This repository has been archived by the owner on Oct 25, 2024. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
67 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,67 @@ | ||
| # Sora生成具有惊人几何一致性的视频,评估指标来了!(附项目链接) | ||
|
|
||
| 论文标题:Sora Generates Videos with Stunning Geometrical Consistency | ||
|
|
||
| 论文连接:https://arxiv.org/abs/2402.17403 | ||
|
|
||
| 项目主页: https://sora-geometrical-consistency.github.io/ | ||
|
|
||
| 最近推出的Sora模型展现出了在视频生成方面的卓越能力,引发了关于其模拟真实世界现象能力的热烈讨论。尽管越来越受欢迎,但缺乏既定的指标来定量评估其与真实世界物理规律的一致性。在本文中,我们引入了一个新的基准测试,根据生成视频与真实世界物理原理的符合程度来评估其质量。我们采用了一种将生成视频转化为3D模型的方法,这利用了3D重建的准确度在很大程度上取决于视频质量的前提。从3D重建的角度来看,我们使用构建的3D模型满足几何约束的程度作为衡量生成视频符合真实世界物理规律程度的代理指标。 | ||
|
|
||
| 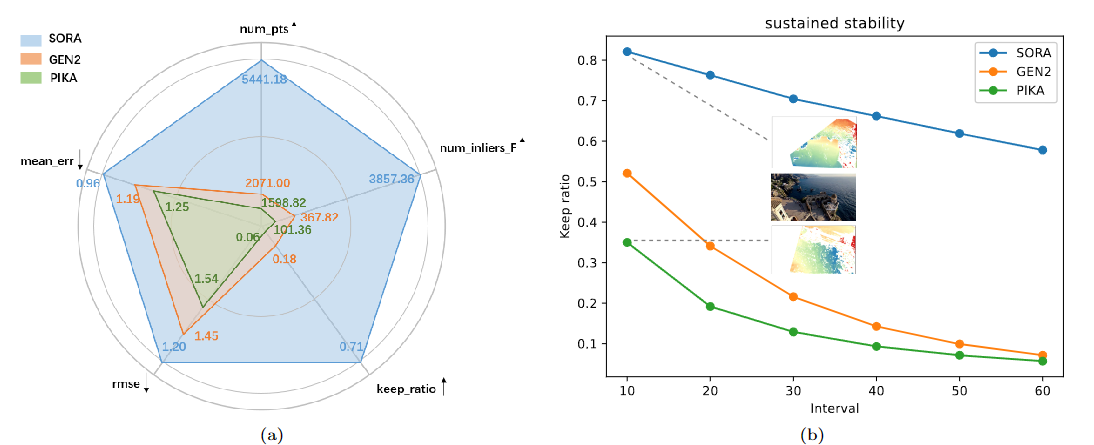 | ||
|
|
||
| 图1 Sora、Pika和Gen2的比较。(a)显示了我们在第2节中定义的五个指标的定量评估。更多细节,读者可参考表1。(b)展示了不同方法在我们设计的持续稳定性指标下的性能。在这两个图中,我们可以看到Sora在几何一致性方面的显著优势。 | ||
|
|
||
| ## 1 引言 | ||
|
|
||
| 在图像生成领域取得了实质性的成就之后,正在兴起的文本到视频合成(T2V)领域被认为是生成模型应用的新前沿。视频生成需要在图像合成的基础上发展,因为它需要在视频帧之间保持一致的空间和时间关系。这个复杂的过程进一步加剧了对简短且通常是抽象的视频说明的理解挑战,以及高质量视频-文本数据集的有限可用性。 | ||
|
|
||
| 在扩散模型发展的推动下,视频生成进入了一个新时代,出现了Video Diffusion Models和Imagen Video等独特框架。这些开创性的研究为通过创新的条件采样方法,以支持视频在时空上的一致扩展铺平了道路。这一领域的一个值得关注的进展是MagicVideo的推出,它通过在一个紧凑的潜在空间中合成视频片段,显著改进了生成过程——这种方法在Video LDM中得到进一步完善。随后又有MaskDiffusion的出现,通过改进的交叉注意力机制,加强了与文本对齐的视频内容生成。尽管取得了这些进展,但传统的以帧保真度、运动协调性和文本-视频一致性为中心的指标却无法捕捉生成视频的几何质量。 | ||
|
|
||
| 最近推出的Sora模型被公认为视频生成领域的杰作,因其在生成具有显著真实感和在时空向量上保持一致、合理内容的视频方面展现出的非凡能力而备受赞誉。Sora模型的性能表明,T2V技术正在取得重大进展,这进一步肯定了在生成模型领域继续创新的重要性。展示的视频剪辑与该领域之前的领导者如SVD、Pika Labs和Runway的Gen-2相比,画质有了显著改善。Sora的一个突出方面是其物理合理性:尽管偶尔出现失误,但许多生成的剪辑展现出了遵循物理定律和保持明显几何属性的特点,这是之前的模型所无法捕捉的。 | ||
|
|
||
| 此外,显而易见的是,评估视频生成的传统指标,如Fréchet inception距离(FID)、Fréchet视频距离(FVD)、Inception分数(IS)和美学分数等,都没有包含物理准确性,尤其是几何方面的维度。为此,我们考虑利用3D对象质量评估中的指标来评估视频生成质量。传统的3D重建主要由两个部分组成:基于运动的结构(SFM)和多视图立体(MVS)。SFM由COLMAP和OpenMVG等工具代表,它们利用稀疏匹配和捆束调整来估计相机姿态和稀疏点云。MVS则由OpenMVS等库代表,它们以SFM的结果为输入,执行密集匹配、网格重建和纹理映射以生成3D模型。近年来,基于深度学习的3D重建方法如神经辐射场(Nerf)和3D高斯溅射已经出现。这些方法擅长处理不同材质、透明对象和水下环境,从而获得更高的渲染质量,并能精细重建复杂场景。 | ||
|
|
||
| 我们的论文探讨了利用从Sora生成的视频中获得的3D对象重建质量作为度量,定量评估其在几何方面与物理原理的一致性。具体而言,我们收集了Sora在互联网上公开的10个代表性视频剪辑。然后,我们使用Pika Labs和Gen-2基于相同的文本提示生成视频。令人惊讶的是,如图1所示,我们观察到Sora生成的视频足以进行3D重建,并且在所选择的所有指标上都显著优于强基线模型。我们希望这个简单的基准测试对于视频生成模型能够很好地理解物理世界是有帮助的。 | ||
|
|
||
| ## 2 方法 | ||
|
|
||
| **3D重建过程。**我们避免修改原始的COLMAP和高斯溅射算法以适应生成视频的特点。我们利用基于运动的结构(SfM)来计算相机姿态,然后使用高斯溅射进行3D重建。本基准测试中使用的详细指标如下所述。 | ||
|
|
||
|  | ||
|
|
||
| 表1 在6个Sora视频上的定量比较。符号'↑/↓'表示得分越高/越低越好。最佳得分以**粗体**标记。 | ||
|
|
||
| **指标设计。**基于运动的结构(SFM)和3D构建的基础原理是多视图几何,这意味着模型的质量依赖于两个主要因素:1)虚拟视频观察相机的视角必须充分满足像小孔相机这样的物理特性;2)随着视频的进展和视角的变化,场景的刚性部分必须以保持物理和几何稳定性的方式变化。 | ||
|
|
||
| 此外,多视图几何的基本单元是两视图几何。生成视频的物理保真度越高,其两帧就越符合理想的两视图几何约束,如对极几何。具体来说,虚拟视角序列视频中相机成像的理想程度越高,场景在图像中保留的物理特征就越好。两帧越接近理想的两视图几何,局部特征在灰度和形状方面的失真和扭曲就越小,匹配算法就能获得越多的匹配点。因此,在基于基础矩阵(对极约束)的RANSAC 消除错误对应后,保留的高质量匹配点数量就越多。 | ||
|
|
||
| 因此,我们从AI生成的视频中以固定间隔提取两帧,得到两视图图像对。对于每一对,我们使用匹配算法寻找对应点,并采用基于基础矩阵(对极约束)的RANSAC消除错误对应。 | ||
|
|
||
| 消除后,我们计算正确的初始匹配点数量平均值、保留点数量平均值和平均保留率。因此,我们有以下指标:num pts表示两视图中初始匹配点的总数,num inliers F表示滤波后保留的匹配点总数。keep ratio由num inliers F与num pts的比值获得。另外,对于每对图像,我们计算N个RANSAC保留匹配点对于F矩阵的双向几何重投影误差d(x, x')。x和x'是RANSAC保留的匹配点,d是一个点到其对应对极线的距离。最后,我们对所有数据进行整体统计分析,计算RMSE(均方根误差)和MAE(平均绝对误差)。 | ||
|
|
||
| ## 3 实验 | ||
|
|
||
| 在我们的实验中,选择传统算法SIFT作为稀疏匹配模块,而不是更强大的基于深度学习的匹配算法。这一决定旨在防止匹配性能过于强大,从而可能掩盖图像质量的潜在缺陷,如光照、纹理和材质属性的变化。同样,密集匹配模块采用传统的SGBM算法实现,理由同上。RANSAC算法使用OpenCV中的原始版本。我们直接从官方网站获取Sora视频。为保证公平比较,我们利用Sora视频的第一帧结合Gen2和Pika的image2video功能(使用相同的提示)生成具有相同场景的视频。 | ||
|
|
||
| 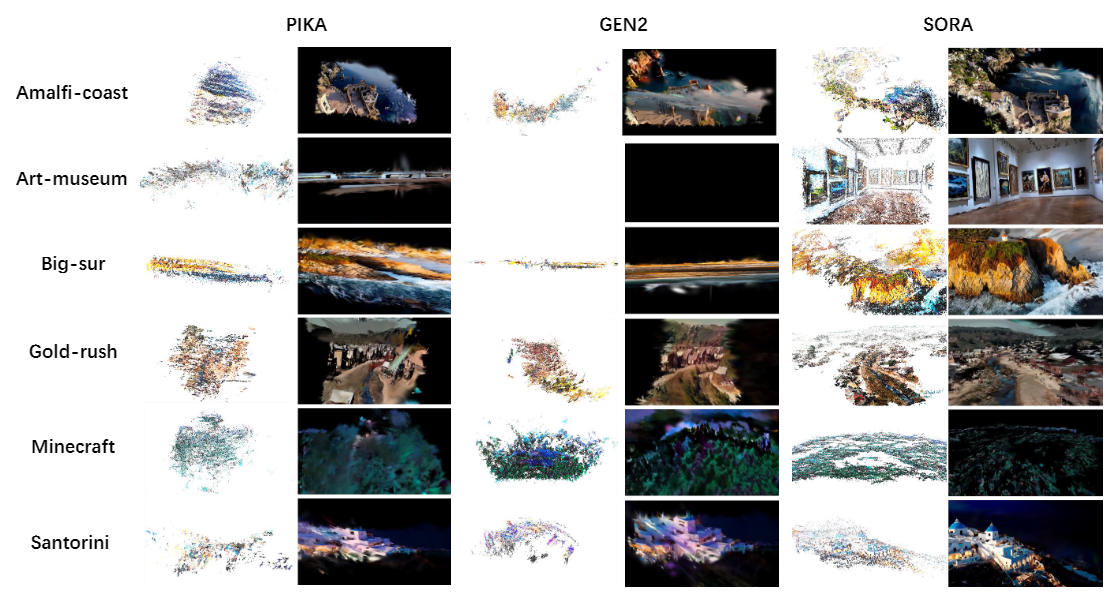 | ||
|
|
||
| 图2 点云和高斯溅射渲染的可视化。该图呈现了Pika、Gen2和Sora生成视频的3D重建结果。Pika和Gen2的结果具有有限的重建范围,几何和纹理质量较差。Sora的重建质量明显优于Pika和Gen2,这可归因于两个关键因素:1)Sora能够生成更长的视频,提供了更丰富的相机信息;2)Sora视频在帧与帧之间有更好的一致性,从而实现了更清晰、更详细的3D重建。(注:由于相机视角变化不足,Gen2的一个视频无法重建。) | ||
|
|
||
| **保真度指标。**我们计算每个视频的总帧数,采样间隔为30帧,从第一帧开始,RANSAC阈值为3。结果如表1所示。结果表明,虽然Sora的匹配误差与其他两种方法相当(但仍是最优的),但它获得的正确匹配点数量是其他两种方法的数倍。这表明其生成的图像是最真实的,具有最高的几何一致性质量。 | ||
|
|
||
| **持续稳定性指标。**我们还比较了上述保留率指标在不同帧采样间隔下的变化情况。这种评估被称为持续稳定性评估。从图1(b)的结果可以看出,随着帧间隔增加,Sora在保留正确匹配的比率方面呈现缓慢下降,而其他两种方法则呈现急剧下降。这证明了Sora在较长时间内保持物理、成像和几何特征的稳定性和一致性。 | ||
|
|
||
| **可视化。**首先,我们展示了使用SFM和高斯溅射方法进行3D重建的过程,展示了不同方法生成的点云和高斯溅射重建结果。图2展示了Pika、Gen2和Sora生成的视频的3D重建结果,覆盖了6个不同场景,包括点云和高斯溅射可视化。值得注意的是,Sora所实现的重建质量明显优于Pika和Gen2。这种增强性能可以归因于两个主要原因:1)Sora能够生成更长的视频,提供了更丰富的相机信息;2)Sora生成的视频中不同帧之间的一致性更好,有利于重建清晰细致的3D几何结构。此外,我们对不同方法生成的视频所得到的稀疏匹配结果进行了视觉分析,如图3所示。Sora方法生成的视频在滤波后展现出最多的正确匹配点。最后,我们将校正后的立体图像输入SGBM匹配算法,并直接通过可视化比较不同方法的立体匹配结果质量,如图4所示。SGBM立体匹配的可视化结果表明,只有严格遵守几何一致性的视图才能通过SGBM算法产生合理的密集匹配结果。 | ||
|
|
||
|  | ||
|
|
||
| 图3 匹配结果比较。图中绿色代表高质量匹配结果,红色代表被丢弃的匹配结果。绿色高质量匹配越多,表明两视图之间的几何一致性越高。 | ||
|
|
||
|  | ||
|
|
||
| 图4 SGBM立体匹配结果的可视化。只有严格遵守几何一致性的视图才能通过SGBM算法产生合理的密集匹配结果。显而易见,Sora生成的视频展现出最出色的几何一致性。 | ||
|
|
||
| ## 4 未来工作讨论 | ||
|
|
||
| 像Sora这样的模型的出现凸显了对视频生成任务更精确、更全面的评估工具的迫切需求。为全面评估生成视频的质量,本研究首次探索应用3D重建指标来检验几何属性。除了几何方面,我们认为纹理真实度、运动合理性以及场景物体间交互逻辑等基于物理法则的指标同样重要,并将其列为未来探索的重点。 |