Ein agiler, mächtiger, eigenständiger, verteilter Crawler-Framework.
Das Ziel von SeimiCrawler ist es, das einfachste und praktischste Crawler-Framework in der Java-Welt zu werden.
SeimiCrawler ist ein agiles, eigenständig ausführbares, verteilbares Java-Crawler-Framework, das darauf abzielt, den Einstieg für Anfänger in die Entwicklung eines nutzbar und leistungsfähigen Crawler-Systems zu vereinfachen und die Entwicklungseffizienz zu erhöhen. In der Welt von SeimiCrawler müssen die meisten Benutzer sich hauptsächlich auf die Implementierung der Geschäftslogik für das Crawling konzentrieren, während Seimi den Rest overnimmt. Das Design von SeimiCrawler wurde von der Python-Crawler-Framework Scrapy inspiriert, berücksichtigt jedoch auch die Eigenschaften der Java-Sprache und von Spring und ermöglicht eine einfache und weit verbreitete Verwendung von XPath zur HTML-Analyse in China. Daher ist der standardmäßige HTML-Parser von SeimiCrawler JsoupXpath (ein unabhängiges Erweiterungsprojekt, kein Bestandteil von Jsoup). Standardmäßig werden alle HTML-Daten mit XPath extrahiert (natürlich können auch andere Parser zur Datenverarbeitung gewählt werden). In Kombination mit SeimiAgent wird das Problem der komplexen dynamischen Seitenranderung vollständig und elegant gelöst. Es unterstützt SpringBoot vollständig und ermöglicht es Ihnen, Ihre Kreativität und Fantasie aufs äußerste auszuschöpfen.
JDK1.8+
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>Sehen Sie sich die neueste Version auf Github an</version>
</dependency>
Github Versionen Maven Versionen
Erstellen Sie ein Standard-SpringBoot-Projekt und fügen Sie Crawler-Regeln im Paket crawlers hinzu, zum Beispiel:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Zwei URLS zur Überprüfung der Duplikate
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// Implementieren Sie hier weitere Aktionen
} catch (Exception e) {
e.printStackTrace();
}
}
}
Konfigurieren Sie application.properties:
# Starten Sie SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=basic
Starten Sie das Standard-SpringBoot-Projekt.
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}Für komplexere Anwendungen können Sie die detailliertere Dokumentation unten oder das Demo auf GitHub konsultieren.
Erstellen Sie ein normales Maven-Projekt und fügen Sie die Crawler-Regeln im Paket crawlers hinzu, zum Beispiel:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Zwei URLs dienen der Testung der Redundanz
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// tun Sie etwas
} catch (Exception e) {
e.printStackTrace();
}
}
}Fügen Sie dann eine main-Methode in einem beliebigen Paket hinzu, um SeimiCrawler zu starten:
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}Das ist der Entwicklungsprozess eines grundlegenden Crawler-Systems.
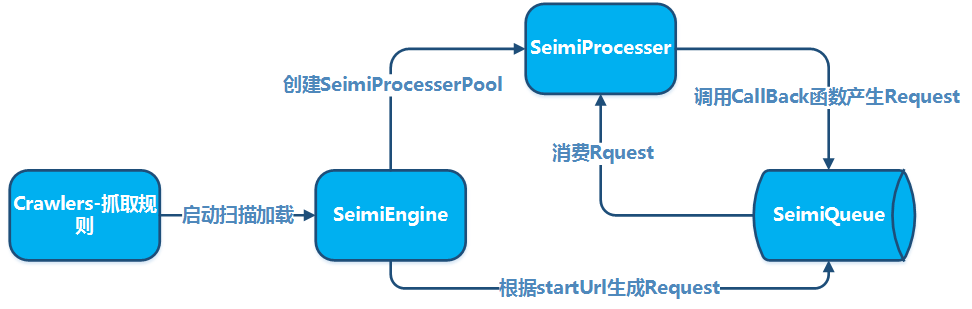
Die Konventionen sind wichtig, um die Quellcode-Struktur der mithilfe von SeimiCrawler entwickelten Crawler-Systeme strukturierter und lesbarer zu gestalten. Wenn alle Teammitglieder eine gemeinsame Konvention einhalten, wird der Code der Projekte im Team leichter zu lesen und zu ändern. Es soll vermieden werden, dass jemand eine Geschäftskomponente entwickelt und ein anderes Teammitglied Schwierigkeiten hat, die Klassen zu finden. Wir wollen leistungsfähig, einfach und benutzerfreundlich sein. Schließlich bedeutet das Vorhandensein von Konventionen nicht, dass SeimiCrawler nicht flexibel ist.
- Da der Kontext von SeimiCrawler auf Spring basiert, unterstützt er fast alle Spring-konformen Konfigurationsdateien und die übliche Verwendung von Spring. SeimiCrawler scannen alle XML-Format-Konfigurationsdateien im Projektklasspfad, aber nur XML-Konfigurationsdateien, die mit
seimibeginnen, werden von SeimiCrawler erkannt und geladen. - SeimiCrawler verwendet slf4j für die Protokollierung, Sie können die spezifische Implementierung selbst konfigurieren.
- Die bei der Entwicklung von Seimi zu beachtenden Konventionen werden in den folgenden Entwicklungsrichtlinien detailliert erläutert.
Die Crawler-Regelklasse ist der wichtigste Teil bei der Entwicklung von Crawford mit SeimiCrawler, die Basic-Klasse im Schnellstart ist ein grundlegender Crawler. Beim Schreiben eines Crawler sollten folgende Punkte beachtet werden:
- Es muss die Klasse
BaseSeimiCrawlererben - Es muss mit dem
@Crawler-Anmerkungszeichen versehen werden. Dasname-Attribut der Anmerkung ist optional. Wenn es gesetzt wird, wird dieser Crawler mit dem von Ihnen definierten Namen benannt, andernfalls wird der Standard-Klassenname verwendet. - Alle Crawler, die von SeimiCrawler gescannt werden sollen, müssen sich im crawlers-Paket befinden, wie z.B.
cn.wanghaomiao.xxx.crawlers. Sie können auch das mit dem Projekt bereitgestellte Demo-Projekt als Referenz verwenden. Nach der Initialisierung des Crawlers müssen Sie zwei grundlegende Methoden implementieren:public String[] startUrls();undpublic void start(Response response). Nach der Implementierung dieser beiden Methoden ist ein einfacher Crawler fertig.
Derzeit hat das @Crawler-Anmerkungszeichen die folgenden Eigenschaften:
nameEin benutzerdefinierter Name für die Crawler-Regel. In einem von SeimiCrawler scannbaren Projekt darf es keine doppelten Namen geben. Standardmäßig wird der Klassenname verwendet.proxyTeilt Seimi mit, ob der Crawler ein Proxy verwendet und welchen. Derzeit werden drei Formate unterstützt:http|https|socket://host:port. In dieser Version wird ein Proxy mit Benutzernamen und Passwort noch nicht unterstützt.useCookieGibt an, ob Cookies verwendet werden sollen. Wenn aktiviert, kann der Zustand Ihrer Anfragen wie bei einem Browser beibehalten werden, wobei auch eine Verfolgung möglich ist.queueGibt an, welche Datenwarteschlange für den Crawler verwendet werden soll. Standardmäßig wird die lokale WarteschlangeDefaultLocalQueue.classverwendet. Es ist auch möglich, die standardmäßige Redis-Implementierung oder eine eigene Implementierung basierend auf anderen Queuesystemen zu verwenden, was in späteren Abschnitten ausführlicher erläutert wird.delayLegt das Intervall zwischen Anfrage-Abgriffen in Sekunden fest. Standardmäßig ist es 0, dh es gibt kein Intervall.httpTypeTyp der Downloader-Implementierung. Die Standard-Downloader-Implementierung ist Apache Httpclient. Es ist möglich, die Implementierung für Netzwerkanfragen auf OkHttp3 zu ändern.httpTimeOutUnterstützung für benutzerdefinierte Zeitauslauf, in Millisekunden. Der Standardwert beträgt 15000ms.
Dies ist der Einstiegspunkt des Crawlers, dessen Rückgabewert ein Array von URLs ist. Standardmäßig wird die startURL als GET-Anfrage behandelt. Falls Sie in besonderen Situationen möchten, dass Seimi die startURL als POST-Anfrage behandelt, fügen Sie einfach ##post ans Ende der URL an, z.B. http://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post. Diese Spezifikation ist nicht case-sensitiv. Diese Regel gilt nur für die Verarbeitung von startURLs.
Diese Methode ist die Callback-Funktion für die startURL, d.h., sie definiert, wie Seimi die Daten behandelt, die als Antwort auf die Anfrage der startURL zurückgegeben werden.
- Textergebnisse
Seimi empfiehlt standardmäßig die Verwendung von XPath zum Extrahieren von HTML-Daten. Obwohl es am Anfang etwas Lernkurve für XPath gibt, ist der erzielte Entwicklungsüberfluss nach dem Erlernen sehr hoch. Mit
JXDocument doc = response.document();kann dasJXDocument(JsoupXpath-Dokumentobjekt) abgerufen werden. Danach können beliebige Daten durchdoc.sel("xpath")extrahiert werden. In der Regel ist eine einfache XPath-Anweisung ausreichend, um die gewünschten Daten zu extrahieren. Für die Verwendung des XPath-Syntax-Interpreters von Seimi und für weiterführende Informationen zu XPath siehe JsoupXpath. Wenn Sie XPath nicht mögen, können Sie die ursprünglichen Antwortdaten im Response verwenden und einen anderen Datend(Parser verwenden, um die Daten zu verarbeiten. - Dateiresultate
Bei Dateiresultaten können Sie
reponse.saveTo(File targetFile)verwenden, um die Datei zu speichern, oderbyte[] getData()verwenden, um den Datei-Bytestream für andere Operationen zu erhalten.
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* Dies dient hauptsächlich zum Speichern von benutzerdefinierten Daten, die von oben übertragen werden
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* Die tatsächliche Quell-URL des Webseiteninhalts
*/
private String realUrl;
/**
* Der HTTP-Handler-Typ für die Ergebnisse dieser Anfrage
*/
private SeimiHttpType seimiHttpType;
Die Verwendung einer Standard-Callback-Funktion wird Ihre Anforderungen nicht erfüllen. Wenn Sie beispielsweise URLs in der startURL-Seite extrahieren und weitere Anfragen zur Datenabfrage und -verarbeitung durchführen möchten, müssen Sie eine benutzerdefinierte Callback-Funktion erstellen. Beachten Sie folgende Punkte:
- Ab Version 2.0 wird die Methodenreferenz unterstützt, was die Setzung von Callback-Funktionen natürlicher macht, z. B.
Basic::getTitle. - In der Callback-Funktion generierte
Request-Objekte können eine andere Callback-Funktion festlegen oder dieselbe Funktion verwenden. - Eine Callback-Funktion muss das folgende Format aufweisen:
public void callbackName(Response response). Die Methode muss öffentlich sein, einen ParameterResponsehaben und keinen Rückgabewert liefern. - Ein
Request-Objekt kann eine Callback-Funktion durch den Namen alsString-Parameter angeben, z. B.getTitleim Schnellstart. - Crawlers, die
BaseSeimiCrawlererben, können in Callback-Funktionen direkt die Methodepush(Request request)der Basisklasse aufrufen, um neue Abrufforderungen in die Warteschlange zu senden. Request-Objekte können durchRequest.build()erstellt werden.
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta, int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* Die zu anfragende URL
*/
@NotNull
private String url;
/**
* Der zu verwendende HTTP-Methode-Typ: get, post, put, usw.
*/
private HttpMethod httpMethod;
/**
* Wenn die Anfrage Parameter benötigt, werden diese hier gespeichert
*/
private Map<String,String> params;
/**
* Dies dient hauptsächlich zum Speichern von benutzerdefinierten Daten, die an die untergeordneten Callback-Funktionen übertragen werden
*/
private Map<String,Object> meta;
/**
* Der Name der Callback-Funktion
*/
@NotNull
private String callBack;
/**
* Callback-Funktion ist ein Lambda-Ausdruck
*/
private transient boolean lambdaCb = false;
/**
* Callback-Funktion
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* Stoppsignal, Threads die dieses Signal erhalten, werden beendet
*/
private boolean stop = false;
/**
* Maximale Anzahl der erneut auszuführenden Anfragen
*/
private int maxReqCount = 3;
/**
* Dient zur Aufzeichnung der Anzahl der bereits ausgeführten Anfragen
*/
private int currentReqCount = 0;
/**
* Dient zur Bestimmung, ob eine Anfrage durch eine Redundanzfilterung laufen soll
*/
private boolean skipDuplicateFilter = false;
/**
* Gibt an, ob für diese Anfrage SeimiAgent aktiviert werden soll
*/
private boolean useSeimiAgent = false;
/**
* Benutzerdefinierte HTTP-Protokollheader
*/
private Map<String,String> header;
/**
* Definiert die Renderingzeit von SeimiAgent, in Millisekunden
*/
private long seimiAgentRenderTime = 0;
/**
* Dient zur Unterstützung der Ausführung spezifischer JavaScript-Skripte auf SeimiAgent
*/
private String seimiAgentScript;
/**
* Gibt an, ob beim Senden der Anfrage an SeimiAgent Cookies verwendet werden sollen
*/
private Boolean seimiAgentUseCookie;
/**
* Bestimmt, in welchem Format SeimiAgent das Ergebnis zurückgibt, standardmäßig HTML
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* Unterstützung für benutzerdefinierte Cookies
*/
private List<SeimiCookie> seimiCookies;
/**
* Unterstützung für JSON-Anfragebody
*/
private String jsonBody;
}
Der Standard-UA von SeimiCrawler ist SeimiCrawler/JsoupXpath. Wenn Sie einen benutzerdefinierten UserAgent verwenden möchten, können Sie die Methode public String getUserAgent() in der Klasse BaseSeimiCrawler überschreiben. SeimiCrawler ruft den UserAgent bei jeder Anfrage ab, daher können Sie eine eigene UA-Bibliothek implementieren, die bei jeder Anfrage einen zufälligen UserAgent zurückgibt.
Dies wurde bereits in der Einführung des @Crawler-Annotations beschrieben. Hier wird es noch einmal hervorgehoben, um den Überblick über die grundlegenden Funktionen zu erleichtern. Die Aktivierung von Cookies erfolgt über das useCookie-Attribut der @Crawler-Annotation. Außerdem können Sie Cookies und Header manuell über die Methoden Request.setSeimiCookies(List<SeimiCookie> seimiCookies) oder Request.setHeader(Map<String, String> header) festlegen. Mit der Request-Klasse können Sie viele benutzerdefinierte Einstellungen vornehmen, die Ihnen neue Ideen für Ihre Anwendungen einbringen können.
Die Konfiguration erfolgt über das proxy-Attribut der @Crawler-Annotation. Weitere Informationen finden Sie in der Beschreibung der @Crawler-Annotation. Wenn Sie dynamische Proxies verwenden möchten, lesen Sie bitte den Abschnitt "Dynamische Proxies einrichten". Derzeit werden drei Formate unterstützt: http|https|socket://host:port.
Die Konfiguration erfolgt über das delay-Attribut der @Crawler-Annotation. Die Einheit für die Verzögerung zwischen der Durchführung von Anfragen ist die Sekunde, standardmäßig ist dieser Wert 0, was keiner Verzögerung entspricht. Da viele Inhaltsersteller die Anfragefrequenz als Anti-Crawling-Maßnahme einsetzen, empfiehlt es sich, diesen Parameter in den entsprechenden Fällen anzupassen, um eine bessere Extraktionsleistung zu erzielen.
Durch Überschreiben von BaseSeimiCrawler der Methode public String[] allowRules() können Whitelist-Regeln für URL-Anfragen definiert werden. Die Regeln sind Regulär Ausdrücke, und die Übereinstimmung mit einer davon führt zu einer Freigabe der Anfrage.
Durch Überschreiben von BaseSeimiCrawler der Methode public String[] denyRules() können Blacklist-Regeln für URL-Anfragen definiert werden. Die Regeln sind Regulär Ausdrücke, und die Übereinstimmung mit einer davon führt zu einer Blockierung der Anfrage.
Durch Überschreiben von BaseSeimiCrawler der Methode public String proxy() kann Seimi informiert werden, welche Proxy-Adresse für eine bestimmte Anfrage verwendet werden soll. Hier kann man selbst aus einer vorhandenen Proxy-Bibliothek sequenziell oder zufällig eine Proxy-Adresse zurückgeben. Solange die Proxy-Adresse nicht leer ist, wird die Proxy-Einstellung in @Crawler ignoriert. Derzeit werden drei Formate unterstützt: http|https|socket://host:port.
Durch die useUnrepeated-Eigenschaft der @Crawler-Annotation kann gesteuert werden, ob die Systemdoppelgänger-Erkennung aktiviert ist. Standardmäßig ist sie aktiviert.
Derzeit unterstützt SeimiCrawler 301, 302 und meta refresh Weiterleitungen. Für solche Weiterleitungen kann man den Inhalt der zugehörigen Ziel-URL durch die getRealUrl()-Methode des Response-Objekts erhalten.
Wenn bei der Verarbeitung einer Anfrage ein Fehler auftritt, wird sie dreimal in die Warteschlange zurückgelegt, um erneut verarbeitet zu werden. Falls sie letztendlich dennoch fehlschlägt, wird die public void handleErrorRequest(Request request)-Methode des Crawlers aufgerufen, um die fehlerhafte Anfrage zu behandeln. Die Standardimplementierung protokolliert den Fehler, jedoch kann der Entwickler diese Methode überschreiben, um eine eigene Fehlerbehandlung hinzuzufügen.
Dieses Thema sollte intensiver beleuchtet werden. Wer SeimiAgent noch nicht kennt, sollte zuerst die SeimiAgent-Projektseite lesen. Kurz gesagt, ist SeimiAgent ein auf dem Server laufender Browserkern, der auf QtWebkit basiert und über eine Standard-HTTP-Schnittstelle Dienste anbietet. Er ist speziell für die Rendierung komplexer dynamischer Webseiten, das Einfangen von Schnappschüssen und die Überwachung entwickelt. Er verarbeitet die Seiten auf der gleichen Weise wie ein moderner Browser, sodass man von ihm alle Informationen erhalten kann, die in einem Browser verfügbar sind.
Um SeimiCrawler SeimiAgent zu ermöglichen, muss zunächst die Adresse des SeimiAgent-Dienstes angegeben werden.
Durch Konfiguration von SeimiConfig, z. B.
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
In der application.properties konfigurieren
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
Entscheidet, welche Anfragen an SeimiAgent weitergeleitet werden und wie diese von SeimiAgent behandelt werden sollen. Dies erfolgt auf Request-Ebene.
Request.useSeimiAgent()Informiert SeimiCrawler, dass diese Anfrage an SeimiAgent weitergeleitet werden soll.Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)Setzt die Renderzeit für SeimiAgent (nachdem alle Ressourcen geladen sind, wird SeimiAgent so viel Zeit gegeben, um Skripte in den Ressourcen wie JavaScript auszuführen, um die endgültige Seite zu rendern). Die Zeit wird in Millisekunden angegeben.Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)Informiert SeimiAgent, ob Cookies verwendet werden sollen. Wenn hier nichts gesetzt ist, wird die globale Cookie-Einstellung von seimiCrawler verwendet.- Sonstiges Wenn Ihr Crawler einen Proxy verwendet, wird seimiCrawler automatisch sicherstellen, dass SeimiAgent bei der Weiterleitung dieser Anfrage den gleichen Proxy verwendet.
- Demo Für praktische Anwendungen können Sie sich das Demo im Repository ansehen.
Konfigurieren Sie application.properties:
seimi.crawler.enabled=true
# Geben Sie den Namen des Crawlers an, der die Startanfrage initiieren soll
seimi.crawler.names=basic,test
Dann starten Sie die Anwendung mit den standardmäßigen SpringBoot-Startprozeduren:
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
Fügen Sie eine main-Methode hinzu, am besten in einer separaten Startklasse, wie im Demo-Projekt gezeigt. In der main-Methode initialisieren Sie das Seimi-Objekt und können über SeimiConfig bestimmte Parameter konfigurieren, wie z.B. die Redis-Cluster-Informationen für verteilte Warteschlangen oder die Host-Informationen für seimiAgent. SeimiConfig ist optional. Zum Beispiel:
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimi enthält die folgenden Startmethoden:
public void start(String... crawlerNames)Startet einen oder mehrere Crawler zum Ausführen des Crawlings.public void startAll()Startet alle geladenen Crawler.public void startWithHttpd(int port, String... crawlerNames)Startet einen oder mehrere Crawler zum Ausführen des Crawlings und startet einen HTTP-Service auf einem angegebenen Port. Über/push/crawlerNamekönnen Sie eine Crawling-Anfrage an den entsprechenden Crawler senden, wobeireqals Parameter übergeben wird. Es werden POST- und GET-Anfragen unterstützt.public void startWorkers()Initialisiert alle geladenen Crawler und lauscht auf Crawling-Anfragen. Diese Startmethode wird hauptsächlich in verteilten Umgebungen verwendet, um einen oder mehrere Arbeitssysteme zu starten. Eine detailliertere Erklärung zur Verteilung und Unterstützung von verteilten Bereitstellungen folgt später.
Führen Sie im Projekt die folgenden Befehle aus, um das gesamte Projekt zu packen und auszugeben.
Unter Windows ändern Sie zur Vermeidung von Zeichenkodierungsproblemen in der Konsole bitte das Ausgabeformat in der logback-Konfigurationsdatei auf
GBK(Standard:UTF-8).
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
In dem target-Verzeichnis des Projekts wird nun ein Verzeichnis namens seimi erstellt. Dieses Verzeichnis enthält das kompilierte und bereitstellbare Projekt. Führen Sie dann den folgenden Befehl aus, um das Projekt zu starten:
Unter Windows:
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
Unter Linux:
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
Sie können die obigen Schritte in eine Shell-Skriptdatei packen, und Sie können die Verzeichnisstruktur entsprechend Ihren Anforderungen anpassen. Das obige Beispiel bezieht sich auf das Beispielprojekt. Für echte Bereitstellungszenarien können Sie das spezielle Maven-Plugin maven-seimicrawler-plugin von SeimiCrawler verwenden, um das Projekt zu packen und bereitzustellen. Im folgenden Abschnitt „Engineering Deployment“ wird dies ausführlicher erläutert.
Es wird empfohlen, das Projekt mit Spring Boot zu erstellen, da dies Ihnen ermöglicht, von der vorhandenen Spring Boot-Ökosphäre zu profitieren und viele erstaunliche Erweiterungen zu nutzen. Das Packen eines Spring Boot-Projekts erfolgt nach den Standardvorgehensweisen der Spring Boot-Dokumentation.
mvn package
Die obigen Schritte können Sie für die Entwicklung und das Debugging verwenden, und Sie können sie auch als Startmethode in Produktionsumgebungen einsetzen. Für eine bessere Bereitstellung und Verteilung bietet SeimiCrawler jedoch ein spezielles Build-Plugin, mit dem Sie das SeimiCrawler-Projekt packen können. Das gepackte Projekt kann dann direkt verteilt und bereitgestellt werden. Sie müssen nur die folgenden Schritte ausführen:
Fügen Sie das plugin im pom.xml hinzu:
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
Führen Sie dann mvn clean package aus. Das Verzeichnisstruktur des gepackten Projekts sieht wie folgt aus:
.
├── bin # Die dazugehörigen Skripte enthalten detaillierte Startparameter, die hier nicht erneut beschrieben werden
│ ├── run.bat # Startskript für Windows
│ └── run.sh # Startskript für Linux
└── seimi
├── classes # Verzeichnis mit den Geschäftsklassen und Konfigurationsdateien des Crawler-Projekts
└── lib # Verzeichnis mit den Abhängigkeitspaketen des Projekts
Nun können Sie das Paket direkt verteilen und bereitstellen.
Die benutzerdefinierte Timige Ausführung von SeimiCrawler kann direkt mit der Spring-Annotation @Scheduled realisiert werden, ohne weitere Konfigurationen. Dies kann beispielsweise in der Crawler-Regeldatei wie folgt definiert werden:
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("Ich bin ein Timing-Ausführungsplaner, der sich nach einem cron-Ausdruck verhält und alle 5 Sekunden ausgeführt wird");
// Ein Request kann zum festgelegten Zeitpunkt gesendet werden
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
Wenn man einen unabhängigen Service-Klasse definieren möchte, muss sicher gestellt werden, dass diese Klasse gescannt werden kann. Für Details zu @Scheduled können Entwickler das Spring-Dokumentation studying und die Demo-Beispiele von SeimiCrawler auf GitHub zurate ziehen.
Wenn du einen Bean definieren möchtest, kann SeimiCrawler die Daten basierend auf den von dir definierten Regeln automatisch extrahieren und in die entsprechenden Felder einfüllen.
Schauen wir uns ein Beispiel an:
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
// Auch so ist es möglich @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
Die Klasse BlogContent ist das von dir definierte Ziel-Bean. Die Annotation @Xpath muss in die Felder gesetzt werden, in die du Daten einfügen möchtest, und einem XPath-Extraktionsregel zugeordnet werden. Es ist nicht erforderlich, dass die Felder privat oder öffentlich sind, und es ist auch nicht notwendig, Getter- und Setter-Methoden zu haben.
Nachdem das Bean vorbereitet ist, kann in der Rückruffunktion public <T> T render(Class<T> bean) der eingefüllte Bean-Objekt abgerufen werden.
SeimiCrawler unterstützt auch die Hinzufügung von Interceptionen für bestimmte oder alle Rückruffunktionen. Zum Implementieren eines Interceptors beachte folgende Punkte:
- Es muss die Annotation
@Interceptorverwendet werden. - Es muss das
SeimiInterceptor-Interface implementiert werden. - Alle Interceptionen, die gescannt und aktiviert werden sollen, müssen sich im interceptors-Paket befinden, z.B.
cn.wanghaomiao.xxx.interceptors, im Demo-Projekt gibt es auch Beispiele. - Es muss eine benutzerdefinierte Annotation zur Kennzeichnung der zu unterbrechenden Funktionen oder zur Unterbrechung aller Funktionen definiert werden.
Diese Annotation informiert Seimi, dass die markierte Klasse möglicherweise ein Interceptor ist (da ein richtiger Seimi-Interceptor noch den anderen oben genannten Anforderungen entsprechen muss). Sie hat ein Attribut:
everyMethodist standardmäßig false und dient dazu, Seimi mitzuteilen, ob der Interceptor alle Rückruffunktionen unterbrechen soll.
Direkt zum Interface,
public interface SeimiInterceptor {
/**
* Ruft die Annotation ab, die dem Zielmethoden zugeordnet werden soll
* @return Annotation
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* Wenn die Ausführungsreihenfolge mehrerer Interceptor steep gesteuert werden soll, kann diese Methode überschrieben werden
* @return Gewichtung, je höher der Wert, desto weiter außen und desto früher wird der Interceptor ausgelöst
*/
public int getWeight();
/**
* Definiert vor der Ausführung der Zielmethode einige Logik
*/
public void before(Method method, Response response);
/**
* Definiert nach der Ausführung der Zielmethode einige Logik
*/
public void after(Method method, Response response);
}
Die Kommentare erklären bereits alles klar, daher werde ich hier nicht weiter darauf eingehen.
Siehe das Beispiel DemoInterceptor im Demo-Projekt, Direktlink zum GitHub-Repository
SeimiQueue ist der einzige Kanal, den SeimiCrawler für Datenübertragung und Kommunikation zwischen dem System und anderen Systemen verwendet. Die Standardimplementierung von SeimiQueue ist ein threadsicherer blockierender Queue, der lokal ausgeführt wird. SeimiCrawler unterstützt auch eine Redis-basierte SeimiQueue-Implementierung namens DefaultRedisQueue. Natürlich kann man auch eigene SeimiQueue-Implementierungen erstellen, die den Seimi-Konventionen entsprechen. Die zu verwendende Implementierung kann über das queue-Attribut der @Crawler-Annotation angegeben werden.
Crawler-Annotation setzen auf @Crawler(name = "xx", queue = DefaultRedisQueue.class)
Konfiguration in application.properties:
# Starte SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=DefRedis,test
# Aktiviere verteilte Queues
seimi.crawler.enable-redisson-queue=true
# Benutzerdefinierte Bloom-Filter erwartete Einfügungen, nicht gesetzt wird der Standardwert verwendet
#seimi.crawler.bloom-filter-expected-insertions=
# Benutzerdefinierte Bloom-Filter erwartete Fehlerrate, 0.001 entspricht einem Fehler in 1000, nicht gesetzt wird der Standardwert (0.001) verwendet
#seimi.crawler.bloom-filter-false-probability=
Konfigurieren Sie Redisson in seimi-app.xml, da ab Version 2.0 der Standard für verteilte Queues auf Redisson umgestellt wurde. Daher muss redissonClient in der Spring-Konfigurationsdatei implementiert werden. Anschließend kann die verteilte Queue normal verwendet werden.
<redisson:client
id="redisson"
name="test_redisson"
>
Die name-Eigenschaft und das qualifier-Element können nicht gleichzeitig verwendet werden.
Die Werte von id und name können als Alternative für das qualifier-Element verwendet werden.
-->
<redisson:single-server
idle-connection-timeout="10000"
ping-timeout="1000"
connect-timeout="10000"
timeout="3000"
retry-attempts="3"
retry-interval="1500"
reconnection-timeout="3000"
failed-attempts="3"
subscriptions-per-connection="5"
client-name="none"
address="redis://127.0.0.1:6379"
subscription-connection-minimum-idle-size="1"
subscription-connection-pool-size="50"
connection-minimum-idle-size="10"
connection-pool-size="64"
database="0"
dns-monitoring="false"
dns-monitoring-interval="5000"
/>
</redisson:client>
Konfigurieren Sie SeimiConfig und stellen Sie die grundlegenden Informationen zu Redis-Clusters bereit, z.B.:
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
Normalerweise sind die beiden bereitgestellten Implementierungen von SeimiCrawler ausreichend für die meisten Nutzungsszenarien. Sollten diese jedoch nicht ausreichen, können Sie auch eigene SeimiQueue-Implementierungen erstellen und konfigurieren. Hierbei beachten Sie folgende Punkte:
- Die Klasse muss mit dem
@Queue-Annotation versehen sein, um Seimi mitzuteilen, dass die markierte Klasse möglicherweise eine SeimiQueue ist (zusätzlich müssen weitere Bedingungen erfüllt sein). - Die
SeimiQueue-Schnittstelle muss implementiert werden, wie im folgenden Beispiel gezeigt:
/**
* Definiert die grundlegende Schnittstelle für das Systemqueue, die frei implementiert werden kann, solange sie den Standards entspricht.
* @author Wang Haomiao [email protected]
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* Blockierendes Entfernen eines Anliegens aus der Queue
* @param crawlerName --
* @return --
*/
Request bPop(String crawlerName);
/**
* Hinzufügen eines Anliegens zur Queue
* @param req Anliegen
* @return --
*/
boolean push(Request req);
/**
* Anzahl der verbleibenden Anliegen in der Task-Queue
* @param crawlerName --
* @return Anzahl
*/
long len(String crawlerName);
/**
* Prüfen, ob eine URL bereits verarbeitet wurde
* @param req --
* @return --
*/
boolean isProcessed(Request req);
/**
* Verarbeitetes Anliegen aufzeichnen
* @param req --
*/
void addProcessed(Request req);
/**
* Gesamtzahl der bisher durchgeführten Crawls
* @param crawlerName --
* @return Anzahl
*/
long totalCrawled(String crawlerName);
/**
* Crawling-Verlauf löschen
* @param crawlerName --
*/
void clearRecord(String crawlerName);
}
- Alle SeimiQueue-Implementierungen, die von Seimi erkannt und verwendet werden sollen, müssen im Paket
queuesplatziert werden, z.B.cn.wanghaomiao.xxx.queues. Im Demo-Projekt gibt es auch Beispiele. Wenn obige Anforderungen erfüllt sind, können Sie Ihre eigene SeimiQueue mit der Annotation@Crawler(name = "xx", queue = YourSelfRedisQueueImpl.class)konfigurieren und verwenden.
Beziehen Sie sich auf DefaultRedisQueueEG im Demo-Projekt (Direktlink auf GitHub)
Da SeimiCrawler Spring verwendet, um Beans zu verwalten und Abhängigkeiten zu injizieren, ist es einfach, bestehende gängige Persistenzlösungen wie Mybatis, Hibernate, oder Paoding-jade zu integrieren. Hier wird Mybatis genutzt.
Fügen Sie die Abhängigkeiten für Mybatis und die Datenbankverbindung hinzu:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>Fügen Sie eine XML-Konfigurationsdatei seimi-mybatis.xml hinzu (erinnern Sie sich, dass alle Konfigurationsdateien mit seimi beginnen):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>Da in der Demo-Anwendung eine zentrale Konfigurationsdatei seimi.properties vorhanden ist, werden auch die Datenbankverbindungsinformationen über Properties injiziert. Natürlich können Sie diese Informationen auch direkt in die Datei schreiben. Die Properties-Konfiguration lautet wie folgt:
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
Der Projektstand ist nun bereit. Es bleibt Ihnen, eine Datenbank und eine Tabelle zu erstellen, um die Experimentinformationen zu speichern. Die Demo-Anwendung gibt die Tabellestruktur vor, der Datenbankname kann nach Belieben angepasst werden:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Erstellen Sie eine Mybatis-DAO-Datei:
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
Die Mybatis-Konfiguration sollte Ihnen bekannt sein. Mehr dazu finden Sie im Demo-Projekt oder in der offiziellen Mybatis-Dokumentation.
In den entsprechenden Crawler direkt injizieren, z.B.:
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={}, url={}", blog, response.getUrl());
// Speichern in der DB mit paoding-jade
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success, blogId = {}, changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Natürlich, wenn die Anforderungen komplexer sind, empfiehlt es sich, eine zusätzliche Service-Schicht zu kapseln und den Service in den Crawler zu injizieren.
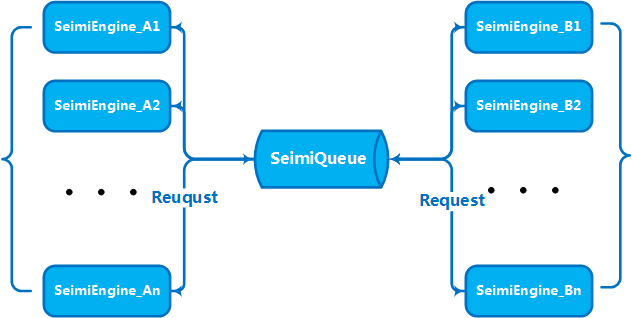
Wenn Ihr Daten- und Geschäftsvolumen einen bestimmten Umfang erreicht haben, müssen Sie vertikal mehrere Maschinen bereitstellen, um Clusterservices zu erstellen, um die Verarbeitungsfähigkeit zu steigern. Dies war bereits bei der Konzeption von SeimiCrawler berücksichtigt. Daher unterstützt SeimiCrawler von Anfang an eine verteilte Bereitstellung. Aus der vorherigen Beschreibung von SeimiQueue wissen Sie wahrscheinlich bereits, wie eine verteilte Bereitstellung durchgeführt wird. Um die verteilte Bereitstellung von SeimiCrawler zu realisieren, müssen Sie DefaultRedisQueue als Standard-SeimiQueue aktivieren und auf jedem zu bereitstellenden Server die gleichen Redis-Verbindungsinformationen konfigurieren. Dies wurde bereits im vorherigen Absatz erläutert, daher gaan wir nicht noch einmal darauf ein. Nach der Aktivierung von DefaultRedisQueue initialisieren Sie die Prozessoren von Seimi auf den Worker-Maschinen durch new Seimi().startWorkers(). Die Worker-Prozesse von Seimi beginnen dann, die Nachrichtenwarteschlange zu beobachten. Wenn der Hauptdienst einen Abrufanforderung sendet, kommunizieren und arbeiten alle Cluster通过/http服务接口操作 ##
Wenn Sie eine benutzerdefinierte Abrufanfrage an SeimiCrawler senden möchten, muss die Request folgende Parameter enthalten:
urlDie zu crawlen URLcrawlerNameDer Name der Crawler-RegelcallBackDie Callback-Funktion
Sie können ein SpringBoot-Projekt erstellen und Ihre eigenen Spring MVC-Controller schreiben, um diese Anforderungen zu bearbeiten. Hier gibt es ein einfaches DEMO, basierend darauf können Sie viele spannende und nützliche Dinge tun.
Wenn Sie nicht das SpringBoot-Projektformat verwenden möchten, können Sie die integrierten APIs verwenden. SeimiCrawler kann durch die Auswahl von Startfunktionen auf einem bestimmten Port einen eingebetteten HTTP-Dienst starten, um HTTP-APIs zu bereitstellen, die Abrufanfragen empfangen oder den Crawler-Status anzeigen.
Ein in JSON-Format formulierte Request-Anfrage an SeimiCrawler über das HTTP-Interface. Nach Empfang und erfolgreicher grundlegender Validierung der Abrufanfrage wird diese zusammen mit den Anfragen, die durch die Verarbeitungsregeln generiert wurden, verarbeitet.
- Anfrage-URL: http://host:port/push/${IhrCrawlerName}
- Anfragemethode: GET/POST
- Eingabeparameter:
| Parametername | Pflichtangabe | Parametertyp | Parameterbeschreibung |
|---|---|---|---|
| req | true | str | Inhalt ist die JSON-Darstellung eines Request-Antrags, einzelner oder JSON-Array |
- Parameterstrukturbeispiel:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
oder
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
Beschreibung der Strukturfelder:
| Json-Feld | Pflichtfeld | Feldtyp | Feldbeschreibung |
|---|---|---|---|
| url | true | str | Anfrageweer |
| callBack | true | str | Rückruffunktion für die Anfrageergebnisse |
| meta | false | map | Optionale benutzerdefinierte Daten, die an den Kontext weitergegeben werden |
| params | false | map | Mögliche Anfrageparameter für die derzeitige Anfrage |
| stop | false | bool | Wenn true, wird der Arbeitsprozess der Arbeitsthreads für diese Anfrage angehalten |
| maxReqCount | false | int | Maximale Anzahl der erlaubten Wiederholungsversuche, falls die Anfrage behandelt wird |
Anfrageadresse: /status/${YourCrawlerName} um den aktuellen Crawler-Status im JSON-Format zu erhalten.
Siehe 5.2.13. Einen dynamischen Proxy einrichten
Siehe 5.2.8. Cookies aktivieren (optional)
- Crawler mit dem gleichen Namen in unterschiedlichen SeimiCrawler-Instanzen arbeiten über den gleichen Redis zusammen (geteilter Produktions- und Verbraucher-Queue).
- Stellen Sie sicher, dass der Rechner, auf dem SeimiCrawler ausgeführt wird, mit Redis korrekt verbunden ist.
- Im Demo ist ein Redis-Passwort konfiguriert. Wenn Ihr Redis kein Passwort erfordert, konfigurieren Sie kein Passwort.
- Viele Benutzer begegnen Netzwerkfehlern. In solchen Fällen sollten die Netzwerkeinstellungen überprüft werden. SeimiCrawler nutzt eine reife Netzwerkbibliothek. Falls Netzwerkfehler auftreten, ist es wahrscheinlich, dass tatsächlich Netzwerkprobleme vorliegen. Dazu gehören, aber sind nicht auf, eine mögliche Blockierung durch das Ziel, die Unverfügbarkeit des Proxies, die Blockierung des Proxies, die Unfähigkeit des Proxies, das Internet zu erreichen, und ob der Computer, auf dem er läuft, das Internet erreichen kann.
Umschreiben der Implementierung von public List<Request> startRequests() ermöglicht die freie Definition komplexer Startanfragen. In diesem Fall kann public String[] startUrls() null zurückgeben. Ein Beispiel dafür ist:
@Crawler(name = "usecookie",useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login","start");
Map<String,String> params = new HashMap<>();
params.put("email","[email protected]");
params.put("pwd","xxxxxxxxxxxxxxxxxxx");
params.put("save_login","1");
params.put("verifyCode","");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog","minePage"));
}
public void minePage(Response response){
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"),""));
logger.info("httpType:{}",response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(),e);
}
}
}
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
Bitte stellen Sie sicher, dass die verwendete Version 2.1.2 oder höher ist, um die Möglichkeit zu haben, das jsonBody-Attribut in Request zu setzen und eine Anfrage mit JSON-Körper durchzuführen.
Alle können jetzt über die folgende Mailingliste ihre Fragen oder Vorschläge diskutieren. Vor dem ersten Beitrag ist eine Anmeldung erforderlich, die genehmigt werden muss (hauptsächlich zur Behinderung von Werbung, um eine angenehme Diskussionsumgebung zu schaffen).
- Anmeldung: Bitte senden Sie eine E-Mail an
[email protected] - Beitrag: Bitte senden Sie eine E-Mail an
[email protected] - Austragen: Bitte senden Sie eine E-Mail an
[email protected]
BTW: Wir freuen uns über ein
starauf Github ^_^