민첩하고, 강력하며, 독립적으로 배포할 수 있으며, 분산 처리를 지원하는 크롤링 프레임워크입니다.
SeimiCrawler의 목표는 Java 세계에서 가장 쉽고 실용적인 크롤링 프레임워크가 되는 것입니다.
SeimiCrawler는 민첩하고, 독립적으로 배포할 수 있으며, 분산 처리를 지원하는 Java 크롤링 프레임워크로서, 초보자가 성능이 좋은 크롤링 시스템을 쉽게 개발하고, 크롤링 시스템의 개발 효율을 높이는 것을 목표로 합니다. SeimiCrawler의 세계에서 대부분의 사용자는 주로 크롤링 로직에 집중하면 되며, 나머지는 Seimi가 모두 해결해줍니다. SeimiCrawler는 Python의 크롤링 프레임워크인 Scrapy에서 영감을 얻었지만, Java 언어의 특성과 Spring의 특성을 결합하여, XPath를 사용하여 HTML을 분석하는 것이 더욱 효율적이게 만들었습니다. 따라서 SeimiCrawler의 기본 HTML 분석기는 JsoupXpath (독립된 확장 프로젝트, Jsoup에 포함되지 않음)이며, 기본적으로 HTML 데이터 추출은 XPath를 사용합니다 (물론, 데이터 처리는 다른 분석기를 선택할 수도 있습니다). SeimiAgent를 통해 복잡한 동적 페이지 렌더링 크롤링 문제를 완벽하게 해결할 수 있으며, SpringBoot를 완벽히 지원하여 사용자의 창의력과 상상력을 극대화합니다.
JDK1.8+
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>GitHub 최신 버전 참조</version>
</dependency>
표준 SpringBoot 프로젝트를 생성하고, crawlers 패키지에 크롤링 규칙을 추가합니다. 예를 들어:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// 중복 테스트용
return new String[]{"http://www.cnblogs.com/", "http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response) {
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// 작업 수행
} catch (Exception e) {
e.printStackTrace();
}
}
}
application.properties에서 설정
# SeimiCrawler 시작
seimi.crawler.enabled=true
seimi.crawler.names=basic
표준 SpringBoot 시작 방법으로 실행합니다.
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}더 복잡한 사용 방법은 아래의 더 자세한 문서를 참고하거나 Github의 demo를 참고하세요.
일반적인 Maven 프로젝트를 만들고, 패키지 crawlers 아래에 크롤링 규칙을 추가합니다. 예를 들어:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// 두 개는 중복 테스트용
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// 어떤 처리를 할 것인지
} catch (Exception e) {
e.printStackTrace();
}
}
}
그런 다음 어떤 패키지든 상관없이 Main 함수를 추가하여 SeimiCrawler를 시작합니다:
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}
이로써 가장 간단한 크롤링 시스템 개발 프로세스가 완료되었습니다.
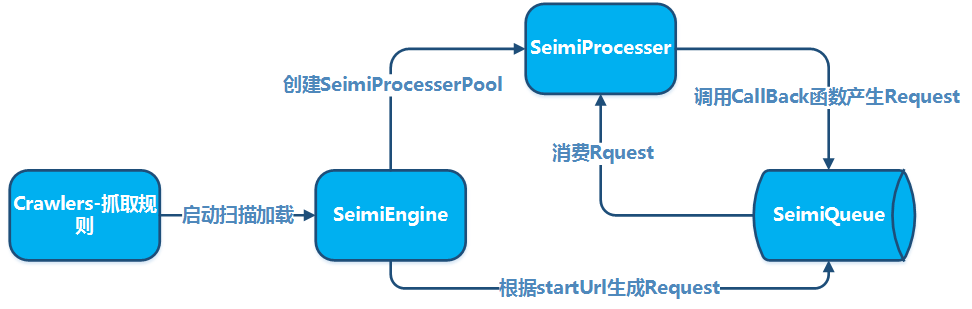
약속이 필요한 주된 이유는 SeimiCrawler로 개발한 크롤링 시스템의 원코드를 더욱 정형화하고 읽기 쉽게 하기 위해서입니다. 모든 팀원이 같은 약속을 따르면, 팀원 간에 협력하여 개발할 때 비즈니스 엔지니어링의 코드가 더욱 쉽게 읽히고 수정될 수 있습니다. 이런 방식은 특정 사람이 비즈니스 로직을 개발했을 때, 다른 사람이 그 클래스를 찾는 것조차 어려워지는 상황을 방지할 수 있습니다. 우리는 강력하고, 간단하며, 사용하기 좋은 시스템을 원합니다. 마지막으로, 약속이 있다고 해서 SeimiCrawler가 유연하지 않다는 의미는 아닙니다.
- SeimiCrawler의 컨텍스트는 spring을 기반으로 하므로, 모든 spring 형식의 설정 파일과 spring의 일반적인 사용법을 지원합니다. SeimiCrawler는 엔지니어링 클래스패스 아래의 모든 xml 형식의 설정 파일을 스캔하지만, 파일 이름이
seimi로 시작하는 xml 설정 파일만 SeimiCrawler에서 인식되고 로드됩니다. - SeimiCrawler의 로그는 slf4j를 사용하며, 구체적인 구현은 별도로 구성할 수 있습니다.
- Seimi 개발 시 유의해야 할 약속은 아래 개발 포인트에서 하나씩 소개하겠습니다.
크롤러 규칙 클래스는 SeimiCrawler를 사용하여 크롤러를 개발하는 가장 중요한 부분이며, 빠른 시작에서의 Basic 클래스가 기본 크롤러 클래스의 예입니다. 크롤러를 작성할 때 다음 사항에 주의해야 합니다:
BaseSeimiCrawler를 상속해야 합니다.@Crawler어노테이션을 붙여야 합니다. 어노테이션의name속성은 선택적이며, 설정되면 해당 크롤러는 정의한 이름으로 명명됩니다. 그렇지 않으면 기본적으로 클래스 이름이 사용됩니다.- SeimiCrawler가 스캔할 수 있는 모든 크롤러는
crawlers패키지 내에 있어야 합니다., 예를 들어:cn.wanghaomiao.xxx.crawlers, 또한 프로젝트에 포함된 데모 엔지니어링을 참조할 수 있습니다. 크롤러를 초기화한 후,public String[] startUrls();와public void start(Response response)두 가지 가장 기본적인 메서드를 구현해야 합니다. 이 구현을 완료하면 간단한 크롤러가 작성됩니다.
현재 @Crawler 어노테이션은 다음과 같은 속성을 가지고 있습니다:
name크롤러 규칙의 이름을 사용자 정의합니다. 하나의 SeimiCrawler가 스캔 범위 내에서는 같은 이름을 가진 크롤러가 있을 수 없습니다. 기본적으로 클래스 이름이 사용됩니다.proxySeimi에게 이 크롤러가 프록시를 사용할지, 그리고 어떤 프록시를 사용할지 알려줍니다. 현재 지원되는 형식은http|https|socket://host:port이며, 이 버전에서는 사용자 이름과 비밀번호를 포함하는 프록시는 지원되지 않습니다.useCookie쿠키를 사용할지 여부를 결정합니다. 활성화되면 브라우저와 같이 요청 상태를 유지할 수 있으며, 이로 인해 추적될 수도 있습니다.queue현재 크롤러가 사용할 데이터 큐를 지정합니다. 기본적으로는 로컬 큐 구현DefaultLocalQueue.class를 사용하며, 기본 Redis 구현을 사용하거나 다른 큐 시스템 기반의 구현을 사용할 수도 있습니다. 이에 대한 자세한 내용은 나중에 설명할 것입니다.delay요청을 처리하는 시간 간격(초 단위)을 설정합니다. 기본값은 0이며, 즉 간격이 없습니다.httpTypeDownloader 구현 유형을 지정합니다. 기본 Downloader 구현은 Apache Httpclient이며, 이를 통해 네트워크 요청 처리 구현을 OkHttp3로 변경할 수 있습니다.httpTimeOut사용자 정의 타임아웃을 지원하며, 단위는 밀리초입니다. 기본값은 15000ms입니다.
이는 크롤러의 엔트리 포인트로, 반환 값은 URL 배열입니다. 기본적으로 startURL은 GET 요청으로 처리됩니다. 특수한 상황에서 Seimi가 POST 메소드로 startURL을 처리하도록 하려면, 해당 URL의 끝에 ##post를 추가하면 됩니다. 예를 들어, http://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post. 이 지정은 대소문자를 구별하지 않습니다. 이 규칙은 startURL 처리에만 적용됩니다.
이 메서드는 startURL의 콜백 함수로, Seimi가 startURL 요청으로 반환된 데이터를 어떻게 처리할지 지시합니다.
- 텍스트 결과
Seimi는 기본적으로 HTML 데이터 추출을 위해 XPath를 사용하는 것을 권장합니다.XPath의 초기 학습 과정은 어렵지만, 이를 배운 후의 개발 효율성과 비교하면 그 비용은 매우 적습니다.
JXDocument doc = response.document();로JXDocument(JsoupXpath의 문서 객체)를 가져올 수 있으며, 이후doc.sel("xpath")를 통해 원하는 모든 데이터를 추출할 수 있습니다.通行证任何数据应该都是一条XPath语句就能搞定了。想对Seimi使用的XPath语法解析器以及想对XPath进一步了解的同学请移步JsoupXpath。当然,实在对XPath提不起感觉的话,那么response里有原声的请求结果数据,您可自行选择其他数据解析器进行处理。 - 파일 결과
파일 형태의 반환 결과일 경우,
response.saveTo(File targetFile)를 사용하여 저장하거나, 파일 바이트 스트림byte[] getData()를 얻어 다른 작업을 수행할 수 있습니다.
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* 이 부분은 주로 상위로부터 전달되는 일부 사용자 정의 데이터를 저장하는 데 사용됩니다.
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* 웹 페이지 내용의 실제 출처
*/
private String realUrl;
/**
* 이 요청 결과의 HTTP 처리자 유형
*/
private SeimiHttpType seimiHttpType;
기본 콜백 함수만 사용하는 것은 당신의 요구를 만족시키기에 충분하지 않을 것입니다. startURL 페이지에서 몇몇 URL을 추출하여 데이터 요청 및 처리를 하려면 사용자 정의 콜백 함수가 필요합니다. 다음 사항들을 주의하십시오:
- V2.0부터 메서드 참조를 지원하여 콜백 함수 설정이 보다 자연스럽습니다. 예:
Basic::getTitle. - 콜백 함수에서 생성된
Request는 다른 콜백 함수를 지정하거나 자기 자신을 콜백 함수로 지정할 수 있습니다. - 콜백 함수는
public void callbackName(Response response)형식을 충족해야 합니다. 즉, 메서드는 공용(public)이며, 하나의 매개변수Response만 받고, 반환값이 없습니다. Request에 콜백 함수를 설정하려면 해당 콜백 함수의String타입 이름만 제공하면 됩니다. 예: 빠른 시작에서의getTitle.BaseSeimiCrawler를 상속한 Crawler는 콜백 함수 내에서 바로 부모 클래스의push(Request request)를 호출하여 새로운 요청을 요청 대기에 보낼 수 있습니다.Request.build()를 통해Request를 생성할 수 있습니다.
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta,int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* 요청할 URL
*/
@NotNull
private String url;
/**
* 요청할 메서드 유형 get, post, put...
*/
private HttpMethod httpMethod;
/**
* 요청에 필요한 매개변수가 있으면 여기에 저장합니다.
*/
private Map<String,String> params;
/**
* 이 부분은 주로 하위 콜백 함수로 전달되는 일부 사용자 정의 데이터를 저장하는 데 사용됩니다.
*/
private Map<String,Object> meta;
/**
* 콜백 함수 메서드 이름
*/
@NotNull
private String callBack;
/**
* 콜백 함수가 Lambda 표현식인지 여부
*/
private transient boolean lambdaCb = false;
/**
* 콜백 함수
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* 중지 신호, 해당 신호를 받은 처리 스레드는 종료됩니다.
*/
private boolean stop = false;
/**
* 재요청 가능한 최대 횟수
*/
private int maxReqCount = 3;
/**
* 현재 요청이 실행된 횟수를 기록하기 위한 용도
*/
private int currentReqCount = 0;
/**
* 요청이 중복 필터링 메커니즘을 거치지 않도록 지정하는 용도
*/
private boolean skipDuplicateFilter = false;
/**
* 해당 요청에 대해 SeimiAgent를 사용하도록 지정하는 용도
*/
private boolean useSeimiAgent = false;
/**
* 사용자 정의 Http 요청 프로토콜 헤더
*/
private Map<String, String> header;
/**
* SeimiAgent의 렌더링 시간을 정의, 단위는 밀리초
*/
private long seimiAgentRenderTime = 0;
/**
* SeimiAgent에서 지정된 js 스크립트를 실행하도록 지원
*/
private String seimiAgentScript;
/**
* SeimiAgent에 제출되는 요청이 쿠키를 사용하도록 지정
*/
private Boolean seimiAgentUseCookie;
/**
* SeimiAgent가 결과를 어떤 형식으로 렌더링할 것인지 지정, 기본값은 HTML
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* 사용자 정의 쿠키 추가를 지원
*/
private List<SeimiCookie> seimiCookies;
/**
* json request body 지원 추가
*/
private String jsonBody;
}
SeimiCrawler의 기본 UA는 SeimiCrawler/JsoupXpath입니다. 사용자 정의 UserAgent를 사용하려면 BaseSeimiCrawler의 public String getUserAgent() 메서드를 오버라이드 할 수 있습니다. SeimiCrawler는 매번 요청 처리 시 UserAgent를 가져오므로, UserAgent를 위장하고자 하는 경우 UA 라이브러리를 자체적으로 구현하여 매번 무작위로 값을 반환할 수 있습니다.
@Crawler annotation을 소개하는 부분에서 이미 설명한 바 있지만, 여기서 다시 강조하는 이유는 이러한 기본 기능을 빠르게 살펴보기 위함입니다. 쿠키 사용 여부는 @Crawler annotation의 useCookie 속성을 통해 설정됩니다. 또한 Request.setSeimiCookies(List<SeimiCookie> seimiCookies) 또는 Request.setHeader(Map<String, String> header)를 통해 사용자 정의 설정을 할 수 있습니다. Request 객체는 많은 사용자 정의 기능을 지원하므로, Request 객체를 자세히 살펴보면 많은 아이디어를 얻을 수 있을 것입니다.
@Crawler annotation의 proxy 속성을 통해 설정합니다. 자세한 내용은 @Crawler 소개를 참조하세요. 동적으로 프록시를 지정하려면 다음 섹션 "동적 프록시 설정"을 참조하세요. 현재 지원되는 형식은 http|https|socket://host:port 세 가지입니다.
@Crawler annotation의 delay 속성을 통해 설정합니다. 요청 간격을 초 단위로 설정할 수 있으며, 기본값은 0초로 간격이 없습니다. 많은 경우에 콘텐츠 제공자는 요청 빈도 제한을 반 크롤러 대책의 일환으로 사용하므로, 필요하다면 이 매개변수를 조정하여 더 나은 크롤링 효과를 얻을 수 있습니다.
BaseSeimiCrawler의 public String[] allowRules()를 오버라이드하여 URL 요청 흰색 목록 규칙을 설정합니다. 규칙은 정규 표현식이며, 아무 규칙에도 맞으면 요청을 허용합니다.
BaseSeimiCrawler의 public String[] denyRules()를 오버라이드하여 URL 요청 검정색 목록 규칙을 설정합니다. 규칙은 정규 표현식이며, 아무 규칙에도 맞으면 요청을 차단합니다.
BaseSeimiCrawler의 public String proxy()를 오버라이드하여 Seimi가 특정 요청에서 사용할 프록시 주소를 알려줍니다. 여기서는 기존 프록시 라이브러리에서 순서대로 또는 무작위로 프록시 주소를 반환할 수 있습니다. 이 프록시 주소가 비어 있지 않으면, @Crawler의 proxy 속성 설정은 무시됩니다. 현재 지원되는 형식은 http|https|socket://host:port입니다.
@Crawler 주석의 useUnrepeated 속성을 사용하여 시스템 중복 제거를 활성화할 수 있으며, 기본적으로 활성화되어 있습니다.
현재 SeimiCrawler는 301, 302,以及meta refresh 리다이렉트를 지원합니다. 이러한 리다이렉트 URL은 Response 객체의 getRealUrl()을 통해 실제 리다이렉트 후의 연결을 얻을 수 있습니다.
리퀘스트가 처리 중에 예외가 발생하면, 세 번의 기회를 통해 처리 큐에 다시 넣어 재처리됩니다. 그러나 최종적으로 실패하면, 시스템은 crawler의 public void handleErrorRequest(Request request) 메소드를 호출하여 문제 있는 요청을 처리합니다. 기본 구현은 로그로 기록하지만, 개발자는 이 메소드를 오버라이드하여 자체 처리를 추가할 수 있습니다.
이 부분은 특히 강조해야 합니다. SeimiAgent에 대해 잘 모르는 분들은 SeimiAgent 프로젝트 페이지를 먼저 참조하세요. 간단히 말해서, SeimiAgent는 서버에서 실행되는 브라우저 엔진으로, QtWebkit 기반으로 개발되어 표준 HTTP 인터페이스를 통해 서비스를 제공합니다. 복잡한 동적 웹페이지의 렌더링, 스크린샷 캡처, 모니터링 등의 요구를专门为解决而设计的。总之,它对页面的处理是标准浏览器级别的,你可以基于它获取任何在浏览器中可以获取的信息。
为了让seimiCrawler支持SeimiAgent,首先需要告诉SeimiAgent的服务地址。
通过SeimiConfig配置,例如
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
在application.properties中配置
Note: 对于“自動跳转”和“关于自动跳转”部分,我翻译为“자동 리다이렉트에 대한 정보”以保持一致性,但“以及”应为“와”或“과”(取决于前词的最后一个音节)。正确的句子应是“현재 SeimiCrawler는 301, 302, 그리고 meta refresh 리다이렉트를 지원합니다。”
修正后的翻译:
현재 SeimiCrawler는 301, 302, 그리고 meta refresh 리다이렉트를 지원합니다. 이러한 리다이렉트 URL은 Response 객체의 getRealUrl()을 통해 실제 리다이렉트 후의 연결을 얻을 수 있습니다。
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
SeimiAgent가 처리할 요청을 결정하고 SeimiAgent가 어떻게 처리할지를 지정합니다. 이는 Request 단위에서 이루어집니다.
Request.useSeimiAgent()SeimiCrawler에게 이 요청이 SeimiAgent에 제출되도록 알려줍니다.Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)SeimiAgent의 렌더링 시간(모든 자원 로드 후, 자바스크립트 등의 스크립트를 실행하여 최종 페이지를 렌더링하는 데 SeimiAgent가 얼마나 많은 시간을 줄지를 설정합니다). 시간 단위는 밀리초입니다.Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)SeimiAgent가 쿠키를 사용할지 여부를 알려줍니다. 여기서 설정하지 않으면 seimiCrawler의 전역 쿠키 설정에 따라 판단됩니다.- 기타 만약 Crawler에 프록시를 설정했다면, 이 요청이 SeimiAgent에 전달될 때 seimiCrawler는 자동으로 SeimiAgent에게 이 프록시를 사용하도록 합니다.
- 데모 실제 사용은 저장소의 데모를 참고하세요.
application.properties에서 설정
seimi.crawler.enabled=true
# 시작 요청을 수행할 crawler의 이름을 지정
seimi.crawler.names=basic,test
그 후 표준 springBoot를 시작합니다.
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
main 함수를 추가하고, 독립적인 시작 클래스로 만들어 주는 것이 좋습니다. 예를 들어, demo 프로젝트와 같이. main 함수에서 Seimi 객체를 초기화하고, SeimiConfig를 통해 Redis 클러스터 정보와 같은 분산 큐에 필요한 특정 매개변수, 또는 seimiAgent의 host 정보 등을 구성할 수 있습니다. 물론, SeimiConfig는 선택적입니다. 예를 들어:
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimi에는 다음과 같은 시작 함수가 포함되어 있습니다:
public void start(String... crawlerNames)하나 또는 여러 Crawler를 실행하여 수집을 시작합니다.public void startAll()모든 로드된 Crawler를 시작합니다.public void startWithHttpd(int port, String... crawlerNames)지정된 포트의 HTTP 서비스를 시작시키고, 특정 Crawler를 실행하여 수집을 시작합니다./push/crawlerName을 통해 해당 Crawler에 수집 요청을 전송할 수 있으며,req매개변수를 받아 POST 및 GET을 지원합니다.public void startWorkers()모든 로드된 Crawler를 초기화하고 수집 요청을 수신합니다. 이 시작 함수는 주로 분산 배포 시 하나 또는 여러 worker 시스템을 시작하는 데 사용되며, 나중에 분산 배포에 대한 자세한 내용이 설명될 것입니다.
프로젝트 아래에서 아래 명령을 실행하여 전체 프로젝트를 패키지로 만들고 출력합니다.
Windows에서는 Windows 명령 프롬프트에서 로그 출력이 깨지는 것을 방지하기 위해 로그백 구성 파일의 콘솔 출력 형식을
GBK로 변경하세요. 기본값은UTF-8입니다.
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
이 시점에서 프로젝트의 target 디렉토리에는 seimi라는 디렉토리가 생성됩니다. 이 디렉토리는 최종적으로 컴파일되어 배포 가능한 프로젝트입니다. 아래 명령을 실행하여 시작합니다,
Windows에서:
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
Linux에서:
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
위의 내용은 스크립트에 직접 작성할 수 있으며, 디렉토리 구조도 상황에 따라 조정할 수 있습니다. 위의 예는 단순히 데모 프로젝트를 위한 것입니다. 실제 배포 시나리오에서는 SeimiCrawler의 전용 패키지 도구 maven-seimicrawler-plugin을 사용하여 패키지화 및 배포를 수행할 수 있습니다. '프로젝트화된 패키지 배포' 섹션에서 자세히 설명합니다.
프로젝트를 구축하는 데 Spring Boot 방식을 추천합니다. 이를 통해 기존의 Spring Boot 생태계를 활용하여 다양한 예상치 못한 기능을 확장할 수 있습니다. Spring Boot 프로젝트의 패키지화는 공식 Spring Boot 웹사이트의 표준 패키지화 방식을 따르면 됩니다.
mvn package
위에서 설명한 방식은 개발이나 디버깅에 편리하며, 당연히 프로덕션 환경에서의 시작 방식으로도 사용할 수 있습니다. 그러나 프로젝트화된 배포와 배포를 위해 SeimiCrawler는 SeimiCrawler 프로젝트를 패키지화하는 전용 도구를 제공합니다. 패키지를 만들어 직접 배포 및 실행할 수 있습니다. 다음의 몇 가지 작업을 수행하면 됩니다:
pom.xml에 플러그인을 추가합니다.
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
mvn clean package를 실행하면 됩니다. 패키지를 만든 후 디렉토리 구조는 다음과 같습니다:
.
├── bin # 해당 스크립트에는具체적인 시작 매개변수 설명이 있으므로 여기서는 자세히 설명하지 않습니다
│ ├── run.bat # Windows용 시작 스크립트
│ └── run.sh # Linux용 시작 스크립트
└── seimi
├── classes # 크롤러 프로젝트 비즈니스 클래스 및 관련 설정 파일 디렉토리
└── lib # 프로젝트 의존성 패키지 디렉토리
이제 이 패키지를 직접 배포 및 배포에 사용할 수 있습니다.
SeimiCrawler의 사용자 정의 스케줄링은 spring의 주석 @Scheduled를 직접 사용하여 구현할 수 있으며, 추가 설정이 필요하지 않습니다. 예를 들어, Crawler 규칙 파일에서 다음과 같이 정의할 수 있습니다:
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("나는 cron 표현식에 따라 실행되는 스케줄러입니다, 5초마다 한 번씩");
// 일정 시간마다 Request를 발송할 수 있습니다.
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
독립적인 service 클래스에서 정의하고자 하는 경우, 해당 service 클래스가 스캔될 수 있도록 하면 됩니다. @Scheduled에 대해 개발자는 spring 문서를 참조하여 파라미터의 세부 사항을 알아볼 수 있으며, SeimiCrawler의 GitHub Demo 예제를 참고할 수도 있습니다.
Bean을 정의하고, SeimiCrawler가 이를 자동으로 데이터를 추출하여 해당 필드에 채워넣도록 하고자 하는 경우 이 기능이 필요합니다.
먼저 예제를 살펴보겠습니다:
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
// 다음과 같이 작성할 수도 있습니다. @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
클래스 BlogContent는 사용자가 정의한 대상 Bean입니다. @Xpath는 데이터를 주입하려는 필드 위에 추가되어 XPath 추출 규칙을 구성합니다. 필드가 private 또는 public인지, getter와 setter가 반드시 존재해야 하는지는 중요하지 않습니다.
Bean을 준비한 후, 콜백 함수에서 Response의 내장 함수 public <T> T render(Class<T> bean)를 사용하여 데이터가 채워진 Bean 객체를 가져올 수 있습니다.
SeimiCrawler는 특정 콜백 함수나 모든 콜백 함수에 인터셉터를 추가할 수 있습니다. 인터셉터를 구현할 때 다음 사항들을 주의해야 합니다:
@Interceptor주석을 걸어야 합니다.SeimiInterceptor인터페이스를 구현해야 합니다.- 스캔 후 효력이 발생하기를 원하는 모든 인터셉터는 interceptors 패키지 아래에 must 배치되어야 합니다, 예를 들어
cn.wanghaomiao.xxx.interceptors와 같이, demo 프로젝트에서도 예제를 제공합니다. - 특정 함수들이 인터셉트되거나 모든 함수가 인터셉트되도록 하는 데 사용할 사용자 정의 주석을 정의해야 합니다.
이 주석은 Seimi에게 이 주석이 붙은 클래스가 인터셉터일 수 있다는 것을 알려줍니다 (정확히는 세부 구현이 위의 다른 약속을 따르도록 해야 하겠지만). 이 주석은 다음과 같은 속성을 가지고 있습니다:
everyMethod기본값은 false로, 이 인터셉터가 모든 콜백 함수를 인터셉트하도록 설정할지 여부를 나타냅니다.
인터페이스 바로 시작합니다.
public interface SeimiInterceptor {
/**
* 목표 메소드에 표시해야 하는 주석을 가져옵니다.
* @return Annotation
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* 여러 인터셉터의 실행 순서를 제어해야 할 때 이 메소드를 재정의할 수 있습니다.
* @return 가중치, 가중치가 클수록 외부 층에位置,优先拦截
*/
public int getWeight();
/**
* 목표 메소드 실행 전에 일부 로직을 정의할 수 있습니다.
*/
public void before(Method method, Response response);
/**
* 목표 메소드 실행 후에 일부 로직을 정의할 수 있습니다.
*/
public void after(Method method, Response response);
}
주석에서 이미 충분히 설명 않았으므로, 여기서는 추가로 설명하지 않습니다.
DemoInterceptor를 참조하세요, GitHub 링크
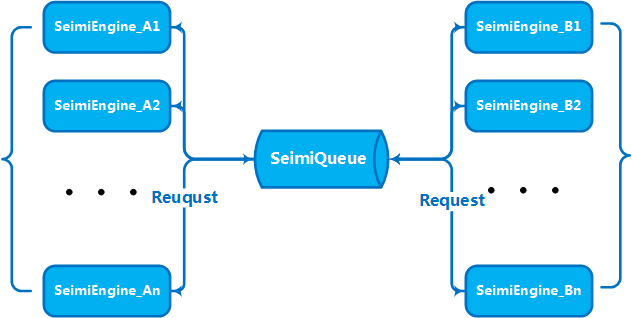
SeimiQueue는 SeimiCrawler에서 데이터 중계 및 시스템 내부와 시스템 간의 통신을 위한 유일한 통로입니다. 시스템의 기본 SeimiQueue는 스레드 안전한 블로킹 큐를 기반으로 한 구현입니다. 동시에 SeimiCrawler는 DefaultRedisQueue라는 redis 기반의 SeimiQueue 구현도 지원합니다. 또한 Seimi 규약에 맞는 SeimiQueue를 직접 구현할 수도 있으며, 사용 시 @Crawler 어노테이션의 queue 속성을 통해 어떤 구현을 사용할지 지정할 수 있습니다.
Crawler의 어노테이션 설정:
@Crawler(name = "xx", queue = DefaultRedisQueue.class)
application.properties에 설정
# SeimiCrawler 시작
seimi.crawler.enabled=true
seimi.crawler.names=DefRedis,test
# 분산 큐 활성화
seimi.crawler.enable-redisson-queue=true
# BloomFilter의 예상 입력 횟수를 사용자가 정의, 설정하지 않으면 기본값 사용
# seimi.crawler.bloom-filter-expected-insertions=
# BloomFilter의 예상 오류율을 사용자가 정의, 0.001은 1000개 중 1개의 오류를 허용함. 설정하지 않으면 기본값(0.001) 사용
# seimi.crawler.bloom-filter-false-probability=
seimi-app.xml에서 redisson을 설정. 2.0 버전부터 기본 분산 큐는 redisson으로 변경되었으므로, 스프링 설정 파일에서 redissonClient 구현체를 주입해야 합니다. 이제 분산 큐를 정상적으로 사용할 수 있습니다.
<redisson:client
id="redisson"
name="test_redisson"
>
이 name 속성과 qualifier 자식 요소는 동시에 사용할 수 없습니다.
id와 name 속성은 둘 다 qualifier의 값으로 사용될 수 있습니다.
-->
<redisson:single-server
idle-connection-timeout="10000"
ping-timeout="1000"
connect-timeout="10000"
timeout="3000"
retry-attempts="3"
retry-interval="1500"
reconnection-timeout="3000"
failed-attempts="3"
subscriptions-per-connection="5"
client-name="none"
address="redis://127.0.0.1:6379"
subscription-connection-minimum-idle-size="1"
subscription-connection-pool-size="50"
connection-minimum-idle-size="10"
connection-pool-size="64"
database="0"
dns-monitoring="false"
dns-monitoring-interval="5000"
/>
</redisson:client>
SeimiConfig를 구성하여 Redis 클러스터의 기본 정보를 설정하면 됩니다. 예를 들어:
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
일반적으로, SeimiCrawler가 제공하는 두 가지 구현은 대부분의 사용 사례를 충분히 다루기에 충분하지만, 만약 다루지 못하는 경우가 있다면, 직접 SeimiQueue를 구현하고 사용하도록 할 수도 있습니다. 직접 구현할 때 주의해야 할 사항은 다음과 같습니다:
@Queue어노테이션을 붙여, Seimi가 이 어노테이션을 붙인 클래스가 SeimiQueue일 가능성을 알리는 것입니다 (SeimiQueue가 되기 위해서는 다른 조건을 만족해야 합니다).SeimiQueue인터페이스를 구현해야 합니다. 예시는 다음과 같습니다:
/**
* 시스템 큐의 기본 인터페이스를 정의합니다. 자유롭게 구현할 수 있으며, 규격에 맞게 하면 됩니다.
* @author 汪浩淼 [email protected]
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* 요청을 차단 모드로 큐에서 하나 제거합니다.
* @param crawlerName --
* @return --
*/
Request bPop(String crawlerName);
/**
* 요청을 큐에 추가합니다.
* @param req 요청
* @return --
*/
boolean push(Request req);
/**
* 작업 큐의 남은 길이를 반환합니다.
* @param crawlerName --
* @return num
*/
long len(String crawlerName);
/**
* 지정된 URL이 이미 처리되었는지 판단합니다.
* @param req --
* @return --
*/
boolean isProcessed(Request req);
/**
* 처리된 요청을 기록합니다.
* @param req --
*/
void addProcessed(Request req);
/**
* 현재까지의 총 수집 수를 반환합니다.
* @param crawlerName --
* @return num
*/
long totalCrawled(String crawlerName);
/**
* 수집 기록을 초기화합니다.
* @param crawlerName --
*/
void clearRecord(String crawlerName);
}
- 모든 SeimiQueue는
queues패키지 하위에 위치해야 합니다, 예를 들어cn.wanghaomiao.xxx.queues와 같이. demo 프로젝트에도 예제가 있습니다. 위의 요구 사항을 만족시키고, 자신의 SeimiQueue를 작성한 후,@Crawler(name = "xx", queue = YourSelfRedisQueueImpl.class)어노테이션을 통해 사용하도록 설정할 수 있습니다.
demo 프로젝트의 DefaultRedisQueueEG (GitHub 직접 링크)를 참고하십시오.
SeimiCrawler는 spring을 사용하여 bean을 관리하고 의존성을 주입하기 때문에, Mybatis, Hibernate, Paoding-jade 등의 주요 데이터 지속화 방안을 쉽게 통합할 수 있습니다. 여기서는 Mybatis를 사용합니다.
Mybatis와 데이터베이스 연결 관련 의존성을 추가합니다:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>seimi-mybatis.xml이라는 XML 구성 파일 추가(구성 파일은 모두 seimi로 시작하도록 기억하셨죠?)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>데모 프로젝트에는 seimi.properties라는 일관된 구성 파일이 존재하므로, 데이터베이스 연결 관련 정보도 properties 파일을 통해 주입됩니다. 물론 여기에 직접 작성할 수도 있습니다. properties 구성은 다음과 같습니다:
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
이제 프로젝트 준비는 완료되었습니다. 실험 정보를 저장할 데이터베이스와 테이블을 생성해야 합니다. 데모 프로젝트는 테이블 구조를 제공하며, 데이터베이스 이름은 자유롭게 조정할 수 있습니다:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Mybatis의 DAO 파일을 생성합니다:
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
Mybatis의 구성에 대한 내용은 모두 알고 있을 것으로 생각되며, 자세한 내용은 데모 프로젝트를 참조하거나 Mybatis 공식 문서를 참조하시기 바랍니다.
적용 가능한 Crawler에 직접 주입하면 됩니다. 예:
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}", blog, response.getUrl());
// paoding-jade를 사용하여 DB에 저장
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success,blogId = {},changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
업무가 복잡한 경우에는 서비스 레이어를 추가로 캡슐화하고, 이를 Crawler에 주입하는 것이 좋습니다.
업무량과 데이터량이 일정 수준에 도달하면, 성능 향상을 위해 여러 대의 서버로 수평적으로 확장하여 클러스터 서비스를 구축해야 합니다. 이는 SeimiCrawler가 설계 단계에서 고려한 문제입니다. 따라서 SeimiCrawler는 원래부터 분산 배포를 지원합니다. 위에서 소개한 SeimiQueue에 대해 생각해보면, 분산 배포 방법을 쉽게 이해할 수 있을 것입니다. SeimiCrawler는 분산 배포를 위해 DefaultRedisQueue를 기본 SeimiQueue로 사용하고, 배포할 각 서버에서 동일한 Redis 연결 정보를 구성해야 합니다. 구체적인 방법은 위에서 already 설명했으므로 자세한 설명은 생략합니다. DefaultRedisQueue를 사용하면, worker 서버에서는 new Seimi().startWorkers()를 통해 seimi의 처리기 초기화를 수행할 수 있습니다. Seimi의 worker 프로세스는 메시지 큐를 감시하며, 주 서비스에서 크롤링 요청을 보낼 때, 클러스터는 메시지 큐를 통해 통신하여 협력하여 작업을 수행합니다. 2.0 버전부터 기본 분산 큐는 Redisson을 사용하도록 변경되었으며, BloomFilter가 도입되었습니다.
SeimiCrawler에 사용자 정의 크롤링 요청을 보낼 경우, request에 다음과 같은 매개변수를 포함해야 합니다.
url: 크롤링할 URLcrawlerName: 규칙 이름callBack: 콜백 함수
완전히 SpringBoot 프로젝트를 구축하고, 해당 요구사항을 처리하기 위한 Spring MVC 컨트롤러를 작성할 수 있습니다. 여기에 간단한 DEMO가 있으며, 이 기반 위에서 더 멋지고 흥미로운 작업을 수행할 수 있습니다.
SpringBoot 프로젝트 형태로 실행하지 않고자 하는 경우, 내장 인터페이스를 사용할 수 있습니다. SeimiCrawler는 특정 포트를 지정하여 내장 http 서비스를 시작할 수 있으며, 이 서비스는 http API를 통해 크롤링 요청을 받아 처리하거나 해당 Crawler의 크롤링 상태를 확인할 수 있습니다.
http 인터페이스를 통해 SeimiCrawler에 JSON 형식의 Request 요청을 보내면, http 인터페이스는 크롤링 요청을 기본 검증 후에 문제 없으면 해당 요청을 처리 규칙에 따라 처리합니다.
- 요청 URL: http://host:port/push/${YourCrawlerName}
- 호출 방식: GET/POST
- 입력 매개변수:
| 파라미터 이름 | 필수 여부 | 파라미터 타입 | 파라미터 설명 |
|---|---|---|---|
| req | true | str | 내용은 Request 요청의 JSON 형식, 단일 또는 JSON 배열 |
- 파라미터 구조 예시:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
혹은
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
구조 필드 설명:
| Json 필드 | 필수 여부 | 필드 유형 | 필드 설명 |
|---|---|---|---|
| url | true | str | 요청 대상 주소 |
| callBack | true | str | 대응 요청 결과의 콜백 함수 |
| meta | false | map | 선택적으로 다음 컨텍스트에 전달할 일부 사용자 정의 데이터 |
| params | false | map | 현재 요청에 필요한 요청 매개변수 |
| stop | false | bool | true인 경우, 해당 요청을 수신한 작업 스레드가 작업을 중단합니다. |
| maxReqCount | false | int | 요청 처리가 예외적으로 실패한 경우 재처리할 수 있는 최대 횟수 |
요청 주소: /status/${YourCrawlerName}로 지정 크롤러의 현재 크롤링 상태에 대한 기본 정보를 확인할 수 있으며, 데이터 형식은 JSON입니다.
참고: 5.2.13.동적 프록시 설정
- 서로 다른 SeimiCrawler 인스턴스에서 동일한 이름의 크롤러는 동일한 redis를 통해 협력적으로 작동합니다 (동일한 생산 소비자 대열 공유)
- SeimiCrawler가 시작되는 머신과 redis 사이의 연결이 제대로 이루어져 있어야 합니다. 반드시 보장해야 합니다.
- 데모에서 redis 비밀번호를 설정했지만, redis에서 비밀번호를 요구하지 않는다면 설정할 필요가 없습니다.
- 또한 많은 사용자가 네트워크 오류를 겪는 경우, 이는 네트워크 상태를 확인해야 함을 의미합니다. SeimiCrawler는 성숙한 네트워크 라이브러리를 사용하므로, 네트워크 오류가 발생한다면 실제로 네트워크에 문제가 있는 것입니다. 이를 포함하여, 대상 사이트에 의한 차단 여부, 프록시 연결 여부, 프록시 차단 여부, 프록시의 인터넷 연결 능력, 머신의 인터넷 연결 상태 등을 확인해야 합니다.
public List<Request> startRequests()를 재구현하여 복잡한 초기 요청을 자유롭게 정의할 수 있습니다. 이 경우 public String[] startUrls()는 null을 반환할 수 있습니다. 예시로는 다음과 같습니다:
@Crawler(name = "usecookie", useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login", "start");
Map<String, String> params = new HashMap<>();
params.put("email", "[email protected]");
params.put("pwd", "xxxxxxxxxxxxxxxxxxx");
params.put("save_login", "1");
params.put("verifyCode", "");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog", "minePage"));
}
public void minePage(Response response) {
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"), ""));
logger.info("httpType:{}", response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(), e);
}
}
}
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
사용 중인 버전이 2.1.2 또는 그 이후 버전인지 확인하세요. Request에서 jsonBody 속성을 설정하여 JSON 본문 요청을 보낼 수 있습니다.
문제나 제안 사항이 있는 경우 아래의 메일링 목록을 통해 토론할 수 있습니다. 최초 발언 전에는 구독 후 승인을 받아야 합니다(광고 등 스팸을 차단하기 위해, 좋은 토론 환경을 제공하기 위함입니다).
- 구독:
[email protected]으로 이메일을 보내세요 - 발언:
[email protected]으로 이메일을 보내세요 - 구독 해지:
[email protected]으로 이메일을 보내세요
BTW: Github에서
star를 해주시면 감사하겠습니다 ^_^