This repository has been archived by the owner on Oct 25, 2024. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
122 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,122 @@ | ||
|
|
||
|
|
||
| ### ICCV 2023: TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance | ||
|
|
||
| ### 1. 论文信息 | ||
|
|
||
|  | ||
|
|
||
| ### 2. 引言 | ||
|
|
||
|  | ||
|
|
||
| CLIP是OpenAI在2021年提出的一个里程碑式的视觉语言预训练模型。CLIP的独特之处在于它从海量的图像-文本配对数据中联合学习图像和文本表示,而不需要人工标注。但是,CLIP通常依赖较大的模型容量,存在计算效率不高的限制,这成为其实际应用和部署的主要障碍。综上,CLIP是具有里程碑意义的视觉语言预训练模型,但是还存在可以改进的空间。 | ||
|
|
||
| 这篇论文研究的是如何通过知识蒸馏的方式压缩大规模的视觉语言预训练模型,如CLIP模型。这是一个非常重要的问题,因为现有的CLIP等视觉语言预训练模型参数量通常非常大,导致存储、内存和计算时间成本很高,不利于实际应用。但是直接训练小模型的性能往往比较差,所以需要通过压缩的方式获得更小、更快的模型而不影响性能。 | ||
|
|
||
| 现有的视觉语言预训练模型如CLIP通常参数量巨大,导致三大问题: | ||
|
|
||
| 1. 存储成本高。大模型需要大量存储空间保存参数。 | ||
| 2. 内存占用大。在运行时需要占用大量内存加载参数。 | ||
| 3. 计算缓慢。大模型计算复杂,导致推理速度很慢。 | ||
|
|
||
| 直接训练小模型往往无法取得竞争性能。以往的压缩方法大多集中在单模态上,而跨模态压缩研究还不够。 | ||
|
|
||
| 论文提出了一个新颖的跨模态知识蒸馏方法TinyCLIP,主要创新点有两个:亲和力模仿和权重继承。亲和力模仿探索了老师模型在图像和文本模态之间的交互,让学生模型在视觉语言亲和力空间中模仿老师模型的行为。权重继承将老师模型的预训练权重传递给学生模型,以改进蒸馏的效率。 | ||
|
|
||
| 通过系统的实验,论文证明了该方法可以高效地压缩CLIP模型,取得非常不错的性能。例如,在ImageNet上的零样本评价中,压缩后的TinyCLIP-ViT使用6300万参数就能达到61.4%的top-1准确率,相比之下原始的OpenCLIP-ViT需要1.26亿参数才能达到62.9%的准确率。这证明该方法可以获得更小、更快的视觉语言模型。 | ||
|
|
||
| 总之,该论文解决了一个非常重要而有价值的问题,提出了一种有效的压缩视觉语言预训练模型的新方法,获得了state-of-the-art的结果。这对于推动这类模型的实际应用具有重要意义。 | ||
|
|
||
| ### 3. 方法 | ||
|
|
||
|  | ||
|
|
||
| ##### 3.1 Distillation with Affinity Mimicking | ||
|
|
||
| $$ | ||
| \begin{align} | ||
| {\mathcal{L}}_{distill} &= \mathcal{L}_{I 2 T} + \mathcal{L}_{T 2 I}, \\ | ||
| &= CE(A_{I 2 T}^s, A_{I 2 T}^t) + CE(A_{T 2 I}^s, A_{T 2 I}^t). \nonumber | ||
| \end{align} | ||
| $$ | ||
| 在学生模型中,不仅考虑图像和对应文本的相似度,还考虑图像与所有文本的相似度,以及文本与所有图像的相似度。具体来说,定义了两种亲和力损失: | ||
|
|
||
| 图像到文本的亲和力损失LI2T:计算一个图像与batch中所有文本的亲和力分数矩阵AI2T,然后用交叉熵损失使学生模型预测的亲和力矩阵接近老师模型的。 | ||
| 文本到图像的亲和力损失LT2I:计算一个文本与batch中所有图像的亲和力分数矩阵AT2I,同样用交叉熵损失进行模仿。 | ||
| 这里亲和力分数矩阵的每个元素都是对应的图像和文本的embedding内积再过softmax。 | ||
|
|
||
| $$ | ||
| \begin{align} | ||
| A_{I 2 T}(i, j)&=\frac{\exp \left(I_i \cdot T_j / \tau\right)}{\sum_{k \in \mathcal{B}} \exp \left(I_{{ }_i}{ } \cdot T_k / \tau\right)}, | ||
| \\ | ||
| A_{T 2 I}(i, j)&=\frac{\exp \left(I_i \cdot T_j / \tau\right)}{\sum_{k \in \mathcal{B}} \exp \left(I_{{ }_k}{ } \cdot T{ }_j / \tau\right)}, | ||
| \label{eq:sim} | ||
| \end{align} | ||
| $$ | ||
| 总的模仿损失为LI2T和LT2I之和。这种亲和力模仿让学生模型不仅 align 对应的图像和文本,也能在整个视觉语言亲和力空间中模仿老师模型的行为,进行更好的视觉语言特征对齐,有利于知识迁移。 | ||
|
|
||
| 相比只使用图像或文本特征进行蒸馏,论文证明这种结合图像-文本亲和力的蒸馏方式更加有效。 | ||
|
|
||
|  | ||
|
|
||
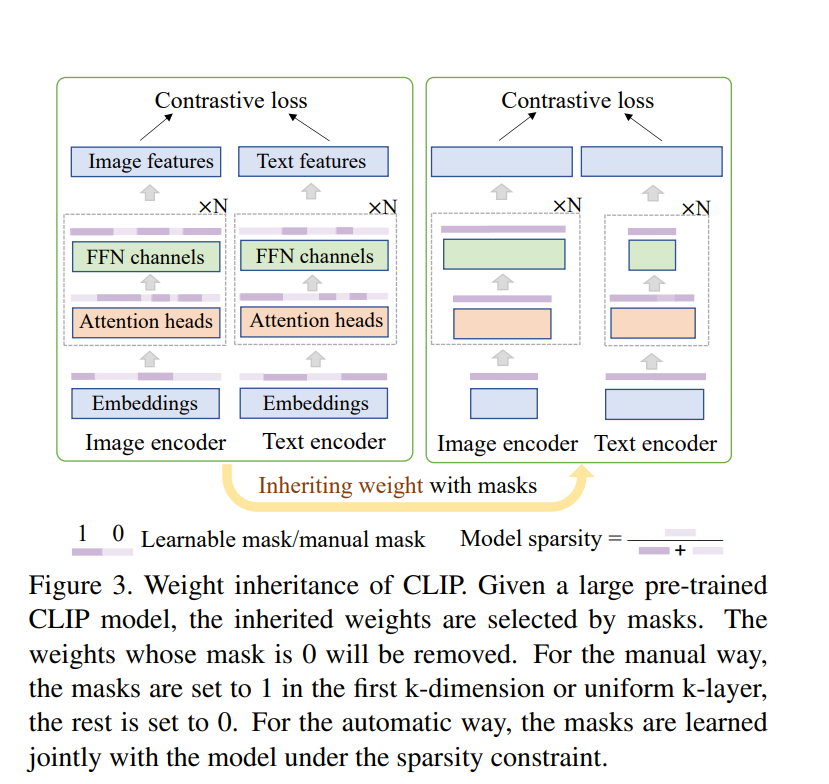
| ##### 3.2. Distillation with Weight Inheritance | ||
|
|
||
| - 在多头自注意力(MHA)中,引入头部重要性Mask $m_{head} \in {0,1}$: | ||
|
|
||
| $$ | ||
| \mathrm{MHA}(X)=\sum_{h=1}^{N_H} m_{head}^{h} \cdot \mathrm{Attn}*{W*{h}^{Q}, W_{h}^{K}, W_{h}^{V}, W_{h}^{O}}(X) | ||
| $$ | ||
|
|
||
|
|
||
|
|
||
| - 在前馈网络(FFN)中,引入中间层重要性Mask $m_{int} \in {0,1}$: | ||
|
|
||
| $$ | ||
| \mathrm{FFN}(X)=\mathrm{GeLU}(X W^{U}) \odot \mathrm{diag}(m_{int}) \cdot W^{D} | ||
| $$ | ||
|
|
||
|
|
||
|
|
||
| - 引入embedding重要性Mask $m_{embed} \in {0,1}$,所以说稀疏性约束损失 $L_{sparsity}$: | ||
|
|
||
| $$ | ||
| L_{sparsity}=\lambda \cdot (p-q)+\beta \cdot (p-q)^{2} | ||
| $$ | ||
|
|
||
|
|
||
|
|
||
| ##### 3.3 Progressive Multi-Stage Distillation | ||
|
|
||
| 当目标压缩率很高时,一次性压缩模型会带来较大的性能损失,甚至导致无法收敛。为此,提出了多阶段渐进式压缩的策略。将压缩分为多次进行,每次保留关键结构和权重,压缩幅度适中。每一阶段都包括权重继承和亲和力模仿两部分。在权重继承阶段,逐步减少大模型中的参数,直到保留目标压缩率所需的关键权重。之后进行亲和力模仿,将知识迁移到小模型中。重复这一过程,直到达到最终的目标压缩率。随着阶段的增加,学生模型与老师模型之间的结构差异逐渐减小,利于继承权重。具体实验中,采用了3阶段渐进式压缩,先从100%压缩到75%,再从75%压缩到50%,最后从50%压缩到25%,逐步获得高压缩率而不损失太多性能。 | ||
|
|
||
| 这种策略可以有效缩小老师和学生之间的差距,避免一次性高压缩带来的问题,取得更好的压缩效果。 | ||
|
|
||
| ### 4. 实验 | ||
|
|
||
|  | ||
|
|
||
| TinyCLIP实现了大规模视觉语言预训练模型的高效压缩,使参数量减少2-11倍,计算量减少1.5-5倍,同时仍能保持可竞争的性能。这对于克服这类模型的高存储、内存和计算成本具有重要意义。TinyCLIP通过新颖的亲和力模仿和权重继承技术,实现了更好更顺畅的知识迁移。亲和力模仿从视觉语言亲和力的角度进行模仿可以更好地将跨模态知识传递给学生模型。权重继承为学生模型提供了良好初始化,加速了蒸馏过程。TinyCLIP采用渐进式多阶段压缩策略,避免了一次性压缩带来的问题,可以平滑地逐步达到较高的压缩率。同时,自动权重选择也使得方法更为广泛适用。TinyCLIP压缩后的小模型表现出了很强的泛化能力,不仅ImageNet分类效果强,在多种下游任务和多个数据集上也展现出了优秀的表现。所以说,根据此表实验数据,我们可以发现,TinyCLIP在视觉语言模型压缩方面取得了state-of-the-art的结果,使大小适宜的强大视觉语言模型成为可能,对该领域具有重要贡献和推动作用。 | ||
|
|
||
|  | ||
|
|
||
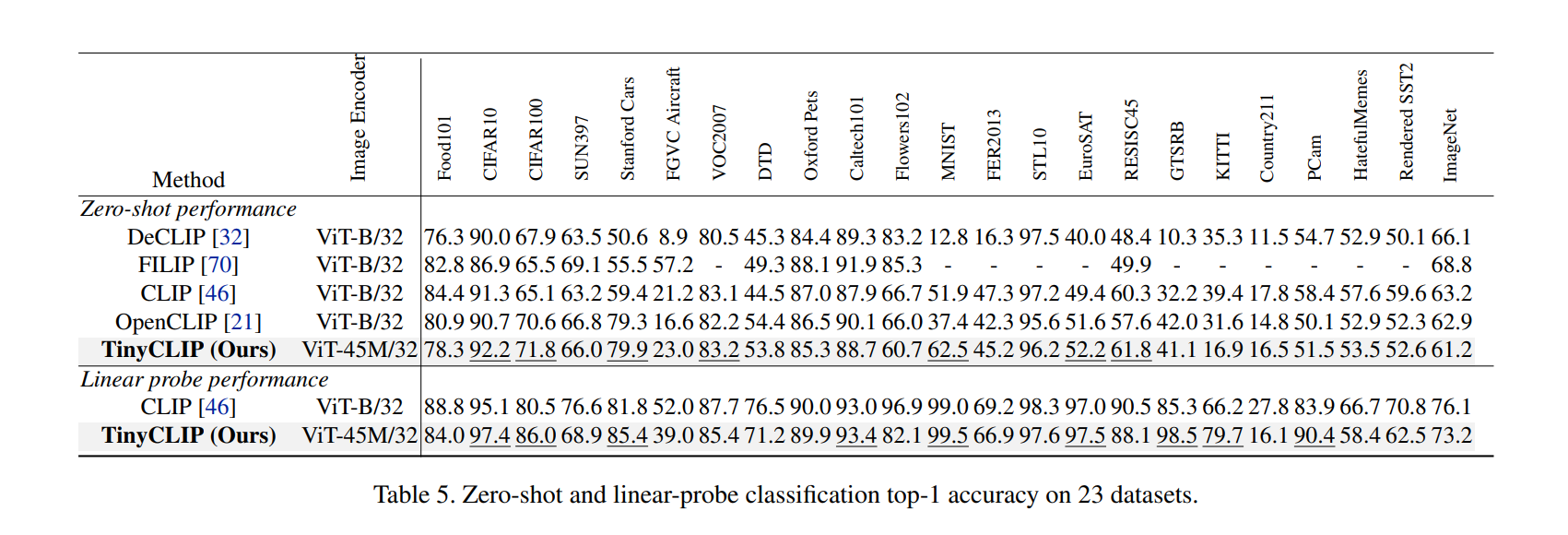
| 从表5可以看出,本文提出的TinyCLIP压缩模型在23个数据集上的零样本和线性探测分类任务上也展现出很强的泛化性能: | ||
|
|
||
| 1. 在零样本分类中,TinyCLIP在7个数据集上胜出,与原始OpenCLIP-ViT-B/32相比接近。 | ||
| 2. 在线性探测分类中,TinyCLIP在9个数据集上胜出,这个任务更依赖模型特征的判别性。 | ||
| 3. 尤其是在线性探测上,TinyCLIP在物体、场景、动物、食物等多个领域的数据集上都超过了原始模型。 | ||
| 4. 在一些细粒度的分类数据集上优势更加明显,如Oxford Pets, DTD, FGVC Aircraft等。 | ||
| 5. 在Caltech101和Flowers102更胜出15%以上。 | ||
|
|
||
| 这证明了TinyCLIP压缩后的小模型依然保留了强大的判别特征,不仅在ImageNet上表现强劲,在其他数据集上也展现了非常好的泛化能力,尤其是一些细粒度的分类任务。 | ||
|
|
||
| 这验证了本文提出的压缩方法可以很好地保留视觉语言模型的判别력,使得压缩后的小模型依然具有很强的迁移学习能力,能够适应多样的下游任务,而不仅仅局限于ImageNet分类。这对压缩型的视觉语言模型的实用性意义重大。 | ||
|
|
||
| ### 5. 讨论 | ||
|
|
||
| 这篇论文整体来说质量很高,对大规模视觉语言预训练模型压缩问题做出了开创性的探索。论文的主要优点在于:首先,它提出了TinyCLIP,这是第一个 focal 在 CLIP 模型压缩的工作,解决了一个非常重要而具有挑战的问题;其次,论文提出了亲和力模仿和权重继承等新颖的技术手段,实现了有效的跨模态知识蒸馏;另外,论文取得了state-of-the-art的模型压缩效果,使用2-11倍更少的参数取得与原模型近似或更好的效果,压缩后的模型也表现出很强的迁移学习能力,在各种下游任务上都有显著提升。这充分验证了论文方法的有效性。当然,论文也还有一些可改进之处,比如继续探索更高的压缩倍数,提高蒸馏效率等,但总体而言是一篇高质量、高影响力的论文,对该研究领域将产生重要推动作用。 | ||
|
|
||
| ### 6. 结论 | ||
|
|
||
| 在本论文中,我们提出了TinyCLIP,这是第一个用于大规模视觉语言预训练模型压缩的方法。实验表明,通过新颖的亲和力模仿和权重继承技术,以及渐进式的多阶段压缩策略,TinyCLIP可以将CLIP类模型的参数量减少2-11倍,计算量减少1.5-5倍,同时保持可竞争的性能。压缩后的小模型不仅在ImageNet图像分类任务上效果强劲,还展现了很好的泛化能力,在各种下游视觉任务上都获得了显著提升。可以说,TinyCLIP为大规模视觉语言模型的部署提供了一个高效、可行的解决方案,使大小适宜的强大跨模态模型成为可能。本研究对推动视觉语言模型的实际应用意义重大。未来我们将继续探索更高效的压缩与知识蒸馏方案,以及在更小规模下压缩模型的效果。我们相信基于TinyCLIP的进一步研究将大大促进视觉语言模型的发展和应用。 |