This repository has been archived by the owner on Oct 25, 2024. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Create ICCV2023 SOTA 长短距离循环更新网络--LRRU介绍.md
- Loading branch information
Showing
1 changed file
with
127 additions
and
0 deletions.
There are no files selected for viewing
127 changes: 127 additions & 0 deletions
127
docs/academic/算法科普/Transformer/ICCV2023 SOTA 长短距离循环更新网络--LRRU介绍.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,127 @@ | ||
| # ICCV2023 SOTA!长短距离循环更新网络--LRRU介绍 | ||
|
|
||
| ## 1. 文章一览 | ||
|
|
||
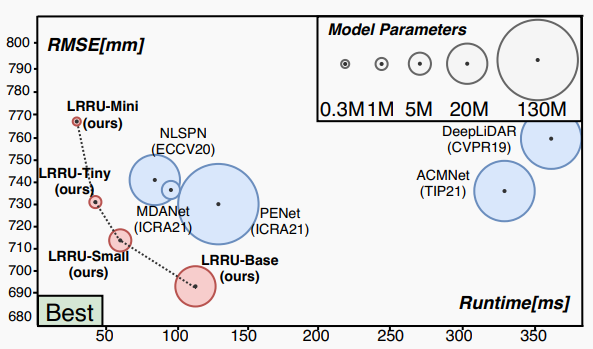
| 本文介绍了一种名为长短距离循环更新(LRRU)网络的轻量级深度网络框架,用于深度补全。深度补全是指从稀疏的距离测量估计密集的深度图的过程。现有的深度学习方法使用参数众多的大型网络进行深度补全,导致计算复杂度高,限制了实际应用的可能性。相比之下,本文提出的LRRU网络首先利用学习到的空间变体核将稀疏输入填充以获得初始深度图,然后通过迭代更新过程灵活地更新深度图。迭代更新过程是内容自适应的,可以从RGB图像和待更新的深度图中学习到核权重。初始深度图提供了粗糙但完整的场景深度信息,有助于减轻直接从稀疏数据回归密集深度的负担。实验证明,LRRU网络在减少计算复杂度的同时实现了最先进的性能,更适用于深度补全任务。 | ||
|
|
||
|  | ||
|
|
||
| 图1 不同模型性能与效率比较 | ||
|
|
||
| ## 2. 原文摘要 | ||
|
|
||
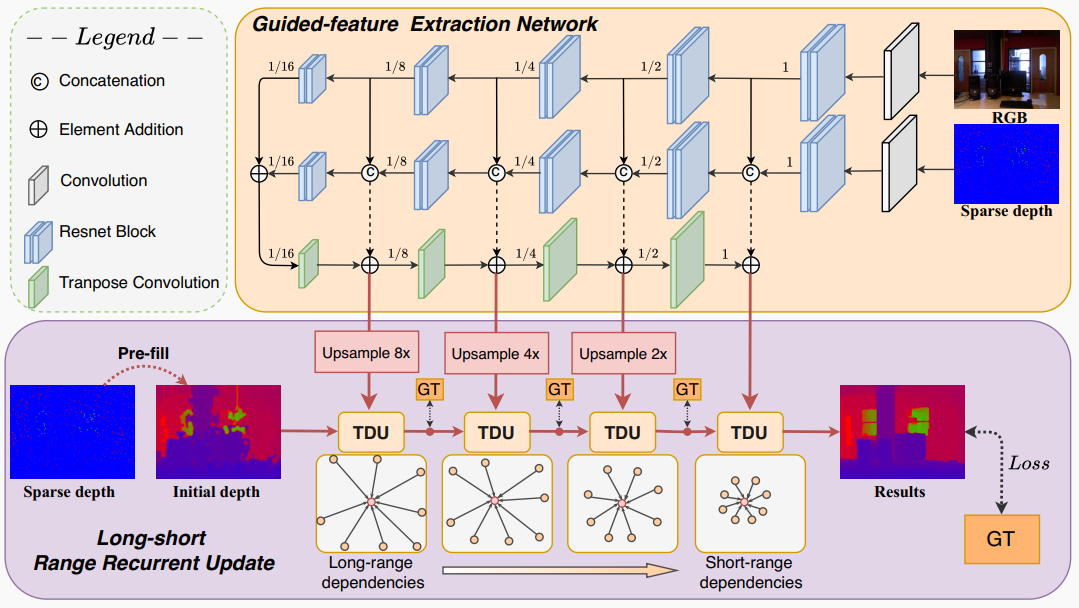
| 现有的基于深度学习的深度补全方法通常需要堆叠大量的网络层,以从稀疏的数据直接预测密集的深度图。虽然这种方法大大推动了此任务的发展,但随之带来的巨大计算复杂度限制了实际应用。为了更高效地完成深度补全任务,我们提出了一种新型的轻量级深度网络框架LRRU(Long-short Range Recurrent Updating Networks)。LRRU首先使用非学习方法粗略填充稀疏的输入,得到初始的密集深度图,然后通过学习到的空间变化内核迭代更新初始深度图。我们提出的Target-Dependent Update模块可以动态调整内核权重,并考虑RGB图像及深度图本身的内容特征进行自适应更新。另外,我们还提出了一种长短范围循环更新策略,可以动态调整内核范围,以捕获不同距离尺度的相关信息。实验结果表明,LRRU在不同的参数配置下都可以达到SOTA性能。具体来说,最大的LRRU-Base模型在NYUv2和KITTI数据集上分别获得最优的性能。 | ||
|
|
||
|  | ||
|
|
||
| 图2 LRRU网络流程图 | ||
|
|
||
| ## 3. 方法细节 | ||
|
|
||
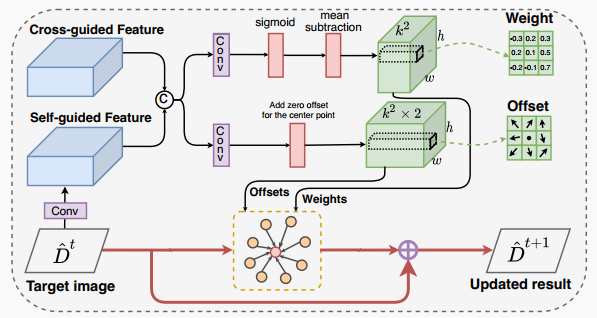
| 给定一个稀疏深度图,我们首先用一个简单的非学习方法将其填充为密集深度图。然后,根据我们提出的长短范围循环更新策略(详见3.2节),我们的方法通过目标相关更新模块(详见3.1节)迭代优化初始深度图,以得到精确密集的深度图。在3.3节,我们提供了方法的实现细节。为了方便描述,我们使用目标深度($ \hat{D}_{t} $)来表示第$t$次更新的深度图。 | ||
|
|
||
|  | ||
|
|
||
| 图3 目标相关更新模块 | ||
|
|
||
| #### 3.1 目标相关更新单元 | ||
|
|
||
| 我们提出的目标相关更新(TDU)模块通过学习空间变化内核来更新目标深度图,这些内核能够根据每个像素及其邻域之间的亲和力进行调整。为了避免固定局部邻域带来的冗余信息,我们的TDU使用全卷积网络预测内核权重和邻域采样位置,其中采样位置是通过学习相对于规则网格的偏移量实现的。然而,由于权重和偏移量缺乏直接监督信号,这可能导致训练不稳定。为了解决这个问题,我们利用RGB图像和稀疏深度图的特征来引导TDU获取合适的邻域,因为RGB图像中包含丰富的结构细节,稀疏深度图中包含准确的场景深度信息。此外,我们还考虑了待更新深度图本身的特征来引导TDU,使得更新操作与目标深度图内容相关联,这可以避免产生次优解,尤其是当初始深度图不是直接从RGB图像和稀疏深度图回归得到时。因此,除了RGB图像和稀疏深度图之外,我们还提出从目标深度图本身中提取特征来引导TDU。我们将从RGB图像和稀疏深度图中提取的特征称为交叉引导特征,将从目标深度图中提取的特征称为自引导特征。如式(1)所示,交叉引导特征 $F_{Cross-guided}$ 从特征提取网络 $f_{\theta}$ 中的RGB图像$I$和稀疏深度图$S$中提取,自引导特征 $F_{Self-guided}$ 通过卷积层 $f_{\psi}$ 从目标深度图$\hat{D}_{t}$ 中获得。 | ||
|
|
||
| 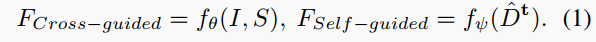 | ||
|
|
||
| 权重和偏移回归。如图3所示,我们的TDU首先连接交叉引导特征和自引导特征,然后通过两个独立的$1\times 1$卷积层分别学习权重特征图和偏移特征图。为使权重和偏移快速收敛,我们对它们的行为添加一些限制来指导学习过程。具体来说,权重特征图有$k^2$个通道,其中$k$是内核大小,在本文中设置为3。我们对sigmoid层的输出应用sigmoid层使权重大于0且小于1。此外,我们从sigmoid层的输出中减去均值,使权重之和为0,起到类似高通滤波器的作用。偏移特征图有$2k^2$个通道,表示相对于规则网格上的位置在x和y方向上的偏移。但是,为确保每个参考像素参与其自身的更新过程,我们首先预测具有$2(k^2-1)$个通道的偏移特征图,然后将零插入偏移特征图的中心。 | ||
|
|
||
| 残差连接。我们观察到更新单元的输入和输出图高度相关,共享低频信息。因此,与现有的SPN不同,这些SPN直接预测更新后的深度图,我们提出学习目标深度图的残差图像以增强结构细节和抑制噪声。给定学习到的权重和采样偏移,如式(2)所示,位置$p=(x,y)$处的残差图像$\Delta \hat{D}_{t}^{p}$ 通过加权平均获得。 | ||
|
|
||
| 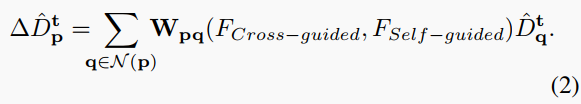 | ||
|
|
||
| 在式(2)中,$N(p)$表示位置$p$的邻域集合。由于偏移通常是分数,我们使用双线性插值对局部四点进行采样。滤波器权重$W$从交叉引导特征和自引导特征中预测。我们聚合来自稀疏选择的位置的深度值,具有学习到的权重。然后,如式(3)所示,我们将残差图像添加到目标深度图中以获得更新后的深度图$\hat{D}_{t+1}$。 | ||
|
|
||
|  | ||
|
|
||
| #### 3.2 长短距离循环更新策略 | ||
|
|
||
| 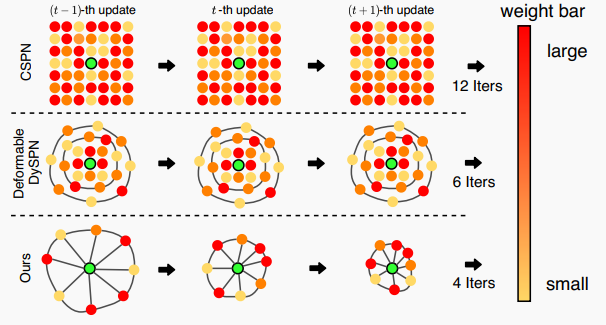 | ||
|
|
||
| 图4 长短距离循环更新策略 | ||
|
|
||
| 为了在更新过程中获得适合各自目标的适当内核权重和范围,我们需要一个有效的循环更新策略来指导TDU。具体来说,由于对于由非学习方法获得的初始深度图,只有少数可用的稀疏测量点及其周围点具有高精度,而大多数像素的周围点则不准确,因此,在更新过程开始时,我们应该采用大的内核范围,以便从一些长距离但准确的点中获取邻域信息。然而,随着深度图变得更精细,我们应该逐渐缩小内核范围,以便更多地关注短距离内的点,因为它们通常与参考点更相关。但是,现有的SPN使用的递归更新策略不够灵活,无法满足上述需求。例如,CSPN和NLSPN在更新过程中使用固定的内核权重和范围,这不仅限制了SPN的表示能力,还需要大量迭代来获得长距离依赖关系。尽管CSPN++和DySPN通过模型集成和注意机制缓解了这个问题,但它们的内核范围在更新过程中仍然保持不变。 | ||
|
|
||
|  | ||
|
|
||
| 图5 在迭代更新过程中内核范围的变化 | ||
|
|
||
|  | ||
|
|
||
| 图6 在KITTI和NYUv2数据集上邻域最大最小距离分析 | ||
|
|
||
| 为了指导TDU在更新过程中动态调整内核范围,从而获得适合各自目标的适当内核权重和范围,我们在本文中提出了一种长短距离循环更新策略,如图4所示。每个TDU的参数,包括内核权重和邻域的采样位置,都是通过考虑交叉引导特征和自引导特征来学习的。我们发现,当不同TDU分别由不同尺度的交叉引导特征引导时,由更小尺度的交叉引导特征引导的TDU将自适应地学习以获得相对更大范围的邻域,反之亦然。这是因为不同尺度的交叉引导特征具有不同的感受野。基于这一观察,我们让第一次迭代的TDU使用 1/8 尺度的交叉引导特征图来引导,以便从一些长距离但准确的点中获取邻域信息。在后续迭代中,我们让TDU逐渐使用更大尺度的交叉引导特征图,例如1/4尺度、1/2尺度和全尺度,以便更多地关注短距离内的点。图5和图6展示了在迭代更新过程中内核范围从大到小的变化。由于提出的循环更新策略具有很高的灵活性,我们只需要很少的迭代次数和邻域即可获得满意的结果。 | ||
|
|
||
| #### 3.3 实现细节 | ||
|
|
||
| 网络架构。我们的网络架构如图2所示,由两个部分组成:交叉引导特征提取网络和长短距离循环更新模块。交叉引导特征提取网络使用深度编码器和RGB编码器这两个子网络,分别从稀疏深度图和对应的RGB图像中提取特征。然后,多尺度RGB特征被注入到深度编码器中,以实现不同模式信息的充分整合。接着,解码器网络用于学习融合后的多尺度特征的残差。最后,交叉引导特征被上采样到与初始深度图相同的分辨率,并作为输入传递给长短距离循环更新模块中的TDU。 | ||
|
|
||
| 损失函数。我们通过$L_1$和$L_2$距离对每个迭代输出与ground truth深度图进行监督,权重按指数递增。损失函数如式(4)定义。 | ||
|
|
||
| 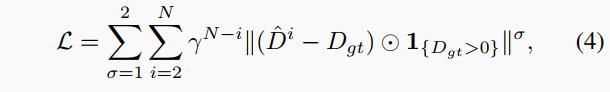 | ||
|
|
||
| 其中1表示ground truth中是否有值,$\odot$表示逐元素乘法。我们在实验中设置$\gamma=0.8$。 | ||
|
|
||
| 训练细节。我们使用PyTorch实现模型,在GeForce RTX 3090 GPU上进行训练和测试。所有模型从随机权重开始初始化。在训练过程中,我们使用批量大小为8的Adam优化器。我们设置$\beta_1=0.9,\beta_2=0.999$,权重衰减为$10^{-6}$,总迭代轮数为45。初始学习率为$10^{-3}$,前15轮保持不变,之后每5轮衰减50%。 | ||
|
|
||
| ## 4. 实验结果 | ||
|
|
||
| 我们在NYUv2和KITTI数据集上对LRRU进行了评估,并将其与其他state-of-the-art方法进行了比较。结果表明,LRRU在不同的参数配置下都优于其他方法。特别是,最大的LRRU-Base模型在NYUv2上达到了最佳性能,在KITTI基准测试上获得了第一名。表1和表2分别给出了LRRU和其他方法在两个数据集上的定量结果,图3和图4展示了LRRU和其他方法在两个数据集上的定性结果。 | ||
|
|
||
| 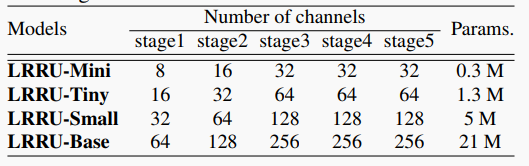 | ||
|
|
||
| 表1 四个LRRU变体的设置 | ||
|
|
||
|  | ||
|
|
||
| 表2 在KITTI基准测试上的定量比较 | ||
|
|
||
|  | ||
|
|
||
| 图7 在KITTI测试数据集上的定性比较 | ||
|
|
||
|  | ||
|
|
||
| 表3 消融实验 | ||
|
|
||
|  | ||
|
|
||
| 表4 使用不同更新模块的比较 | ||
|
|
||
| 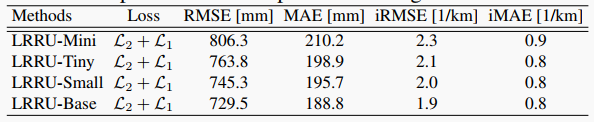 | ||
|
|
||
| 表5 使用不同损失函数的比较 | ||
|
|
||
|  | ||
|
|
||
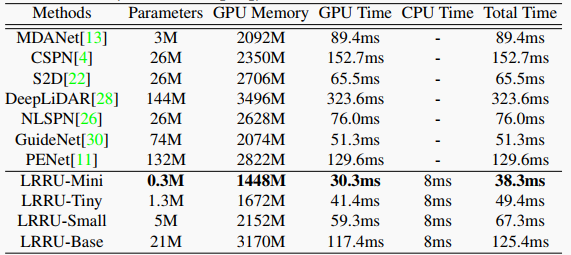
| 表6 硬件花费比较 | ||
|
|
||
|  | ||
|
|
||
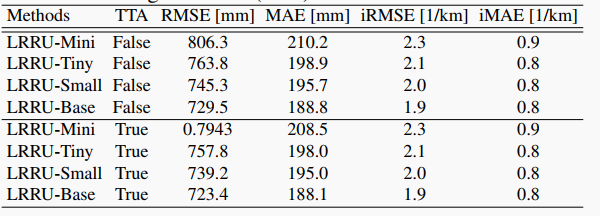
| 表7 在KITTI验证集上使用测试时数据增强的结果 | ||
|
|
||
|  | ||
|
|
||
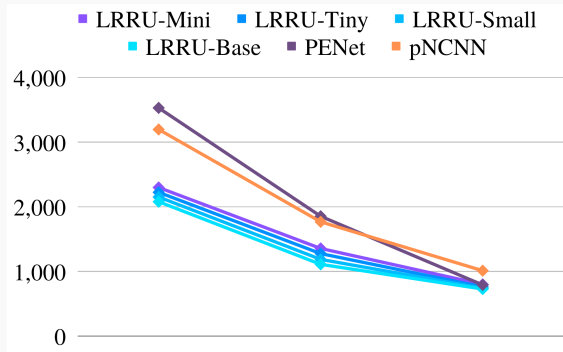
| 图8 在RMSE的性能 | ||
|
|
||
|  | ||
|
|
||
| 表8 在NYUv2数据集上的定量评估 | ||
|
|
||
|  | ||
|
|
||
| 图9 在NYUv2数据集上的定性结果 | ||
|
|
||
| 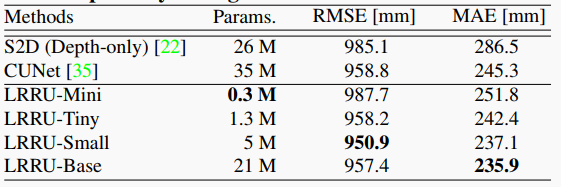 | ||
|
|
||
| 表9 在仅深度的情况下的结果 | ||
|
|
||
| ## 5. 本文总结 | ||
|
|
||
| 本文提出了一种新型高效的深度补全网络LRRU,它通过结合目标相关更新模块和长短距离循环策略,实现了在参数量和推理时间较少的情况下达到SOTA的性能。与直接回归方法相比,LRRU采用了预填充稀疏深度图并迭代更新的方式,更加有效地优化深度图。目标相关更新模块可以根据RGB图像、稀疏深度图和当前深度图自适应地调整内核参数,从而更好地适应不同的目标。长短距离循环策略可以从长距离逐步聚焦到短距离,使更新过程更加灵活和精细。实验结果表明,LRRU的不同规模变体在NYUv2和KITTI数据集上都优于现有方法。未来工作将探索将LRRU应用于其他密集预测任务,如单目深度估计和语义分割。 |