| title | shortTitle | category | tag | description | head | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
面试官问我Java中ArrayList和LinkedList的区别,我和他扯了半小时 |
ArrayList和LinkedList的区别 |
|
|
Java程序员进阶之路,小白的零基础Java教程,Java中ArrayList和LinkedList的区别 |
|
ArrayList 实现了 List 接口,继承了 AbstractList 抽象类。
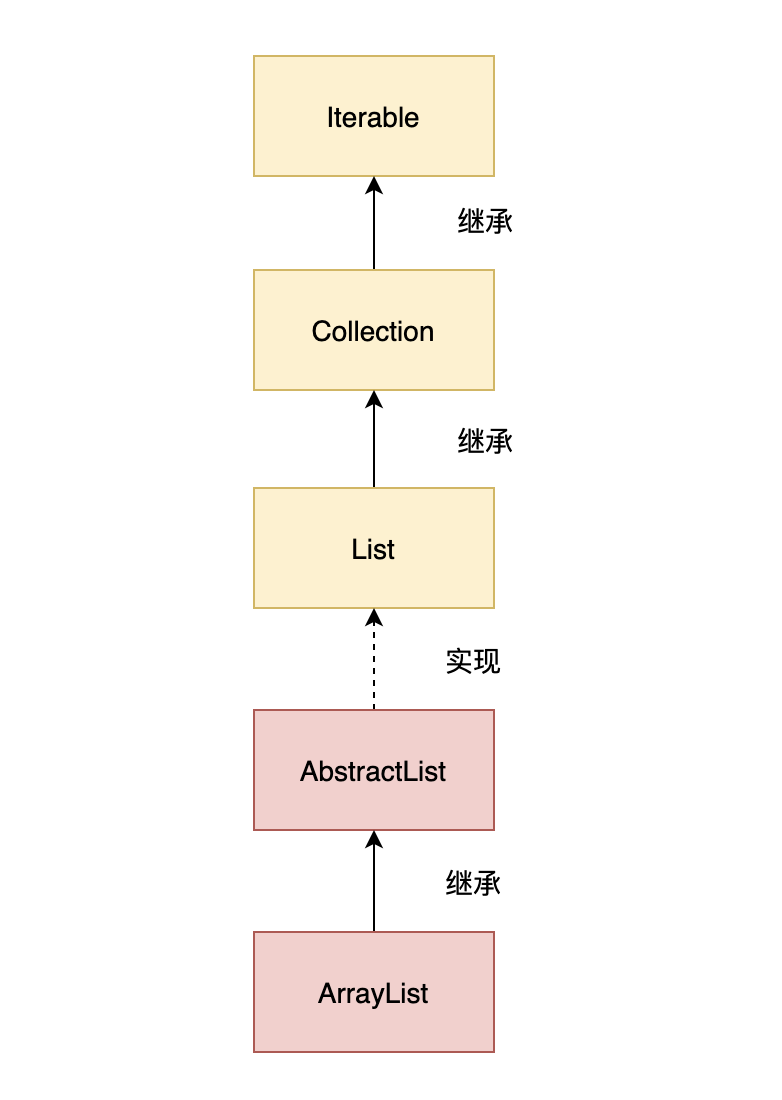
底层是基于数组实现的,并且实现了动态扩容
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData;
private int size;
}ArrayList 还实现了 RandomAccess 接口,这是一个标记接口:
public interface RandomAccess {
}内部是空的,标记“实现了这个接口的类支持快速(通常是固定时间)随机访问”。快速随机访问是什么意思呢?就是说不需要遍历,就可以通过下标(索引)直接访问到内存地址。
public E get(int index) {
Objects.checkIndex(index, size);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}ArrayList 还实现了 Cloneable 接口,这表明 ArrayList 是支持拷贝的。ArrayList 内部的确也重写了 Object 类的 clone() 方法。
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}ArrayList 还实现了 Serializable 接口,同样是一个标记接口:
public interface Serializable {
}内部也是空的,标记“实现了这个接口的类支持序列化”。序列化是什么意思呢?Java 的序列化是指,将对象转换成以字节序列的形式来表示,这些字节序中包含了对象的字段和方法。序列化后的对象可以被写到数据库、写到文件,也可用于网络传输。
眼睛雪亮的小伙伴可能会注意到,ArrayList 中的关键字段 elementData 使用了 transient 关键字修饰,这个关键字的作用是,让它修饰的字段不被序列化。
这不前后矛盾吗?一个类既然实现了 Serilizable 接口,肯定是想要被序列化的,对吧?那为什么保存关键数据的 elementData 又不想被序列化呢?
这还得从 “ArrayList 是基于数组实现的”开始说起。大家都知道,数组是定长的,就是说,数组一旦声明了,长度(容量)就是固定的,不能像某些东西一样伸缩自如。这就很麻烦,数组一旦装满了,就不能添加新的元素进来了。
ArrayList 不想像数组这样活着,它想能屈能伸,所以它实现了动态扩容。一旦在添加元素的时候,发现容量用满了 s == elementData.length,就按照原来数组的 1.5 倍(oldCapacity >> 1)进行扩容。扩容之后,再将原有的数组复制到新分配的内存地址上 Arrays.copyOf(elementData, newCapacity)。
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}动态扩容意味着什么?大家伙想一下。嗯,还是我来告诉大家答案吧,有点迫不及待。
意味着数组的实际大小可能永远无法被填满的,总有多余出来空置的内存空间。
比如说,默认的数组大小是 10,当添加第 11 个元素的时候,数组的长度扩容了 1.5 倍,也就是 15,意味着还有 4 个内存空间是闲置的,对吧?
序列化的时候,如果把整个数组都序列化的话,是不是就多序列化了 4 个内存空间。当存储的元素数量非常非常多的时候,闲置的空间就非常非常大,序列化耗费的时间就会非常非常多。
于是,ArrayList 做了一个愉快而又聪明的决定,内部提供了两个私有方法 writeObject 和 readObject 来完成序列化和反序列化。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioral compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}从 writeObject 方法的源码中可以看得出,它使用了 ArrayList 的实际大小 size 而不是数组的长度(elementData.length)来作为元素的上限进行序列化。
此处应该有掌声啊!不是为我,为 Java 源码的作者们,他们真的是太厉害了,可以用两个词来形容他们——殚精竭虑、精益求精。
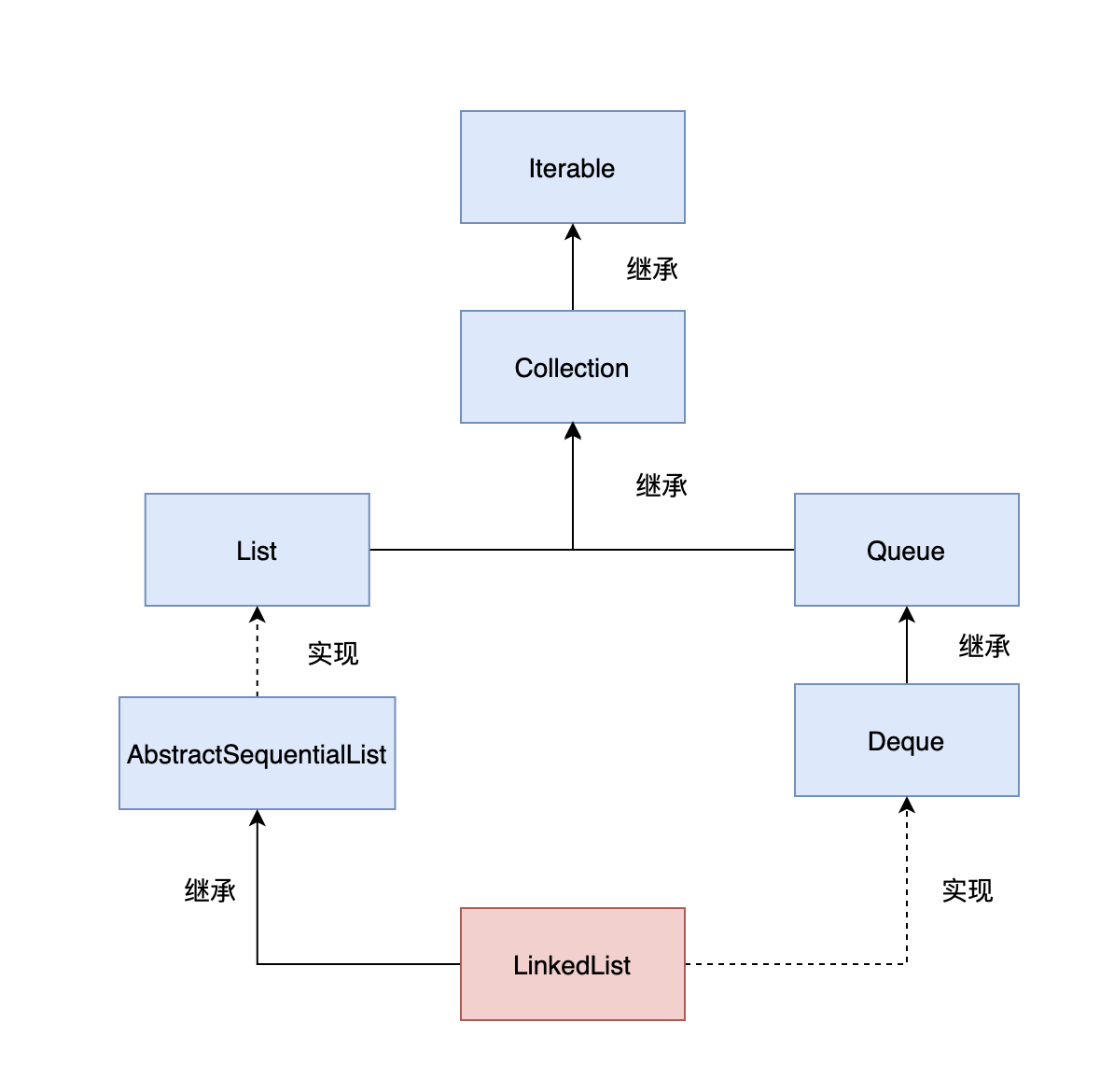
LinkedList 是一个继承自 AbstractSequentialList 的双向链表,因此它也可以被当作堆栈、队列或双端队列进行操作。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
}LinkedList 内部定义了一个 Node 节点,它包含 3 个部分:元素内容 item,前引用 prev 和后引用 next。代码如下所示:
private static class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}LinkedList 还实现了 Cloneable 接口,这表明 LinkedList 是支持拷贝的。
LinkedList 还实现了 Serializable 接口,这表明 LinkedList 是支持序列化的。眼睛雪亮的小伙伴可能又注意到了,LinkedList 中的关键字段 size、first、last 都使用了 transient 关键字修饰,这不又矛盾了吗?到底是想序列化还是不想序列化?
答案是 LinkedList 想按照自己的方式序列化,来看它自己实现的 writeObject() 方法:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out size
s.writeInt(size);
// Write out all elements in the proper order.
for (LinkedList.Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}发现没?LinkedList 在序列化的时候只保留了元素的内容 item,并没有保留元素的前后引用。这样就节省了不少内存空间,对吧?
那有些小伙伴可能就疑惑了,只保留元素内容,不保留前后引用,那反序列化的时候怎么办?
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i = 0; i < size; i++)
linkLast((E)s.readObject());
}
void linkLast(E e) {
final LinkedList.Node<E> l = last;
final LinkedList.Node<E> newNode = new LinkedList.Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}注意 for 循环中的 linkLast() 方法,它可以把链表重新链接起来,这样就恢复了链表序列化之前的顺序。很妙,对吧?
和 ArrayList 相比,LinkedList 没有实现 RandomAccess 接口,这是因为 LinkedList 存储数据的内存地址是不连续的,所以不支持随机访问。
前面我们已经从多个维度了解了 ArrayList 和 LinkedList 的实现原理和各自的特点。那接下来,我们就来聊聊 ArrayList 和 LinkedList 在新增元素时究竟谁快?
ArrayList 新增元素有两种情况,一种是直接将元素添加到数组末尾,一种是将元素插入到指定位置。
添加到数组末尾的源码:
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}很简单,先判断是否需要扩容,然后直接通过索引将元素添加到末尾。
插入到指定位置的源码:
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}先检查插入的位置是否在合理的范围之内,然后判断是否需要扩容,再把该位置以后的元素复制到新添加元素的位置之后,最后通过索引将元素添加到指定的位置。这种情况是非常伤的,性能会比较差。
LinkedList 新增元素也有两种情况,一种是直接将元素添加到队尾,一种是将元素插入到指定位置。
添加到队尾的源码:
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final LinkedList.Node<E> l = last;
final LinkedList.Node<E> newNode = new LinkedList.Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}先将队尾的节点 last 存放到临时变量 l 中(不是说不建议使用 I 作为变量名吗?Java 的作者们明知故犯啊),然后生成新的 Node 节点,并赋给 last,如果 l 为 null,说明是第一次添加,所以 first 为新的节点;否则将新的节点赋给之前 last 的 next。
插入到指定位置的源码:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
LinkedList.Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
LinkedList.Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
LinkedList.Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
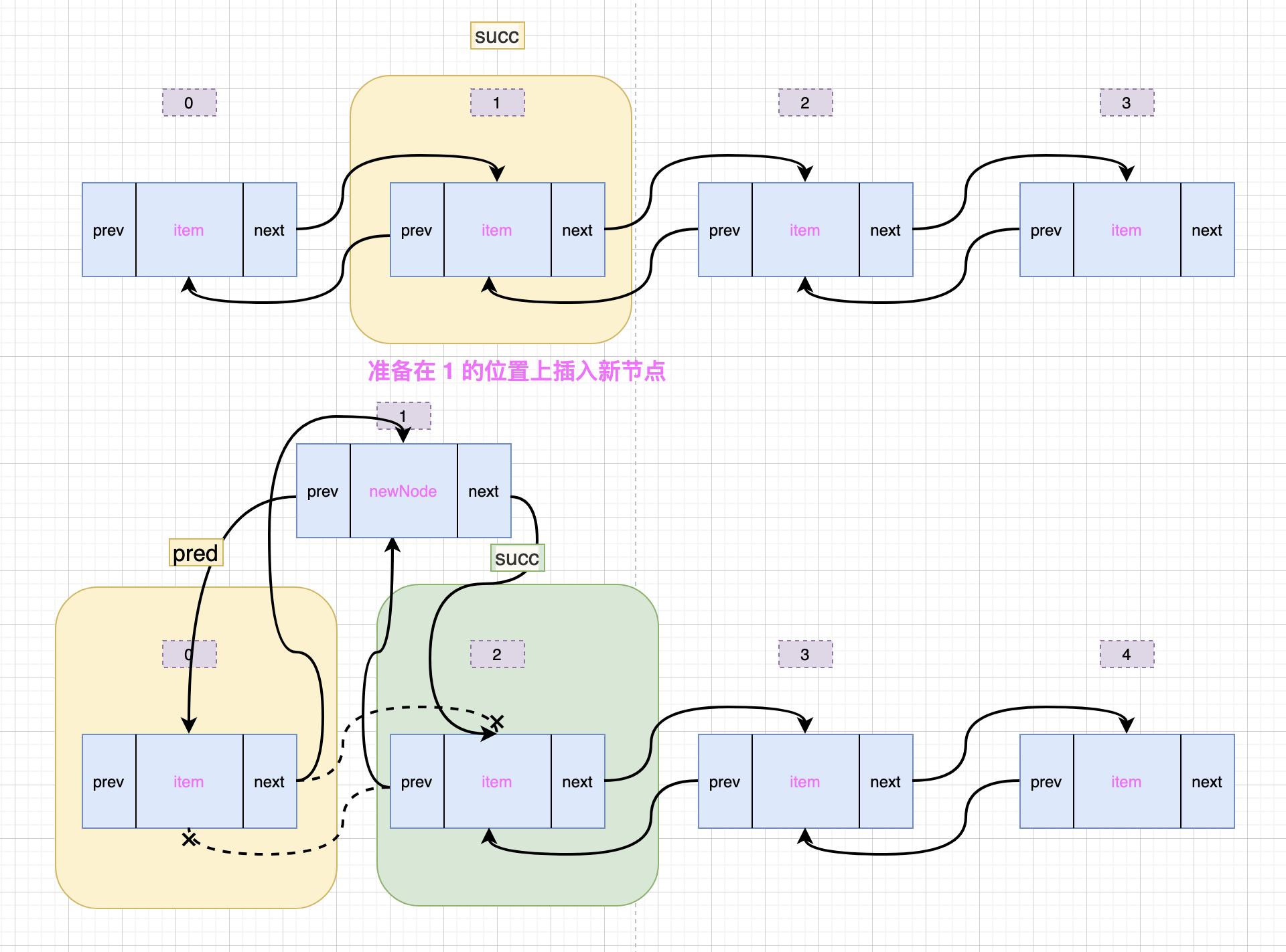
void linkBefore(E e, LinkedList.Node<E> succ) {
// assert succ != null;
final LinkedList.Node<E> pred = succ.prev;
final LinkedList.Node<E> newNode = new LinkedList.Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}先检查插入的位置是否在合理的范围之内,然后判断插入的位置是否是队尾,如果是,添加到队尾;否则执行 linkBefore() 方法。
在执行 linkBefore() 方法之前,会调用 node() 方法查找指定位置上的元素,这一步是需要遍历 LinkedList 的。如果插入的位置靠前前半段,就从队头开始往后找;否则从队尾往前找。也就是说,如果插入的位置越靠近 LinkedList 的中间位置,遍历所花费的时间就越多。
找到指定位置上的元素(succ)之后,就开始执行 linkBefore() 方法了,先将 succ 的前一个节点(prev)存放到临时变量 pred 中,然后生成新的 Node 节点(newNode),并将 succ 的前一个节点变更为 newNode,如果 pred 为 null,说明插入的是队头,所以 first 为新节点;否则将 pred 的后一个节点变更为 newNode。
经过源码分析以后,小伙伴们是不是在想:“好像 ArrayList 在新增元素的时候效率并不一定比 LinkedList 低啊!”
当两者的起始长度是一样的情况下:
- 如果是从集合的头部新增元素,ArrayList 花费的时间应该比 LinkedList 多,因为需要对头部以后的元素进行复制。
public class ArrayListTest {
public static void addFromHeaderTest(int num) {
ArrayList<String> list = new ArrayList<String>(num);
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
list.add(0, i + "沉默王二");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("ArrayList从集合头部位置新增元素花费的时间" + (timeEnd - timeStart));
}
}
/**
* @author 微信搜「沉默王二」,回复关键字 PDF
*/
public class LinkedListTest {
public static void addFromHeaderTest(int num) {
LinkedList<String> list = new LinkedList<String>();
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
list.addFirst(i + "沉默王二");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("LinkedList从集合头部位置新增元素花费的时间" + (timeEnd - timeStart));
}
}num 为 10000,代码实测后的时间如下所示:
ArrayList从集合头部位置新增元素花费的时间595
LinkedList从集合头部位置新增元素花费的时间15
ArrayList 花费的时间比 LinkedList 要多很多。
- 如果是从集合的中间位置新增元素,ArrayList 花费的时间搞不好要比 LinkedList 少,因为 LinkedList 需要遍历。
public class ArrayListTest {
public static void addFromMidTest(int num) {
ArrayList<String> list = new ArrayList<String>(num);
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
int temp = list.size();
list.add(temp / 2, i + "沉默王二");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("ArrayList从集合中间位置新增元素花费的时间" + (timeEnd - timeStart));
}
}
public class LinkedListTest {
public static void addFromMidTest(int num) {
LinkedList<String> list = new LinkedList<String>();
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
int temp = list.size();
list.add(temp / 2, i + "沉默王二");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("LinkedList从集合中间位置新增元素花费的时间" + (timeEnd - timeStart));
}
}num 为 10000,代码实测后的时间如下所示:
ArrayList从集合中间位置新增元素花费的时间16
LinkedList从集合中间位置新增元素花费的时间114
ArrayList 花费的时间比 LinkedList 要少很多很多。
- 如果是从集合的尾部新增元素,ArrayList 花费的时间应该比 LinkedList 少,因为数组是一段连续的内存空间,也不需要复制数组;而链表需要创建新的对象,前后引用也要重新排列。
public class ArrayListTest {
public static void addFromTailTest(int num) {
ArrayList<String> list = new ArrayList<String>(num);
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
list.add(i + "沉默王二");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("ArrayList从集合尾部位置新增元素花费的时间" + (timeEnd - timeStart));
}
}
public class LinkedListTest {
public static void addFromTailTest(int num) {
LinkedList<String> list = new LinkedList<String>();
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
list.add(i + "沉默王二");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("LinkedList从集合尾部位置新增元素花费的时间" + (timeEnd - timeStart));
}
}num 为 10000,代码实测后的时间如下所示:
ArrayList从集合尾部位置新增元素花费的时间69
LinkedList从集合尾部位置新增元素花费的时间193
ArrayList 花费的时间比 LinkedList 要少一些。
这样的结论和预期的是不是不太相符?ArrayList 在添加元素的时候如果不涉及到扩容,性能在两种情况下(中间位置新增元素、尾部新增元素)比 LinkedList 好很多,只有头部新增元素的时候比 LinkedList 差,因为数组复制的原因。
当然了,如果涉及到数组扩容的话,ArrayList 的性能就没那么可观了,因为扩容的时候也要复制数组。
ArrayList 删除元素的时候,有两种方式,一种是直接删除元素(remove(Object)),需要直先遍历数组,找到元素对应的索引;一种是按照索引删除元素(remove(int))。
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
fastRemove(es, i);
return true;
}
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}但从本质上讲,都是一样的,因为它们最后调用的都是 fastRemove(Object, int) 方法。
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}从源码可以看得出,只要删除的不是最后一个元素,都需要数组重组。删除的元素位置越靠前,代价就越大。
LinkedList 删除元素的时候,有四种常用的方式:
remove(int),删除指定位置上的元素
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}先检查索引,再调用 node(int) 方法( 前后半段遍历,和新增元素操作一样)找到节点 Node,然后调用 unlink(Node) 解除节点的前后引用,同时更新前节点的后引用和后节点的前引用:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}remove(Object),直接删除元素
public boolean remove(Object o) {
if (o == null) {
for (LinkedList.Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (LinkedList.Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}也是先前后半段遍历,找到要删除的元素后调用 unlink(Node)。
removeFirst(),删除第一个节点
public E removeFirst() {
final LinkedList.Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(LinkedList.Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final LinkedList.Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}删除第一个节点就不需要遍历了,只需要把第二个节点更新为第一个节点即可。
removeLast(),删除最后一个节点
删除最后一个节点和删除第一个节点类似,只需要把倒数第二个节点更新为最后一个节点即可。
可以看得出,LinkedList 在删除比较靠前和比较靠后的元素时,非常高效,但如果删除的是中间位置的元素,效率就比较低了。
这里就不再做代码测试了,感兴趣的小伙伴可以自己试试,结果和新增元素保持一致:
-
从集合头部删除元素时,ArrayList 花费的时间比 LinkedList 多很多;
-
从集合中间位置删除元素时,ArrayList 花费的时间比 LinkedList 少很多;
-
从集合尾部删除元素时,ArrayList 花费的时间比 LinkedList 少一点。
我本地的统计结果如下所示,小伙伴们可以作为参考:
ArrayList从集合头部位置删除元素花费的时间380
LinkedList从集合头部位置删除元素花费的时间4
ArrayList从集合中间位置删除元素花费的时间381
LinkedList从集合中间位置删除元素花费的时间5922
ArrayList从集合尾部位置删除元素花费的时间8
LinkedList从集合尾部位置删除元素花费的时间12
遍历 ArrayList 找到某个元素的话,通常有两种形式:
get(int),根据索引找元素
public E get(int index) {
Objects.checkIndex(index, size);
return elementData(index);
}由于 ArrayList 是由数组实现的,所以根据索引找元素非常的快,一步到位。
indexOf(Object),根据元素找索引
public int indexOf(Object o) {
return indexOfRange(o, 0, size);
}
int indexOfRange(Object o, int start, int end) {
Object[] es = elementData;
if (o == null) {
for (int i = start; i < end; i++) {
if (es[i] == null) {
return i;
}
}
} else {
for (int i = start; i < end; i++) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}根据元素找索引的话,就需要遍历整个数组了,从头到尾依次找。
遍历 LinkedList 找到某个元素的话,通常也有两种形式:
get(int),找指定位置上的元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}既然需要调用 node(int) 方法,就意味着需要前后半段遍历了。
indexOf(Object),找元素所在的位置
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (LinkedList.Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (LinkedList.Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}需要遍历整个链表,和 ArrayList 的 indexOf() 类似。
那在我们对集合遍历的时候,通常有两种做法,一种是使用 for 循环,一种是使用迭代器(Iterator)。
如果使用的是 for 循环,可想而知 LinkedList 在 get 的时候性能会非常差,因为每一次外层的 for 循环,都要执行一次 node(int) 方法进行前后半段的遍历。
LinkedList.Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
LinkedList.Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
LinkedList.Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}那如果使用的是迭代器呢?
LinkedList<String> list = new LinkedList<String>();
for (Iterator<String> it = list.iterator(); it.hasNext();) {
it.next();
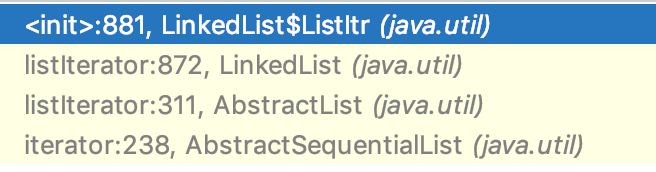
}迭代器只会调用一次 node(int) 方法,在执行 list.iterator() 的时候:先调用 AbstractSequentialList 类的 iterator() 方法,再调用 AbstractList 类的 listIterator() 方法,再调用 LinkedList 类的 listIterator(int) 方法,如下图所示。
最后返回的是 LinkedList 类的内部私有类 ListItr 对象:
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new LinkedList.ListItr(index);
}
private class ListItr implements ListIterator<E> {
private LinkedList.Node<E> lastReturned;
private LinkedList.Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
}执行 ListItr 的构造方法时调用了一次 node(int) 方法,返回第一个节点。在此之后,迭代器就执行 hasNext() 判断有没有下一个,执行 next() 方法下一个节点。
由此,可以得出这样的结论:遍历 LinkedList 的时候,千万不要使用 for 循环,要使用迭代器。
也就是说,for 循环遍历的时候,ArrayList 花费的时间远小于 LinkedList;迭代器遍历的时候,两者性能差不多。
花了两天时间,终于肝完了!相信看完这篇文章后,再有面试官问你 ArrayList 和 LinkedList 有什么区别的话,你一定会胸有成竹地和他扯上半小时了。
最近整理了一份牛逼的学习资料,包括但不限于Java基础部分(JVM、Java集合框架、多线程),还囊括了 数据库、计算机网络、算法与数据结构、设计模式、框架类Spring、Netty、微服务(Dubbo,消息队列) 网关 等等等等……详情戳:可以说是2022年全网最全的学习和找工作的PDF资源了
关注二哥的原创公众号 沉默王二,回复111 即可免费领取。
