Record Linkage in Karma
This page presents the design to support record linkage in Karma. Suppose the user loads a worksheet that contains the names and birthdates of people.

###Invoking Record Linkage
To record link data in the current worksheet with another dataset, the user invokes the Record Linkage command on the class she wants to link.
The command prompts for the dataset to link to.
It does this by going to the karma_models triple store repository to find other datasets that contain data of the same class.
It first finds triple maps for subjects of the same class, and then finds datasets that have been published using the corresponding models (this is going to be a standard reusable component in Karma).
The dialoge will show the following information about each dataset:
- Name of the source
- Number of objects: of the same type as the object the user selected
- Date published
In the initial version the user can only select one dataset.
###Steady State
For now assume that some magic happened, and Karma was able to bootstrap the record-linkage process in some form to produce a worksheet like the following:
Several things happened here:
- Karma added a nested for each record of the class the user selected. This nested table contains a row for each candidate match to the second dataset. At this point some of the candidates may be incorrect, but the system shows several to the user.
- The nested table has a new feature column for data attribute of the source class. The record linkage is based on the model, not on the columns, so it is possible that the second dataset doesn't have the same column names.
Question 1
- Should we create a new worksheet?
- Should we add nested tables to the existing worksheet?
This command creates a JSON document containing the input data for the Information Extraction service.
The JSON document consists of an array of objects.
Each object has a rowHash attribute, a Karma generated hash id for the worksheet row containing the text and a text attribute, which contains the text where we want to run extraction:
[
{
rowHash: "5f0266c4c326",
text: "... Berninghaus attended the Saint Louis School of Fine Arts at night. ..."
}
,
{
rowHash: "c326b9a1ef9e",
text: "Paris was where the 20th century was. ... attributed to Gertrude Stein prove apocryphal ..."
}
,
{
rowHash: "1ef9e39cb78c3",
text: "The daughter of a furniture manufacturer, Anni Albers (Fleischmann) was born in Berlin. ..."
}
]
###Information Extraction Service The Information Extraction Service is a REST service that accepts POST requests to perform information extraction. The body of the POST request is a JSON document such as the one listed above.
TBD: service arguments to control what it extracts and other aspects of its behavior.
The service performs information extraction on the data POSTed to it and returns a new JSON document as shown below.
The document has an array containing an object for each of the objects POSTed to it.
The rowHash is the key to relate the results to the input.
The extractions object contains an attribute for each type of entity extracted.
For each type of entity, there is an array containing all the extractions:
[
{
rowHash: "5f0266c4c326",
extractions:
{
people:
[
{ extraction: "Berninghaus", score: 1.0 },
{ extraction: "Rober Florez", score: 0.9 }
]
,
places:
[
{ extraction: "Saint Louis School of Fine Arts", score: 1.0 }
]
,
dates:
[
{ extraction: "1873", score: 1.0 }
]
}
}
,
{
rowHash: "c326b9a1ef9e",
extractions:
{
people:
[
{ extraction: "Robert Stein", score: 1.0 }
]
,
places:
[
{ extraction: "Paris", score: 1.0 },
{ extraction: "Stockholm", score: 1.0 }
]
,
dates:
[
{ extraction: "20th century", score: 0.7 },
{ extraction: "1921", score: 1.0 },
]
}
}
,
{
rowHash: "1ef9e39cb78c3",
extractions:
{
people:
[
{ extraction: "Anni Albers", score: 1.0 },
{ extraction: "Fleischmann", score: 0.9 },
{ extraction: "Rosenthal", score: 0.8 }
]
,
places:
[
{ extraction: "New York", score: 1.0 }
]
,
dates:
[
{ extraction: "1932", score: 1.0 }
]
}
}
]
###Receiving the Results in Karma
When Karma receives the results, it incorporates them in the worksheet by joining based on rowHash.
This joining operation will be implemented reusing the code that Frank is implementing for adding JSON values to a worksheet.
The results will look as follows:

###Modeling the Results of Extraction
In the first version, the user can model the results of extraction to integrate the results.
In future versions we may be able to model the results automatically.
In general this is not easy.
For example, there are many ontologies for modeling people, so Karma needs to use the one that the user is using in his or her application.
The following is an example of how the user may model the results:
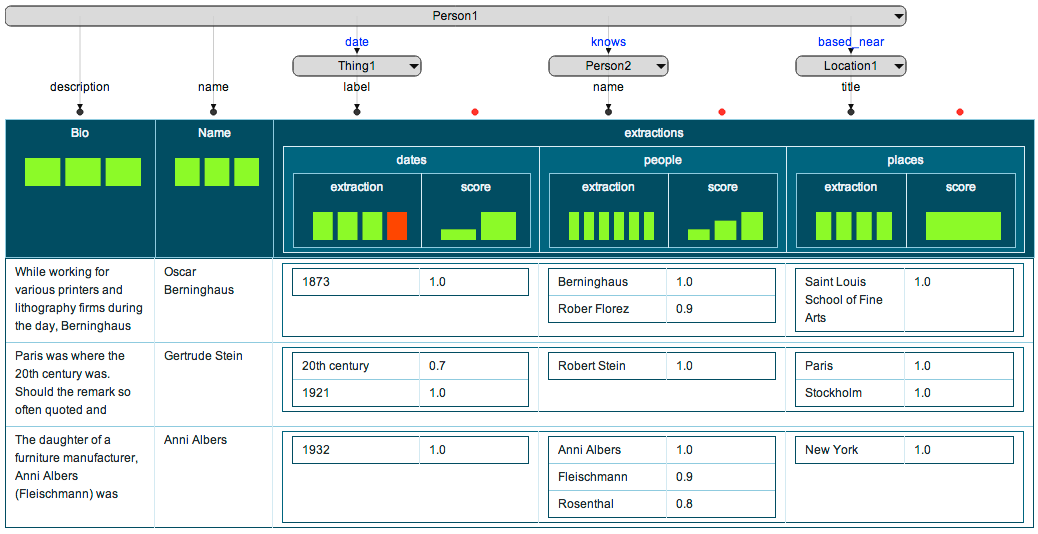
###Curating the Results of Extraction
Information extraction is noisy, so users must be able to curate the results of the extraction process.
Even when the extraction is correct, the user may want to curate the results as the extracted data may be irrelevant.
For example, in the first row the system correctly extracted Berninghaus from the bio, but the user is only interested in references to other people, so wishes to delete this self-reference.
Similarly, the user may want to delete the 20th century extraction as the user is only interested in specific dates.
The curation process consists of two steps:
- Selecting the rows to operate on (this is a topic of another design note)
- Deleting the selected rows (also a topic of another design note)
###Reusing Previous Extraction Results The Information Extraction command will be saved in the command history as part of the R2RML model, and Karma will replay it every time the user applies the model to a worksheet. Extraction is expensive, so we don't want to re-run the extraction process each time a user loads the same worksheet again (we do this all the time when working on an application).
The Information Extraction command should cache the extraction results in a local database.
MongoDB is appropriate as it is a document database optimized to store JSON documents.
The database should be indexed by rowHash to enable quick loading of results.