="pt") | ||
| output = model.generate(inputs["input_ids"], max_new_tokens=256) | ||
| print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True)) | ||
| ``` | ||
|
|
||
| 输出: | ||
|
|
||
| ```powershell | ||
| Question: In a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese. | ||
| Answer: The dragons in the valley spoke perfect Chinese, according to the scientist who discovered them. | ||
| ``` | ||
|
|
||
| ## GPU | ||
|
|
||
| ```python | ||
| import torch | ||
| from transformers import AutoModelForCausalLM, AutoTokenizer | ||
|
|
||
| model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-world-3b", torch_dtype=torch.float16).to(0) | ||
| tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-world-3b", trust_remote_code=True) | ||
|
|
||
| text = "你叫什么名字?" | ||
| prompt = f'Question: {text.strip()}\n\nAnswer:' | ||
|
|
||
| inputs = tokenizer(prompt, return_tensors="pt").to(0) | ||
| output = model.generate(inputs["input_ids"], max_new_tokens=40) | ||
| print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True)) | ||
| ``` | ||
|
|
||
| 输出: | ||
|
|
||
| ```powershell | ||
| Question: 你叫什么名字? | ||
| Answer: 我是一个人工智能语言模型,没有名字。 | ||
| ``` | ||
|
|
||
| 我们可以在本地通过上述代码分别运行CPU/GPU上的wkv-4-world-3b模型,当然这需要安装transformers和torch库。 | ||
|
|
||
| # 0x2. 教程 | ||
|
|
||
| 下面展示一下在 https://github.com/BBuf/RWKV-World-HF-Tokenizer 做的自定义实现的RWKV world tokenizer的测试,RWKV world模型转换,检查lambda数据集正确性等的教程。 | ||
|
|
||
| ### 使用此仓库(https://github.com/BBuf/RWKV-World-HF-Tokenizer)的Huggingface项目 | ||
|
|
||
| > 上传转换后的模型到Huggingface上时,如果bin文件太大需要使用这个指令 `transformers-cli lfs-enable-largefiles` 解除大小限制. | ||
| - [RWKV/rwkv-5-world-169m](https://huggingface.co/RWKV/rwkv-5-world-169m) | ||
| - [RWKV/rwkv-4-world-169m](https://huggingface.co/RWKV/rwkv-4-world-169m) | ||
| - [RWKV/rwkv-4-world-430m](https://huggingface.co/RWKV/rwkv-4-world-430m) | ||
| - [RWKV/rwkv-4-world-1b5](https://huggingface.co/RWKV/rwkv-4-world-1b5) | ||
| - [RWKV/rwkv-4-world-3b](https://huggingface.co/RWKV/rwkv-4-world-3b) | ||
| - [RWKV/rwkv-4-world-7b](https://huggingface.co/RWKV/rwkv-4-world-7b) | ||
|
|
||
| ### RWKV World模型的HuggingFace版本的Tokenizer | ||
|
|
||
| 下面的参考程序比较了原始tokenizer和HuggingFace版本的tokenizer对不同句子的编码和解码结果。 | ||
|
|
||
| ```python | ||
| from transformers import AutoModelForCausalLM, AutoTokenizer | ||
| from rwkv_tokenizer import TRIE_TOKENIZER | ||
| token_path = "/Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer" | ||
|
|
||
| origin_tokenizer = TRIE_TOKENIZER('/Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_vocab_v20230424.txt') | ||
|
|
||
| from transformers import AutoTokenizer | ||
| hf_tokenizer = AutoTokenizer.from_pretrained(token_path, trust_remote_code=True) | ||
|
|
||
| # 测试编码器 | ||
| assert hf_tokenizer("Hello")['input_ids'] == origin_tokenizer.encode('Hello') | ||
| assert hf_tokenizer("S:2")['input_ids'] == origin_tokenizer.encode('S:2') | ||
| assert hf_tokenizer("Made in China")['input_ids'] == origin_tokenizer.encode('Made in China') | ||
| assert hf_tokenizer("今天天气不错")['input_ids'] == origin_tokenizer.encode('今天天气不错') | ||
| assert hf_tokenizer("男:听说你们公司要派你去南方工作?")['input_ids'] == origin_tokenizer.encode('男:听说你们公司要派你去南方工作?') | ||
|
|
||
| # 测试解码器 | ||
| assert hf_tokenizer.decode(hf_tokenizer("Hello")['input_ids']) == 'Hello' | ||
| assert hf_tokenizer.decode(hf_tokenizer("S:2")['input_ids']) == 'S:2' | ||
| assert hf_tokenizer.decode(hf_tokenizer("Made in China")['input_ids']) == 'Made in China' | ||
| assert hf_tokenizer.decode(hf_tokenizer("今天天气不错")['input_ids']) == '今天天气不错' | ||
| assert hf_tokenizer.decode(hf_tokenizer("男:听说你们公司要派你去南方工作?")['input_ids']) == '男:听说你们公司要派你去南方工作?' | ||
| ``` | ||
|
|
||
| ### Huggingface RWKV World模型转换 | ||
|
|
||
| 使用脚本`scripts/convert_rwkv_world_model_to_hf.sh`,将huggingface的`BlinkDL/rwkv-4-world`项目中的PyTorch格式模型转换为Huggingface格式。这里,我们以0.1B为例。 | ||
|
|
||
| ```shell | ||
| #!/bin/bash | ||
| set -x | ||
|
|
||
| cd scripts | ||
| python convert_rwkv_checkpoint_to_hf.py --repo_id BlinkDL/rwkv-4-world \ | ||
| --checkpoint_file RWKV-4-World-0.1B-v1-20230520-ctx4096.pth \ | ||
| --output_dir ../rwkv4-world4-0.1b-model/ \ | ||
| --tokenizer_file /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer \ | ||
| --size 169M \ | ||
| --is_world_tokenizer True | ||
| cp /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/rwkv_vocab_v20230424.json ../rwkv4-world4-0.1b-model/ | ||
| cp /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/tokenization_rwkv_world.py ../rwkv4-world4-0.1b-model/ | ||
| cp /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/tokenizer_config.json ../rwkv4-world4-0.1b-model/ | ||
| ``` | ||
|
|
||
| 使用脚本 `scripts/convert_rwkv5_world_model_to_hf.sh`,将来自 huggingface `BlinkDL/rwkv-5-world` 项目的 PyTorch 格式模型转换为 Huggingface 格式。在这里,我们以 0.1B 为例。 | ||
|
|
||
| ```shell | ||
| #!/bin/bash | ||
| set -x | ||
|
|
||
| cd scripts | ||
| python convert_rwkv5_checkpoint_to_hf.py --repo_id BlinkDL/rwkv-5-world \ | ||
| --checkpoint_file RWKV-5-World-0.1B-v1-20230803-ctx4096.pth \ | ||
| --output_dir ../rwkv5-world-169m-model/ \ | ||
| --tokenizer_file /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer \ | ||
| --size 169M \ | ||
| --is_world_tokenizer True | ||
|
|
||
| cp /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_v5.0_model/configuration_rwkv5.py ../rwkv5-world-169m-model/ | ||
| cp /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_v5.0_model/modeling_rwkv5.py ../rwkv5-world-169m-model/ | ||
| cp /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/rwkv_vocab_v20230424.json ../rwkv5-world-169m-model/ | ||
| cp /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/tokenization_rwkv_world.py ../rwkv5-world-169m-model/ | ||
| cp /Users/bbuf/工作目录/RWKV/RWKV-World-HF-Tokenizer/rwkv_world_tokenizer/tokenizer_config.json ../rwkv5-world-169m-model/ | ||
| ``` | ||
|
|
||
| 另外,您需要在生成文件夹中的 `config.json` 文件开头添加以下几行: | ||
|
|
||
| ```json | ||
| "architectures": [ | ||
| "RwkvForCausalLM" | ||
| ], | ||
| "auto_map": { | ||
| "AutoConfig": "configuration_rwkv5.Rwkv5Config", | ||
| "AutoModelForCausalLM": "modeling_rwkv5.RwkvForCausalLM" | ||
| }, | ||
| ``` | ||
|
|
||
| ### 运行Huggingface的RWKV World模型 | ||
|
|
||
| `run_hf_world_model_xxx.py`演示了如何使用Huggingface的`AutoModelForCausalLM`加载转换后的模型,以及如何使用通过`AutoTokenizer`加载的自定义`RWKV World模型的HuggingFace版本的Tokenizer`进行模型推断。请看0x1节,这里就不赘述了。 | ||
| ### 检查Lambda | ||
|
|
||
| 如果你想运行这两个脚本,首先需要下载一下 https://github.com/BlinkDL/ChatRWKV ,然后cd到 | ||
| rwkv_pip_package 目录做`pip install -e .` ,然后再回到ChatRWKV的v2目录下面,运行这里提供的`lambda_pt.py`和`lambda_hf.py`。 | ||
|
|
||
| `check_lambda`文件夹下的`lambda_pt.py`和`lambda_hf.py`文件分别使用RWKV4 World 169M的原始PyTorch模型和HuggingFace模型对lambda数据集进行评估。从日志中可以看出,他们得到的评估结果基本上是一样的。 | ||
|
|
||
| #### lambda_pt.py lambda评估日志 | ||
|
|
||
| ```shell | ||
| # Check LAMBADA... | ||
| # 100 ppl 42.41 acc 34.0 | ||
| # 200 ppl 29.33 acc 37.0 | ||
| # 300 ppl 25.95 acc 39.0 | ||
| # 400 ppl 27.29 acc 36.75 | ||
| # 500 ppl 28.3 acc 35.4 | ||
| # 600 ppl 27.04 acc 35.83 | ||
| ... | ||
| # 5000 ppl 26.19 acc 35.84 | ||
| # 5100 ppl 26.17 acc 35.88 | ||
| # 5153 ppl 26.16 acc 35.88 | ||
| ``` | ||
|
|
||
| #### lambda_hf.py lambda评估日志 | ||
|
|
||
| ```shell | ||
| # Check LAMBADA... | ||
| # 100 ppl 42.4 acc 34.0 | ||
| # 200 ppl 29.3 acc 37.0 | ||
| # 300 ppl 25.94 acc 39.0 | ||
| # 400 ppl 27.27 acc 36.75 | ||
| # 500 ppl 28.28 acc 35.4 | ||
| # 600 ppl 27.02 acc 35.83 | ||
| ... | ||
| # 5000 ppl 26.17 acc 35.82 | ||
| # 5100 ppl 26.15 acc 35.86 | ||
| # 5153 ppl 26.14 acc 35.86 | ||
| ``` | ||
|
|
||
| 从lambda的输出结果可以验证原始基于ChatRWKV系统运行的模型和转换后的Huggingface模型是否精度是等价的。 | ||
| # 0x3. 实现 | ||
|
|
||
| ## Tokenizer的实现 | ||
|
|
||
| Tokenizer的实现分为两步。 | ||
|
|
||
| 因为目前社区的RWKV world模型tokenizer文件是一个txt文件:https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_vocab_v20230424.txt 。我们需要将其转换为Huggingface的AutoTokenizer可以读取的json文件。这一步是通过 https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/scripts/convert_vocab_json.py 这个脚本实现的,我们对比一下执行前后的效果。 | ||
|
|
||
| 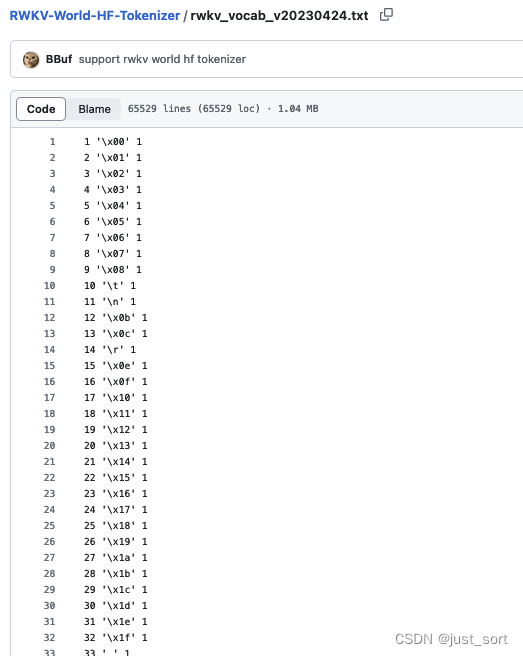 | ||
|
|
||
| 转换为json文件后: | ||
|
|
||
|  | ||
|
|
||
| 这里存在一个转义的关系,让gpt4解释一下\u0000和\x00的关系: | ||
|
|
||
|  | ||
|
|
||
| 有了这个json文件之后,我们就可以写一个继承PreTrainedTokenizer类的RWKVWorldTokenizer了,由于RWKV world tokenzier的原始实现是基于Trie树(https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_tokenizer.py#L5),所以我们实现 RWKVWorldTokenizer 的时候也要使用 Trie 树这个数据结构。具体的代码实现在 https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_world_tokenizer/tokenization_rwkv_world.py 这个文件。 | ||
|
|
||
| 需要注意 https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_world_tokenizer/tokenization_rwkv_world.py#L211 这一行,当解码的token id是0时表示句子的结束(eos),这个时候就停止解码。 | ||
|
|
||
| ## RWKV World 5.0模型实现 | ||
| 实现了rwkv world tokenizer之后就可以完成所有rwkv4 world模型转换到HuggingFace模型格式了,因为rwkv4 world模型的模型结构和目前transformers里面支持的rwkv模型的代码完全一样,只是tokenzier有区别而已。 | ||
|
|
||
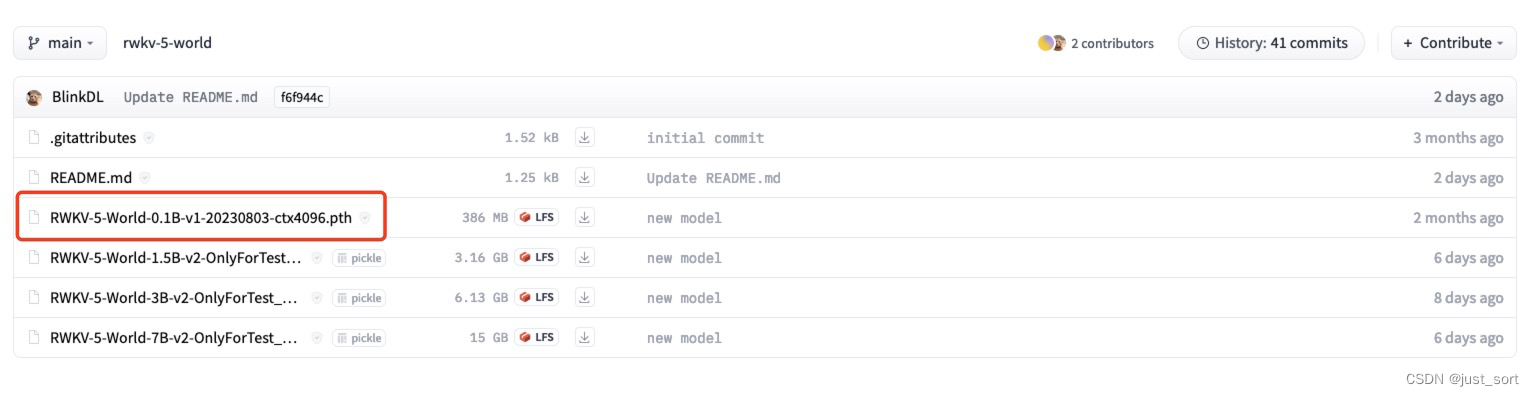
| 但是如果想把 https://huggingface.co/BlinkDL/rwkv-5-world 这里的模型也转换成 HuggingFace模型格式,那么我们就需要重新实现一下模型了。下面红色部分的这个模型就是rwkv5.0版本的模型,剩下的都是5.2版本的模型。 | ||
|
|
||
|  | ||
|
|
||
| 我对照着ChatRWKV里面rwkv world 5.0的模型实现完成了HuggingFace版本的rwkv world 5.0版本模型代码实现,具体见:https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/rwkv_world_v5.0_model/modeling_rwkv5.py ,是在transformers官方提供的实现上进一步修改得来。 | ||
|
|
||
| 实现了这个模型之后就可以完成rwkv world 5.0的模型转换为HuggingFace结果了,教程请看上一节或者github仓库。成品:https://huggingface.co/RWKV/rwkv-5-world-169m | ||
| # 0x4. 踩坑 | ||
| 在实现tokenizer的时候,由于RWKV world tokenzier的eos是0,我们没办法常规的去插入eos token,所以直接在Tokenzier的解码位置特判0。 | ||
|
|
||
| RWKVWorldTokenizer的初始化函数在 `super().__init__` 的时机应该是在构造`self.encoder`之后,即: | ||
|
|
||
| 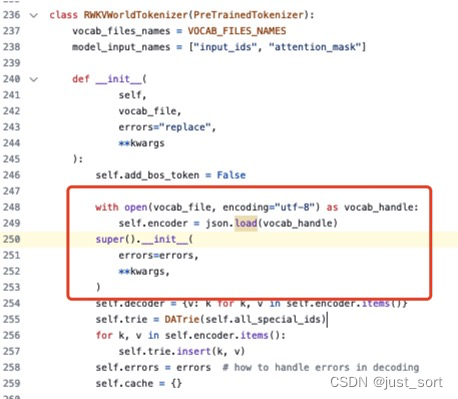 | ||
|
|
||
| 否则会在当前最新的transformers==4.34版本中造成下面的错误: | ||
|
|
||
|  | ||
|
|
||
| 在模型实现部分踩了一个坑,在embedding的时候第一次需要需要对embedding权重做一个pre layernorm的操作: | ||
|
|
||
|  | ||
|
|
||
| 这个操作只能在第一次输入的时候做一般就是prefill,我没注意到这一点导致后面decoding的时候也错误做了这个操作导致解码的时候乱码,后面排查了不少时间才定位到这个问题。 | ||
|
|
||
| 另外,在做check lambda的时候,如果不开启torch.no_grad上下文管理器禁用梯度计算,显存会一直涨直到oom:https://github.com/BBuf/RWKV-World-HF-Tokenizer/blob/main/check_lambda/lambda_hf.py#L48 。 | ||
|
|
||
| # 0x5. 总结 | ||
| 这件事情大概花了国庆的一半时间加一个完整的周六才搞定,所以这篇文章记录一下也可以帮助有相关需求的小伙伴们少踩点坑。 | ||
|
|
||
|
|