An agile, powerful, standalone, and distributed crawler framework.
The goal of SeimiCrawler is to become the most user-friendly and practical crawler framework in the Java world.
SeimiCrawler is an agile, independently deployable, and distributed Java crawler framework. It aims to significantly lower the barrier for new developers to create a highly available and performant crawler system while also improving the efficiency of developing such systems. In the world of SeimiCrawler, most users only need to focus on writing the business logic for data collection, with the rest handled by Seimi. The design of SeimiCrawler is inspired by Python's Scrapy framework, while also integrating the characteristics of the Java language and Spring. It also aims to facilitate more efficient use of XPath for HTML parsing in a domestic context, so SeimiCrawler uses JsoupXpath (an independent extension project, not part of Jsoup) as the default HTML parser, with all default HTML data extraction performed using XPath (though, of course, other parsers can be chosen for data processing). Combined with SeimiAgent, SeimiCrawler perfectly addresses the issue of rendering complex dynamic pages. It fully supports SpringBoot, allowing for the utmost expression of your imagination and creativity.
JDK1.8+
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>Refer to the latest version on Github</version>
</dependency>
Github Release List Maven Release List
Create a standard SpringBoot project and add crawler rules in the crawlers package, for example:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Two URLs are for testing deduplication
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response) {
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// do something
} catch (Exception e) {
e.printStackTrace();
}
}
}
Configure application.properties:
# Start SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=basic
Standard SpringBoot startup
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
For more complex usage, refer to the more detailed documentation below or check the demo on Github.
Create a regular Maven project and add crawler rules under the package crawlers, for example:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Two are for testing deduplication
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// do something
} catch (Exception e) {
e.printStackTrace();
}
}
}
Then add a main function in any package to start SeimiCrawler:
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}
The above process outlines the simplest spider system development.
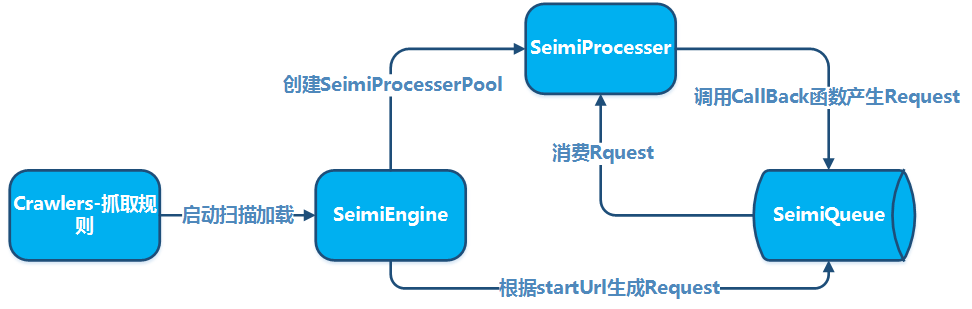
The purpose of having conventions is to make the source code of the spider system developed using SeimiCrawler more standardized and readable. By adhering to a set of conventions, the business project's code will be more readable and modifiable among team members, making it easier for team members to collaborate. We don't want a situation where one person develops a business logic, and another person who takes over can't even find where the classes are located. We want it to be powerful, simple, and easy to use. Finally, having conventions does not mean that SeimiCrawler is not flexible.
- Since SeimiCrawler's context is based on Spring, it supports almost all Spring format configuration files and typical Spring usage. SeimiCrawler will scan all XML configuration files in the classpath of the project, but only XML configuration files with filenames starting with
seimican be recognized and loaded by SeimiCrawler. - SeimiCrawler uses slf4j for logging, and you can configure the specific implementation.
- The conventions to be aware of during Seimi development will be introduced in the development highlights below.
The crawler rule class is the most crucial part of developing a crawler using SeimiCrawler. The Basic class in the quick start guide is a basic crawler class. When writing a crawler, note the following points:
- It must inherit from
BaseSeimiCrawler - It must be annotated with
@Crawler. Thenameattribute in the annotation is optional. If set, the crawler will be named as defined; otherwise, it will default to the class name. - All crawlers that you want to be scanned by SeimiCrawler must be placed in the crawlers package, such as
cn.wanghaomiao.xxx.crawlers. You can also refer to the demo project included in the project.
After initializing the Crawler, you need to implement two basic methods: public String[] startUrls(); and public void start(Response response);. Once these are implemented, a simple crawler is complete.
Currently, the @Crawler annotation has the following properties:
nameCustomizes the name of a crawler rule. There should be no duplicate names within the scope of a SeimiCrawler project. By default, the class name is used.proxyInforms Seimi whether this crawler uses a proxy and what type of proxy to use. Currently, it supports three formats:http|https|socket://host:port. This version does not support proxies with usernames and passwords.useCookieSpecifies whether to enable cookies. Enabling cookies allows you to maintain request state as in a browser, but you can also be tracked.queueSpecifies the data queue to be used by the current crawler. The default is the local queue implementationDefaultLocalQueue.class, but you can also configure it to use the default Redis implementation or implement your own based on other queue systems. This will be discussed in more detail later.delaySets the time interval (in seconds) between request fetches. The default is 0, meaning no delay.httpTypeSpecifies the Downloader implementation type. The default Downloader implementation is Apache Httpclient, but you can switch it to OkHttp3.httpTimeOutSupports customizing the timeout, in milliseconds. The default is 15000ms.
This is the entry point of the crawler, returning an array of URLs. By default, start URLs are processed with a GET request. If, in special cases, you need Seimi to handle your start URL with a POST request, you can append ##post to the URL, for example, http://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post. This specification is case-insensitive and applies only to the processing of start URLs.
This method is the callback function for the start URL, i.e., it tells Seimi how to handle the data returned from the request to the start URL.
- Text Results
Seimi recommends using XPath by default to extract HTML data. Although there is a little learning curve when initially getting to know XPath, compared to the development efficiency it brings after you understand it, this learning cost is negligible.
JXDocument doc = response.document();can obtain theJXDocument(a document object of JsoupXpath), and then you can extract any data you want throughdoc.sel("xpath"). Generally, extracting any data should be achievable with a single XPath statement. Students who wish to learn more about the XPath syntax parser used by Seimi and want to delve deeper into XPath can refer to JsoupXpath. Of course, if you really can't get a feel for XPath, you can use the raw request result data in the response and choose other data parsers for processing. - File Results
If the return result is a file, you can use
response.saveTo(File targetFile)to store it, or get the file byte streambyte[] getData()for other operations.
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* This is mainly used to store some custom data passed from upstream
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* Actual source URL of the web content
*/
private String realUrl;
/**
* HTTP handler type for this request result
*/
private SeimiHttpType seimiHttpType;
Using the default callback function is clearly not sufficient for your needs. If you also want to extract certain URLs from the startURL page and request and process data, you need to define a custom callback function. Points to note:
- Method references are supported starting from version 2.0, making the setting of callback functions more natural, for example:
Basic::getTitle. Requestinstances created in the callback function can specify other callback functions or themselves as the callback function.- The callback function must meet the format:
public void callbackName(Response response), meaning the method must be public, have one and only one parameterResponse, and have no return value. - Setting a callback function for a
Requestrequires only providing the name of the callback function as aString, for example: thegetTitlein the quick start guide. - Crawlers that inherit from
BaseSeimiCrawlercan call the parent class'spush(Request request)directly in the callback function to send new fetch requests to the request queue. Requestcan be created usingRequest.build().
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta, int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* The URL to request
*/
@NotNull
private String url;
/**
* Request method type, get, post, put, etc.
*/
private HttpMethod httpMethod;
/**
* If the request requires parameters, place them here
*/
private Map<String, String> params;
/**
* This is mainly used to store some custom data to be passed to the next level callback function
*/
private Map<String, Object> meta;
/**
* Callback function method name
*/
@NotNull
private String callBack;
/**
* Whether the callback function is a Lambda expression
*/
private transient boolean lambdaCb = false;
/**
* Callback function
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* A signal to stop, the processing thread will exit upon receiving this signal
*/
private boolean stop = false;
/**
* Maximum number of retries allowed
*/
private int maxReqCount = 3;
/**
* Used to record the number of times the current request has been executed
*/
private int currentReqCount = 0;
/**
* Specifies whether a request should bypass the duplicate filtering mechanism
*/
private boolean skipDuplicateFilter = false;
/**
* Whether to enable SeimiAgent for this request
*/
private boolean useSeimiAgent = false;
/**
* Custom HTTP request headers
*/
private Map<String,String> header;
/**
* Defines the rendering time for SeimiAgent, in milliseconds
*/
private long seimiAgentRenderTime = 0;
/**
* Used to support the execution of specified JavaScript scripts on SeimiAgent
*/
private String seimiAgentScript;
/**
* Specifies whether the request submitted to SeimiAgent should use cookies
*/
private Boolean seimiAgentUseCookie;
/**
* Tells SeimiAgent in what format to return the rendered result, default is HTML
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* Supports adding custom cookies
*/
private List<SeimiCookie> seimiCookies;
/**
* Adds support for JSON request body
*/
private String jsonBody;
}
The default UA for SeimiCrawler is SeimiCrawler/JsoupXpath. If you want to customize the UserAgent, you can override the public String getUserAgent() method in BaseSeimiCrawler. SeimiCrawler fetches the UserAgent for each request, so if you want to mask the UserAgent, you can implement a UA library that randomly returns one.
As introduced when discussing the @Crawler annotation, here it is emphasized again for quick reference to these basic functions. Whether to enable cookies is configured through the useCookie attribute in the @Crawler annotation. Additionally, cookies can be custom set using Request.setSeimiCookies(List<SeimiCookie> seimiCookies) or Request.setHeader(Map<String, String> header). The Request object can handle many customizations, so it's worth exploring to get more familiar with it and potentially spark new ideas.
This is configured through the proxy attribute in the @Crawler annotation. For more details, refer to the introduction of @Crawler. If you wish to dynamically specify a proxy, see the section "Setting Dynamic Proxies". Currently, three formats are supported: http|https|socket://host:port.
This is configured through the delay attribute in the @Crawler annotation, setting the interval between request fetches in seconds, with the default being 0 (no interval). In many cases, content providers use request frequency limits as an anti-scraping measure, so you can adjust and add this parameter to achieve better scraping results when necessary.
Set the URL request whitelist rules by overriding public String[] allowRules() of BaseSeimiCrawler. The rules are regular expressions, and matching any one of them will allow the request to proceed.
Set the URL request blacklist rules by overriding public String[] denyRules() of BaseSeimiCrawler. The rules are regular expressions, and matching any one of them will block the request.
Tell Seimi which proxy address to use for a certain request by overriding public String proxy() of BaseSeimiCrawler. You can return a proxy address from your existing proxy pool in sequence or randomly. As long as this proxy address is not empty, the proxy attribute set in @Crawler will be ignored. Currently, three formats are supported: http|https|socket://host:port.
Control whether to enable system deduplication through the useUnrepeated attribute in the @Crawler annotation. It is enabled by default.
Currently, SeimiCrawler supports 301, 302, and meta refresh redirects. For such redirect URLs, you can get the actual redirected or redirected URL through the getRealUrl() method of the Response object.
If a request encounters an exception during processing, it will have three chances to be returned to the processing queue for reprocessing. However, if it still fails, the system will call the crawler's public void handleErrorRequest(Request request) method to handle the problematic request. By default, the implementation logs the error, but developers can override this method to add their own handling logic.
A special mention is necessary here. For those who are not yet familiar with SeimiAgent, you can first check out the SeimiAgent project homepage. In short, SeimiAgent is a browser engine running on the server side, developed based on QtWebkit, and providing services through standard HTTP interfaces. It is specifically designed to handle the rendering, snapshot capturing, and monitoring of complex dynamic web pages. In essence, its processing of pages is at the level of a standard browser, allowing you to retrieve any information that can be obtained from a browser.
To enable SeimiCrawler to support SeimiAgent, you must first inform it of the SeimiAgent service address.
Configure through SeimiConfig, for example:
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
Configure in application.properties
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
Decide which requests to submit to SeimiAgent for processing and specify how SeimiAgent should handle them. This is at the Request level.
Request.useSeimiAgent()Tell SeimiCrawler to submit this request to SeimiAgent.Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)Set the rendering time for SeimiAgent (after all resources are loaded, the amount of time SeimiAgent is given to execute JavaScript and other scripts in the resources to render the final page), the time unit is milliseconds.Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)Tell SeimiAgent whether to use cookies; if this is not set, it will use the global cookie settings of seimiCrawler.- Others If your Crawler has a proxy set, seimiCrawler will automatically let SeimiAgent use this proxy when forwarding this request to SeimiAgent.
- Demo For practical use, you can refer to the demo in the repository
Configure in application.properties
seimi.crawler.enabled=true
# Specify the name of the crawler to which the start request should be initiated
seimi.crawler.names=basic,test
Then start as a standard SpringBoot application:
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
Add a main function, preferably in a separate startup class, similar to the demo project. In the main function, initialize the Seimi object, and you can configure specific parameters through SeimiConfig, such as Redis cluster information for a distributed queue, or host information for seimiAgent if used. Of course, SeimiConfig is optional. For example:
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimi includes the following startup methods:
public void start(String... crawlerNames)Start one or more Crawlers to execute the crawl.public void startAll()Start all Crawlers that have been loaded.public void startWithHttpd(int port, String... crawlerNames)Start one Crawler to execute the crawl and start an HTTP service on a specified port. You can push a crawl request to the corresponding Crawler via/push/crawlerName, with the parameterreq, supporting both POST and GET methods.public void startWorkers()Only initialize all Crawlers that have been loaded and listen for crawl requests. This startup method is primarily used to start one or more pure worker systems in a distributed deployment scenario, which will be introduced in more detail later regarding distributed deployment support and methods.
Execute the following command under the project to package and output the entire project,
To avoid garbled log output in the Windows console, please modify the console output format in the logback configuration file to
GBK, default isUTF-8.
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
At this point, there will be a directory called seimi in the target directory of the project, which is the final compiled and deployable project. Then execute the following command to start it,
For Windows:
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
For Linux:
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
The above can be written into a script, and the directory can be adjusted according to your own situation. The above is just an example for a demo project. For real deployment scenarios, the dedicated packaging tool maven-seimicrawler-plugin for SeimiCrawler can be used for packaging and deployment. The following section "Engineering Packaging Deployment" will provide a detailed introduction.
It is recommended to use Spring Boot to build the project, which can leverage the existing Spring Boot ecosystem to expand many unexpected functionalities. For packaging a Spring Boot project, refer to the standard packaging methods on the Spring Boot official website.
mvn package
The method introduced above can be convenient for development or debugging, and can also be used as a way to start in production environments. However, to facilitate engineering deployment and distribution, SeimiCrawler provides a dedicated packaging plugin to package SeimiCrawler projects. The packaged files can be directly distributed and deployed. You only need to do the following few things:
Add the plugin to the pom
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
Execute mvn clean package, and the directory structure of the packaged files will be as follows:
.
├── bin # The corresponding scripts also include detailed parameter explanations for starting, which will not be repeated here
│ ├── run.bat # Windows startup script
│ └── run.sh # Linux startup script
└── seimi
├── classes # Directory for the Crawler project business classes and related configuration files
└── lib # Directory for the project dependency packages
Now it can be directly used for distribution and deployment.
The custom scheduling in SeimiCrawler can be directly achieved using Spring's @Scheduled annotation without any additional configuration. For instance, you can define it directly in the Crawler rule file as follows:
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("I am a scheduler that executes based on a cron expression, every 5 seconds");
// You can periodically send a Request
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
If you prefer to define it in a separate service class, ensure that the service class can be scanned. For details about @Scheduled, developers can refer to Spring documentation to understand its parameter details, or they can refer to the Demo examples of SeimiCrawler on GitHub.
If you want to define a Bean and have SeimiCrawler automatically extract data based on your defined rules and fill the corresponding fields, you would need this feature.
Let's look at an example:
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
// Alternatively, you can write it as @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
The class BlogContent is a target Bean you have defined. The @Xpath annotation should be placed on the fields where you want to inject data, and you should configure an XPath extraction rule for it. The fields can be either private or public, and there is no requirement for the existence of getters and setters.
After preparing the Bean, you can use the Response built-in function public <T> T render(Class<T> bean) in the callback function to obtain a Bean object with the data filled in.
SeimiCrawler also supports adding interceptors to specific or all callback functions. To implement an interceptor, note the following points:
- It must be annotated with
@Interceptor. - It must implement the
SeimiInterceptorinterface. - All interceptors that need to be scanned should be placed in the interceptors package, such as
cn.wanghaomiao.xxx.interceptors, and there are examples in the demo project. - A custom annotation should be defined to mark which functions need to be intercepted or to intercept all functions.
This annotation tells Seimi that the annotated class might be an interceptor (since a real Seimi interceptor also needs to comply with the other conventions mentioned above). It has one attribute:
everyMethoddefaults to false, indicating whether this interceptor should intercept all callback functions.
Directly to the interface,
public interface SeimiInterceptor {
/**
* Get the annotation that the target method should be marked with
* @return Annotation
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* This method can be overridden when it is necessary to control the order of execution of multiple interceptors
* @return Weight, the greater the weight, the more outer layer it is, and the higher the priority to intercept
*/
public int getWeight();
/**
* Define some processing logic before the target method is executed
*/
public void before(Method method, Response response);
/**
* Define some processing logic after the target method is executed
*/
public void after(Method method, Response response);
}
The comments have explained it clearly, so I won't go into more detail here.
Refer to DemoInterceptor in the demo project, GitHub link
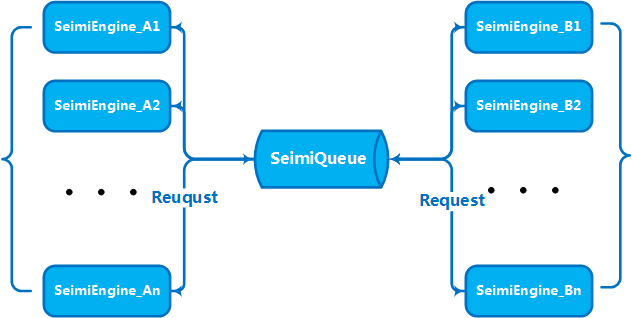
SeimiQueue is the only channel for SeimiCrawler to transfer data and communicate between the system internally and between systems. By default, SeimiQueue is implemented using a thread-safe blocking queue based on the local system. SeimiCrawler also supports a DefaultRedisQueue implementation based on Redis, and you can also implement your own SeimiQueue that conforms to Seimi's conventions. The specific implementation used by a Crawler can be specified through the queue attribute in the @Crawler annotation.
Set the Crawler annotation to @Crawler(name = "xx", queue = DefaultRedisQueue.class)
Configure in application.properties
# Enable SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=DefRedis,test
# Enable distributed queue
seimi.crawler.enable-redisson-queue=true
# Customize the expected insertions for bloomFilter, if not set, the default value will be used
# seimi.crawler.bloom-filter-expected-insertions=
# Customize the expected false positive rate for bloomFilter, 0.001 means one misjudgment is allowed for every 1000 items. If not set, the default value (0.001) will be used
# seimi.crawler.bloom-filter-false-probability=
Configure Redisson in seimi-app.xml. Since version 2.0, the default distributed queue implementation has been changed to Redisson, so the RedissonClient implementation needs to be injected into the Spring configuration file. After that, you can use the distributed queue normally.
<redisson:client
id="redisson"
name="test_redisson"
>
The name attribute and qualifier sub-element cannot be used simultaneously.
Both id and name attributes can be used as alternative values for qualifier.
-->
<redisson:single-server
idle-connection-timeout="10000"
ping-timeout="1000"
connect-timeout="10000"
timeout="3000"
retry-attempts="3"
retry-interval="1500"
reconnection-timeout="3000"
failed-attempts="3"
subscriptions-per-connection="5"
client-name="none"
address="redis://127.0.0.1:6379"
subscription-connection-minimum-idle-size="1"
subscription-connection-pool-size="50"
connection-minimum-idle-size="10"
connection-pool-size="64"
database="0"
dns-monitoring="false"
dns-monitoring-interval="5000"
/>
</redisson:client>
Configure SeimiConfig, set the basic information of the Redis cluster, for example:
SeimiConfig config = new SeimiConfig(); config.setSeimiAgentHost("127.0.0.1"); config.redisSingleServer().setAddress("redis://127.0.0.1:6379"); Seimi s = new Seimi(config); s.goRun("basic");
In most cases, the two implementations provided by SeimiCrawler are sufficient for most use cases. However, if they do not meet your requirements, you can implement your own SeimiQueue and configure it. Points to note when implementing your own SeimiQueue include:
- Annotate with
@Queueto inform Seimi that the annotated class might be a SeimiQueue (other conditions must also be met to qualify as a SeimiQueue). - Implement the
SeimiQueueinterface as follows:
/**
* Defines the basic interface for the system queue, which can be implemented freely as long as it conforms to the specifications.
* @author Wang Haomiao [email protected]
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* Blocking dequeue of a request
* @param crawlerName --
* @return --
*/
Request bPop(String crawlerName);
/**
* Enqueue a request
* @param req Request
* @return --
*/
boolean push(Request req);
/**
* Remaining length of the task queue
* @param crawlerName --
* @return num
*/
long len(String crawlerName);
/**
* Check if a URL has been processed
* @param req --
* @return --
*/
boolean isProcessed(Request req);
/**
* Record a processed request
* @param req --
*/
void addProcessed(Request req);
/**
* Total number of crawled items so far
* @param crawlerName --
* @return num
*/
long totalCrawled(String crawlerName);
/**
* Clear crawl records
* @param crawlerName --
*/
void clearRecord(String crawlerName);
}
- All SeimiQueues that you want to be scanned and activated must be placed in the queues package, such as
cn.wanghaomiao.xxx.queues. There are examples in the demo project. If the above requirements are met, after writing your own SeimiQueue, you can configure and use it via the annotation@Crawler(name = "xx", queue = YourSelfRedisQueueImpl.class).
Refer to DefaultRedisQueueEG in the demo project (direct GitHub link)
Since SeimiCrawler uses Spring to manage beans and perform dependency injection, it is easy to integrate with mainstream data persistence solutions such as Mybatis, Hibernate, and Paoding-jade. Here, Mybatis is used.
Add Mybatis and database connection-related dependencies:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>Add an XML configuration file seimi-mybatis.xml (remember that configuration files should start with seimi, right?)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>Since there is a unified configuration file seimi.properties in the demo project, the database connection information is also injected through properties. Of course, you can also write them directly in the configuration. The properties configuration is as follows:
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
The project is now ready. The next step is to create a database and a table to store the experimental information. The demo project provides the structure of the table, and you can adjust the database name as needed:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Create a Mybatis DAO file:
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
Everyone should be familiar with Mybatis configuration, so I won't elaborate further. For more details, you can refer to the demo project or the official Mybatis documentation.
Inject directly into the appropriate Crawler, for example:
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}", blog, response.getUrl());
// Use the paoding-jade tool to store to DB
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success,blogId = {},changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Of course, if the business logic is complex, it is recommended to encapsulate an additional layer of service and then inject the service into the Crawler.
When your business volume and data size reach a certain level, you will naturally need to scale horizontally by adding multiple machines to form a cluster service to enhance processing capabilities. This is an issue that was considered at the very beginning of SeimiCrawler's design. Therefore, SeimiCrawler inherently supports distributed deployment. In the previous section, which introduced SeimiQueue, I believe you already know how to deploy it in a distributed manner. To achieve distributed deployment with SeimiCrawler, you need to enable DefaultRedisQueue as the default SeimiQueue and configure the same Redis connection information on each machine to be deployed, as detailed in the earlier text. After enabling DefaultRedisQueue, initialize Seimi's processor on the worker machines using new Seimi().startWorkers(). The Seimi worker processes will then start listening to the message queue. Once the main service issues a crawling request, the entire cluster will begin communicating through the message queue, working together with enthusiasm. Starting from version 2.0, the default distributed queue is implemented using Redisson and BloomFilter is introduced.
If you need to send custom crawling requests to Seimicrawler, the request must include the following parameters:
urlThe address to be crawledcrawlerNameThe rule namecallBackThe callback function
You can build a SpringBoot project and write your own Spring MVC controller to handle such requirements. Here is a simple DEMO, on which you can base more interesting and fun projects.
If you do not want to run it as a SpringBoot project, you can use the built-in interface. SeimiCrawler can be started with a chosen function that specifies a port to begin an embedded HTTP service for receiving crawling requests via HTTP API or checking the status of the corresponding Crawler.
Send a JSON-formatted Request to SeimiCrawler via the HTTP interface. Once the HTTP interface receives the crawling request and performs basic validation without issues, it will handle the request along with the requests generated by the processing rules.
- Request URL: http://host:port/push/${YourCrawlerName}
- Invocation Method: GET/POST
- Input Parameters:
| Parameter Name | Required | Parameter Type | Parameter Description |
|---|---|---|---|
| req | true | str | Content is in the form of a Request request in JSON format, either a single instance or a JSON array |
- Example of Parameter Structure:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
or
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
Field Description of the Structure:
| Json Field | Required | Field Type | Field Description |
|---|---|---|---|
| url | true | str | Request target address |
| callBack | true | str | Callback function for the corresponding request result |
| meta | false | map | Optional custom data to pass to the context |
| params | false | map | Parameters required for the current request |
| stop | false | bool | If true, the working thread that receives this request will stop working |
| maxReqCount | false | int | Maximum number of reprocessing attempts if this request processing fails |
Request Address: /status/${YourCrawlerName} to view the current crawling status of the specified Crawler, data format is Json.
Refer to 5.2.13. Setting Dynamic Proxy
Refer to 5.2.8. Enable Cookies (Optional)
- Crawler instances with the same name in different SeimiCrawler will work collaboratively through the same redis (sharing one production/consumption queue).
- Ensure that the machine where SeimiCrawler is launched can correctly connect to redis, which is absolutely necessary.
- The demo configures a redis password, but if your redis does not require a password, do not configure a password.
- Many users encounter network exceptions, which suggests that you should check your network conditions. SeimiCrawler uses a mature network library, so if network exceptions occur, it is indeed a network issue. This includes checking whether the target site has specifically blocked you, whether the proxy is accessible, whether the proxy has been blocked, whether the proxy has the ability to access the external network, and whether the machine on which it is located can access the external network smoothly, etc.
Rewrite the implementation of public List<Request> startRequests(), where complex initial requests can be defined. In this case, public String[] startUrls() can return null. An example is as follows:
@Crawler(name = "usecookie", useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login", "start");
Map<String, String> params = new HashMap<>();
params.put("email", "[email protected]");
params.put("pwd", "xxxxxxxxxxxxxxxxxxx");
params.put("save_login", "1");
params.put("verifyCode", "");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog", "minePage"));
}
public void minePage(Response response) {
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"), ""));
logger.info("httpType:{}", response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(), e);
}
}
}
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
Please ensure that the version 2.1.2 or higher is used, which supports setting the jsonBody property in Request to make a request with a JSON request body.
If you have any questions or suggestions, you can now discuss them through the following mailing list. Before your first post, you need to subscribe and wait for approval (mainly to filter out advertisements and spam, to create a good discussion environment).
- Subscribe: Send an email to
[email protected] - Post: Send an email to
[email protected] - Unsubscribe: Send an email to
[email protected]
BTW: Welcome to give a
staron GitHub ^_^